Индексите на базата данни се използват за подобряване на скоростта на операциите с база данни в таблица с голям брой записи. Индексите на бази данни (както клъстерирани, така и неклъстерни индекси) са доста сходни с индексите на книги по своята функционалност. Индексът на книгите ви позволява да преминете направо към различните теми, обсъждани в книгата. Ако искате да търсите конкретна тема, просто отидете в индекса, намерете номера на страницата, която съдържа темата, която търсите, и след това можете да отидете направо на тази страница. Без индекс ще трябва да търсите в цялата книга.
Индексите на базата данни работят по същия начин. Без индекси ще трябва да търсите в цялата таблица, за да изпълните конкретна операция с база данни. С индексите не е нужно да сканирате всички записи в таблицата. Индексът ви насочва директно към записа, който търсите, което значително намалява времето за изпълнение на заявката ви.
Индексите на SQL Server могат да бъдат разделени на два основни типа:
- Клъстерни индекси
- Неклъстерни индекси
В тази статия ще разгледаме какво представляват клъстерираният и неклъстериран индекс, как се създават и какви са основните разлики между двата. Ще разгледаме също кога да използваме клъстерирани или неклъстерни индекси в SQL Server.
Нека първо започнем с клъстериран индекс.
Клъстериран индекс
Клъстерираният индекс е индекс, който дефинира физическия ред, в който записите на таблицата се съхраняват в база данни. Тъй като може да има само един начин, по който записите се съхраняват физически в таблица на база данни, може да има само един клъстериран индекс на таблица. По подразбиране се създава клъстериран индекс в колона с първичен ключ.
Клъстерни индекси по подразбиране
Нека създадем фиктивна таблица с колона с първичен ключ, за да видим клъстерирания индекс по подразбиране. Изпълнете следния скрипт:
CREATE DATABASE Hospital
CREATE TABLE Patients
(
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
age INT NOT NULL
)
Горният скрипт създава фиктивна база данни Hospital. Базата данни има 4 колони:идентификатор, име, пол, възраст. Колоната с идентификатор е колоната с първичен ключ. Когато горният скрипт се изпълни, автоматично се създава клъстериран индекс в колоната id. За да видите всички индекси в таблица, можете да използвате съхранената процедура „sp_helpindex“.
USE Hospital
EXECUTE sp_helpindex Patients
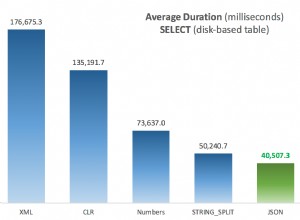
Ето изхода:

Можете да видите името на индекса, описанието и колоната, върху която е създаден индексът. Ако добавите нов запис към таблицата с пациенти, той ще бъде съхранен във възходящ ред на стойността в колоната id. Ако първият запис, който вмъквате в таблицата, има идентификатор от три, записът ще бъде съхранен в третия ред вместо в първия, тъй като клъстерираният индекс поддържа физически ред.
Персонализирани клъстерни индекси
Можете да създадете свои собствени клъстерирани индекси. Въпреки това, преди да можете да направите това, трябва да създадете съществуващия клъстериран индекс. Имаме един клъстериран индекс поради колона с първичен ключ. Ако премахнем ограничението на първичния ключ, клъстерът по подразбиране ще бъде премахнат. Следният скрипт премахва ограничението на първичния ключ.
USE Hospital
ALTER TABLE Patients
DROP CONSTRAINT PK__Patients__3213E83F3DFAFAAD
GO
Следният скрипт създава персонализиран индекс „IX_tblPatient_Age“ в колоната възраст на таблицата с пациенти. Благодарение на този индекс всички записи в таблицата на пациентите ще се съхраняват във възходящ ред на възрастта.
use Hospital
CREATE CLUSTERED INDEX IX_tblPatient_Age
ON Patients(age ASC)
Нека сега добавим няколко фиктивни записа в таблицата на пациентите, за да видим дали те всъщност са вмъкнати във възходящ ред на възрастта:
USE Hospital
INSERT INTO Patients
VALUES
(1, 'Sara', 'Female', 34),
(2, 'Jon', 'Male', 20),
(3, 'Mike', 'Male', 54),
(4, 'Ana', 'Female', 10),
(5, 'Nick', 'Female', 29)
В горния скрипт добавяме 5 фиктивни записа. Обърнете внимание на стойностите за колоната възраст. Те имат произволни стойности и не са в никакъв логически ред. Въпреки това, тъй като сме създали клъстериран индекс, записите всъщност ще бъдат вмъкнати във възходящ ред на стойността в колоната за възраст. Можете да проверите това, като изберете всички записи от таблицата с пациенти.
SELECT * FROM Patients
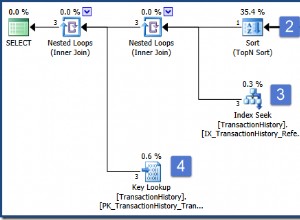
Ето изхода:

Можете да видите, че записите са подредени във възходящ ред на стойностите в колоната възраст.
Неклъстерни индекси
Неклъстериран индекс също се използва за ускоряване на операциите по търсене. За разлика от клъстерирания индекс, неклъстерираният индекс не дефинира физически реда, в който записите се вмъкват в таблица. Всъщност един неклъстериран индекс се съхранява на отделно място от таблицата с данни. Неклъстерираният индекс е като указател на книгата, който се намира отделно от основното съдържание на книгата. Тъй като неклъстерираните индекси се намират на отделно място, може да има множество неклъстерирани индекси на таблица.
За да създадете неклъстериран индекс, трябва да използвате израза „CREATE NONCLUSTERED“. Останалата част от синтаксиса остава същата като синтаксиса за създаване на клъстериран индекс. Следният скрипт създава неклъстериран индекс „IX_tblPatient_Name“, който сортира записите във възходящ ред на името.
use Hospital
CREATE NONCLUSTERED INDEX IX_tblPatient_Name
ON Patients(name ASC)
Горният скрипт ще създаде индекс, който съдържа имената на пациентите и адреса на съответните им записи, както е показано по-долу:
| Име | Адрес на запис |
| Ана | Адрес на запис |
| Jon | Адрес на запис |
| Майк | Адрес на запис |
| Ник | Адрес на запис |
| Сара | Адрес на запис |
Тук „адресът на запис“ във всеки ред е препратка към действителните записи в таблицата за пациентите със съответните имена.
Например, ако искате да извлечете възрастта и пола на пациента на име „Майк“, базата данни първо ще търси „Мик“ в неклъстерирания индекс „IX_tblPatient_Name“ и от неклъстерирания индекс ще извлече действителната препратка към записа и ще използва това, за да върне действителната възраст и пол на пациента на име „Майк“
Тъй като базата данни трябва да извърши две търсения, първо в неклъстерирания индекс и след това в действителната таблица, неклъстерираните индекси могат да бъдат по-бавни за операциите за търсене. Въпреки това, за операции INSERT и UPDATE, неклъстерираните индекси са по-бързи, тъй като редът на записите трябва да се актуализира само в индекса, а не в действителната таблица.
Кога да се използват клъстерни или неклъстерни индекси
Сега, когато знаете разликите между клъстериран и неклъстериран индекс, нека видим различните сценарии за използване на всеки от тях.
1. Брой индекси
Това е доста очевидно. Ако трябва да създадете множество индекси във вашата база данни, изберете неклъстериран индекс, тъй като може да има само един клъстериран индекс.
2. SELECT операции
Ако искате да изберете само стойността на индекса, която се използва за създаване и индексиране, неклъстерните индекси са по-бързи. Например, ако сте създали индекс в колоната „име“ и искате да изберете само името, неклъстерираните индекси бързо ще върнат името.
Въпреки това, ако искате да изберете други стойности на колони, като възраст, пол, използвайки индекса на имената, операцията SELECT ще бъде по-бавна, тъй като първо името ще бъде търсено от индекса, а след това препратката към действителния запис в таблицата ще се използва за търсене възрастта и пола.
От друга страна, с клъстерирани индекси, тъй като всички записи вече са сортирани, операцията SELECT е по-бърза, ако данните се избират от колони, различни от колоната с клъстериран индекс.
3. Операции INSERT/UPDATE
Операциите INSERT и UPDATE са по-бързи с неклъстерирани индекси, тъй като действителните записи не се изискват да бъдат сортирани, когато се извършва операция INSERT или UPDATE. По-скоро само неклъстерираният индекс се нуждае от актуализиране.
4. Дисково пространство
Тъй като неклъстерираните индекси се съхраняват на място, отделно от оригиналната таблица, неклъстерираните индекси консумират допълнително дисково пространство. Ако дисковото пространство е проблем, използвайте клъстериран индекс.
5. Окончателна присъда
Като правило, всяка таблица трябва да има поне един клъстериран индекс, за предпочитане в колоната, която се използва за ИЗБИРАНЕ на записи и съдържа уникални стойности. Колоната с първичен ключ е идеален кандидат за клъстериран индекс.
От друга страна колоните, които често участват в заявки INSERT и UPDATE, трябва да имат неклъстериран индекс, като се предполага, че дисковото пространство не е проблем.