Две сериозни уязвимости в сигурността (кодово име Meltdown и Spectre) бяха разкрити преди няколко седмици. Първоначалните тестове показаха, че въздействието върху производителността от смекчаването (добавено в ядрото) може да бъде до ~30% за някои работни натоварвания, в зависимост от скоростта на системно извикване.
Тези ранни оценки трябваше да бъдат направени бързо и затова се основаваха на ограничени количества тестове. Освен това корекциите в ядрото се развиваха и подобряваха с течение на времето и вече имаме retpoline който трябва да адресира Spectre v2. Тази публикация представя данни от по-задълбочени тестове, като се надяваме да предостави по-надеждни оценки за типичните натоварвания на PostgreSQL.
В сравнение с ранната оценка на корекциите на Meltdown, която Саймън публикува на 10 януари, данните, представени в тази публикация, са по-подробни, но като цяло констатациите за съвпадение, представени в тази публикация.
Тази публикация е фокусирана върху работните натоварвания на PostgreSQL и въпреки че може да бъде полезна за други системи с висока скорост на превключване на системно извикване/контекст, със сигурност не е някак универсално приложима. Ако се интересувате от по-общо обяснение на уязвимостите и оценката на въздействието, Брендън Грег публикува отлична статия за KPTI/KAISER Meltdown Initial Performance Regressions преди няколко дни. Всъщност може да е полезно първо да го прочетете и след това да продължите с тази публикация.
Забележка: Тази публикация не е предназначена да ви обезкуражи да инсталирате поправките, а да ви даде някаква представа какво може да бъде въздействието върху производителността. Трябва да инсталирате всички корекции, така че вашата среда да е защитена, и да използвате тази публикация, за да решите дали може да се наложи да надстроите хардуера и т.н.
Какви тестове ще направим?
Ще разгледаме два обичайни основни типа натоварване – OLTP (малки прости транзакции) и OLAP (сложни заявки, обработващи големи количества данни). Повечето PostgreSQL системи могат да бъдат моделирани като комбинация от тези два типа натоварване.
За OLTP използвахме pgbench, добре познат инструмент за сравнителен анализ, предоставен с PostgreSQL. Тествахме и двете в режим само за четене (-S ) и четене-запис (-N ) режими, с три различни мащаби – вписващи се в споделени_буфери, в RAM и по-големи от RAM.
За случая с OLAP използвахме бенчмарк dbt-3, който е доста близък до TPC-H, с два различни размера на данни – 10 GB, които се вписват в RAM, и 50 GB, което е по-голямо от RAM (като се имат предвид индекси и т.н.).
Всички представени номера идват от сървър с 2x Xeon E5-2620v4, 64GB RAM и Intel SSD 750 (400GB). Системата работеше с Gentoo с ядро 4.15.3, компилирано с GCC 7.3 (необходимо за активиране на пълния retpoline поправи). Същите тестове бяха извършени и на по-стара/по-малка система с i5-2500k CPU, 8GB RAM и 6x Intel S3700 SSD (в RAID-0). Но поведението и заключенията са почти еднакви, така че няма да представяме данните тук.
Както обикновено, пълните скриптове/резултати за двете системи са достъпни в github.
Тази публикация е за въздействието върху производителността на смекчаването, така че нека не се фокусираме върху абсолютни числа, а вместо това да разгледаме производителността спрямо непоправената система (без смекчаването на ядрото). Всички диаграми в секцията OLTP показват
(throughput with patches) / (throughput without patches)
Очакваме числа между 0% и 100%, като по-високите стойности са по-добри (по-ниско въздействие на смекчаването), 100% означава „без въздействие“.
Забележка: Оста Y започва от 75%, за да направи разликите по-видими.
OLTP / само за четене
Първо, нека видим резултатите за pgbench само за четене, изпълняван от тази команда
pgbench -n -c 16 -j 16 -S -T 1800 test
и илюстрирано със следната диаграма:
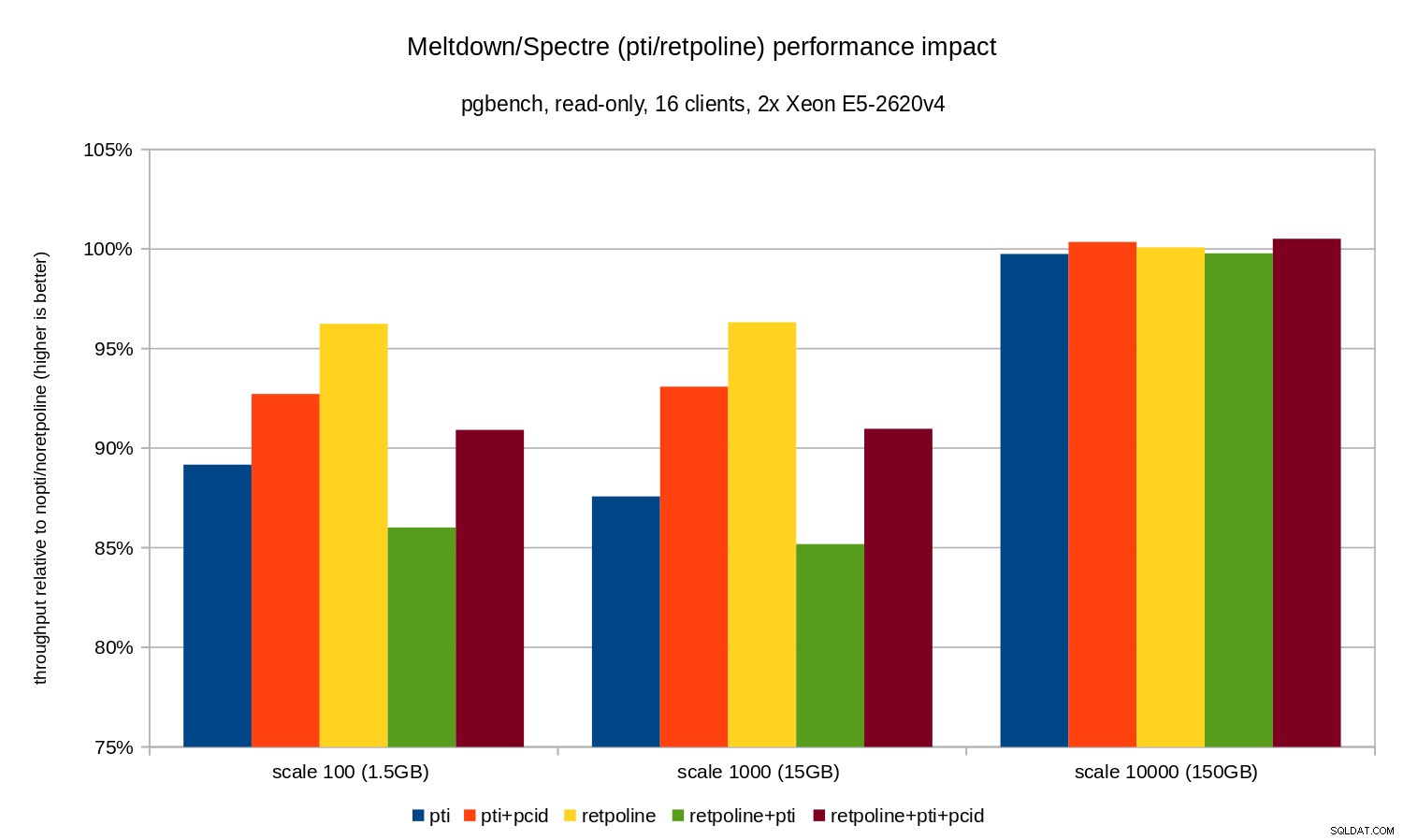
Както можете да видите, въздействието върху производителността на pti за скали, които се вписват в паметта, е приблизително 10-12% и почти не може да се измери, когато работното натоварване стане I/O обвързано. Освен това, регресията е значително намалена (или изчезва напълно), когато pcid е активиран. Това е в съответствие с твърдението, че PCID вече е критична характеристика за производителност/сигурност на x86. Въздействието на retpoline е много по-малък – по-малко от 4% в най-лошия случай, което лесно може да се дължи на шум.
OLTP / четене-запис
Тестовете за четене и запис бяха извършени от pgbench команда, подобна на тази:
pgbench -n -c 16 -j 16 -N -T 3600 test
Продължителността беше достатъчно дълга, за да покрие множество контролни точки и -N беше използван за премахване на споровете за заключване на редове в (малката) таблица с разклонения. Относителната производителност е илюстрирана от тази диаграма:
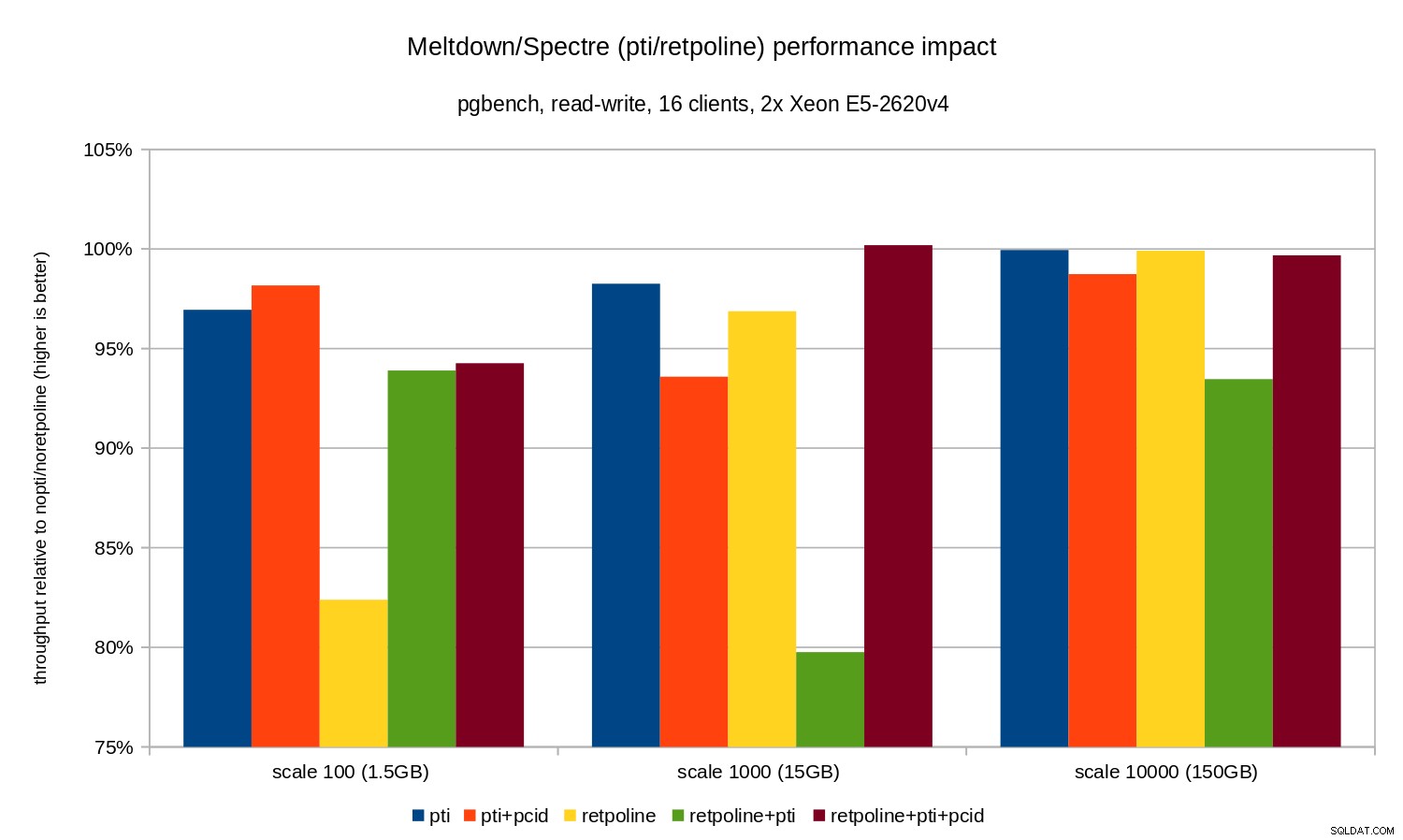
Регресиите са малко по-малки, отколкото в случая само за четене – по-малко от 8% без pcid и по-малко от 3% с pcid активиран. Това е естествена последица от прекарването на повече време в извършване на I/O, докато записвате данни в WAL, промиване на модифицирани буфери по време на контролна точка и т.н.
Има обаче две странни части. Първо, въздействието на retpoline е неочаквано голям (близо до 20%) за мащаб 100 и същото се случи за retpoline+pti по скала 1000. Причините не са съвсем ясни и ще изискват допълнително разследване.
OLAP
Работното натоварване на анализа е моделирано от бенчмарка dbt-3. Първо, нека разгледаме резултатите от мащаба от 10 GB, които се вписват изцяло в RAM (включително всички индекси и т.н.). Подобно на OLTP, ние всъщност не се интересуваме от абсолютни числа, които в този случай биха били продължителност за отделни заявки. Вместо това ще разгледаме забавянето в сравнение с nopti/noretpoline , тоест:
(duration without patches) / (duration with patches)
Ако приемем, че смекчаването води до забавяне, ще получим стойности между 0% и 100%, където 100% означава „без въздействие“. Резултатите изглеждат така:
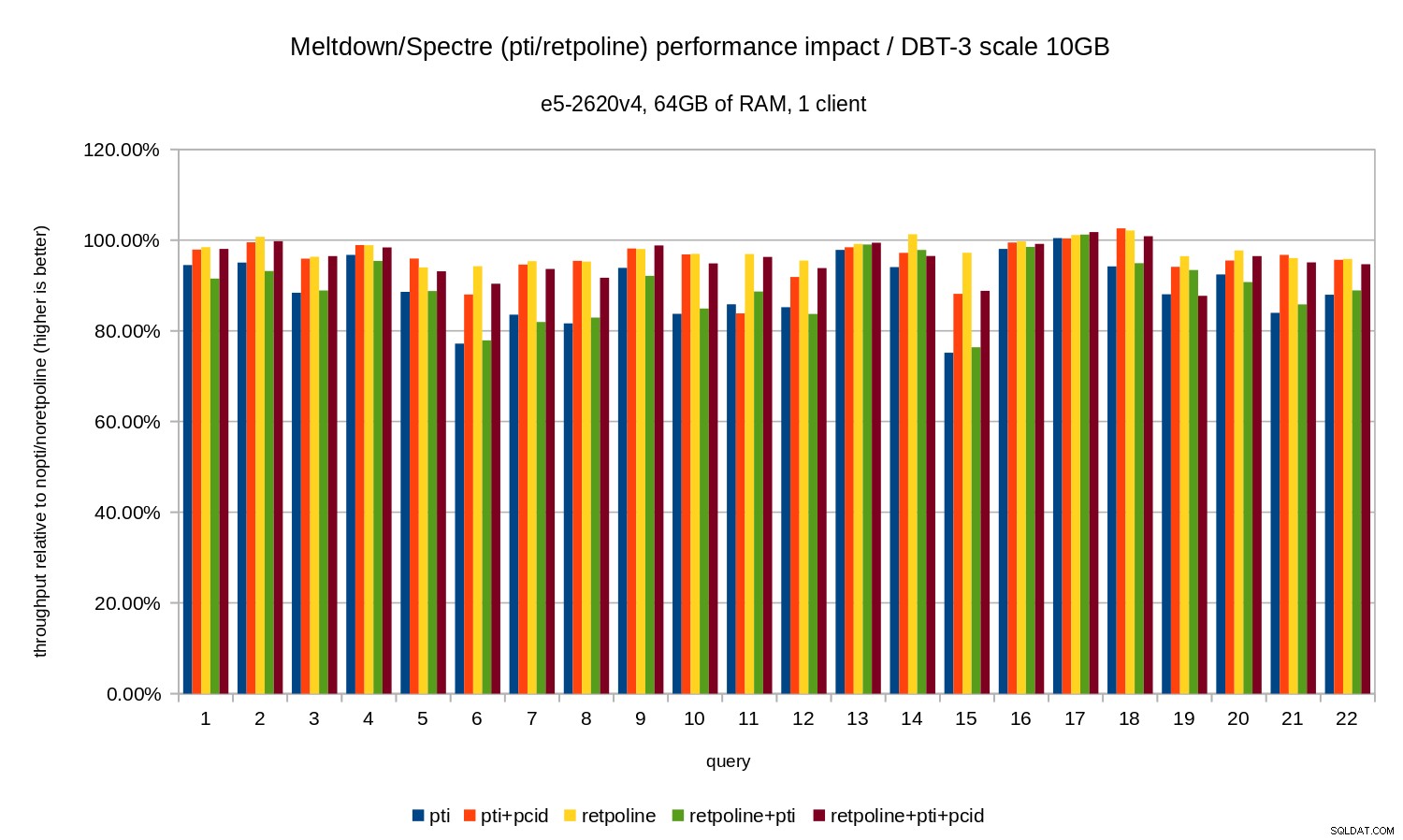
Тоест без pcid регресията обикновено е в диапазона 10-20%, в зависимост от заявката. И с pcid регресията пада до по-малко от 5% (и като цяло близо до 0%). Още веднъж това потвърждава важността на pcid функция.
За набора от 50GB данни (което е около 120GB с всички индекси и т.н.) въздействието изглежда така:
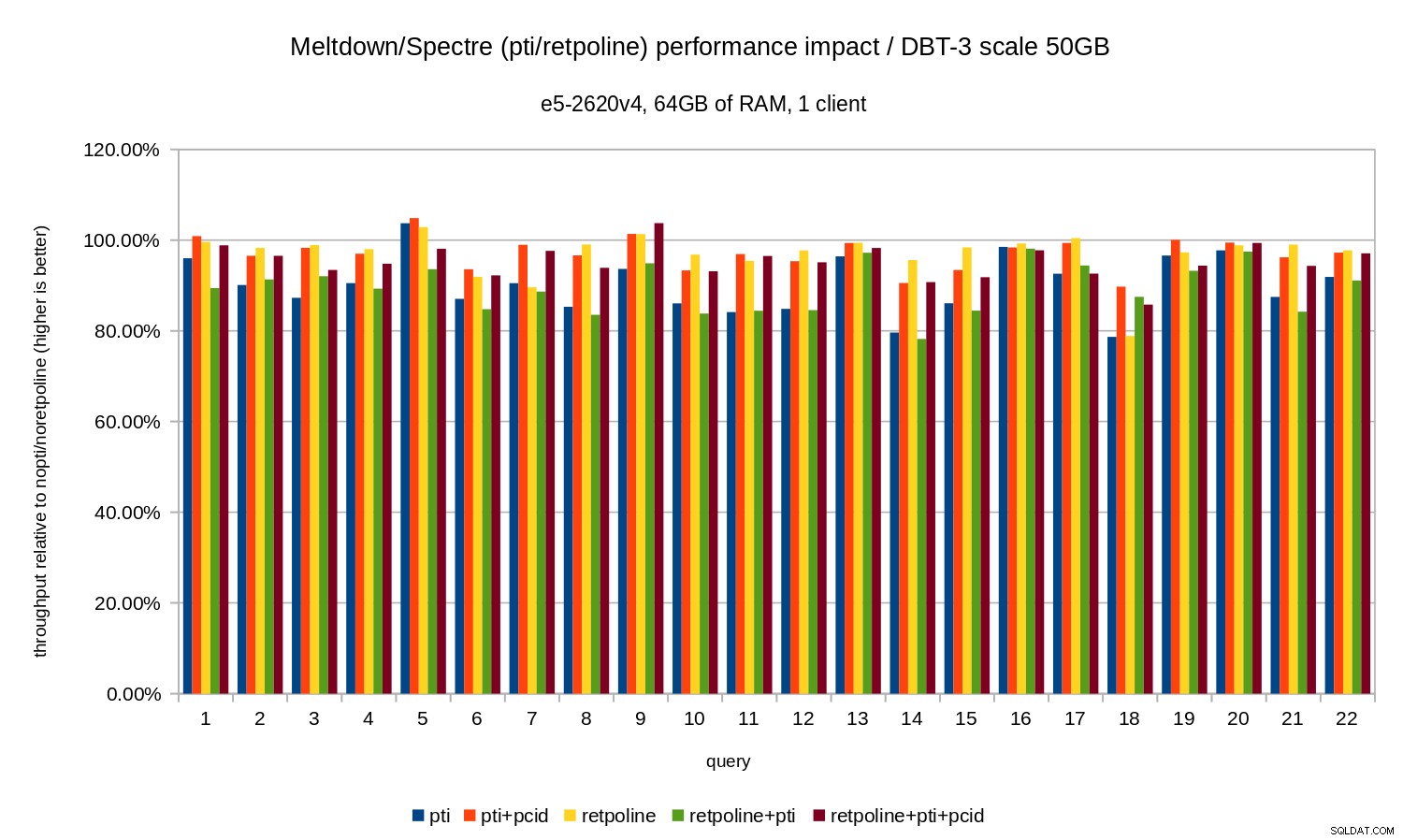
Така че точно както в случая с 10 GB, регресиите са под 20% и pcid значително ги намалява – близо до 0% в повечето случаи.
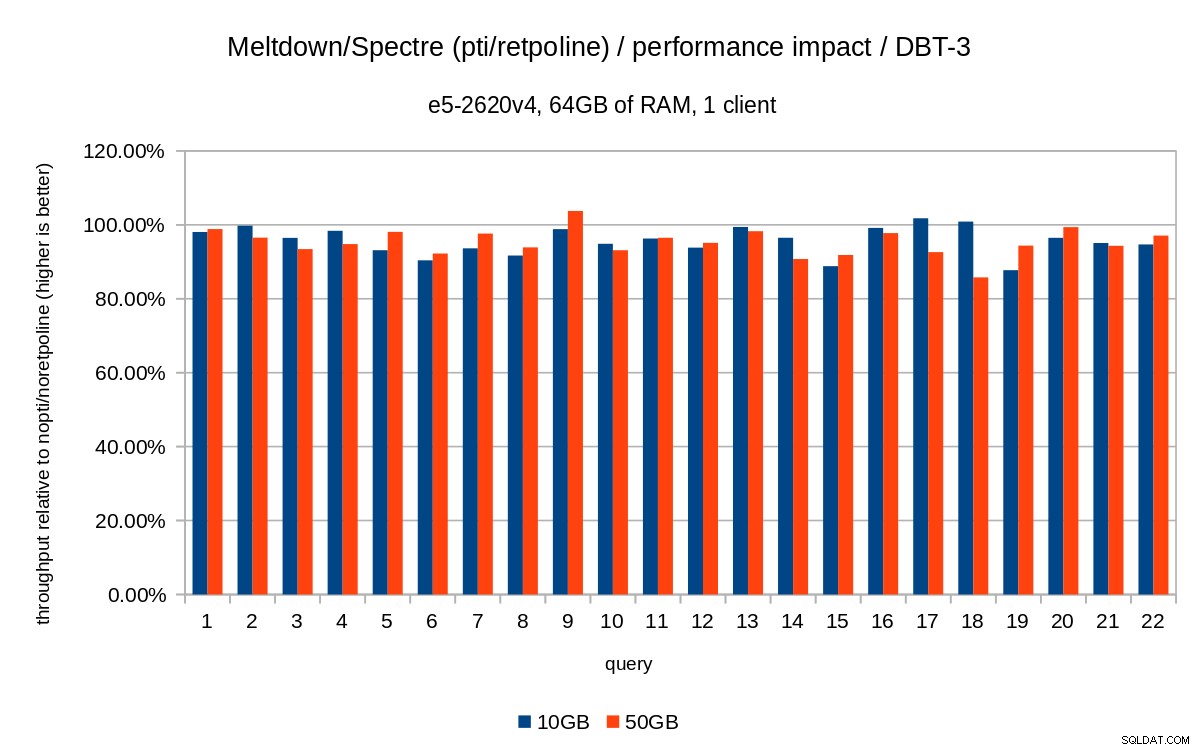
Предишните диаграми са малко претрупани – има 22 заявки и 5 серии от данни, което е малко твърде много за една диаграма. Ето диаграма, показваща въздействието само за трите характеристики (pti , pcid и retpoline ), за двата размера на набора от данни.
Заключение
За да обобщим накратко резултатите:
retpolineима много малко влияние върху производителността- OLTP – регресията е приблизително 10-15% без
pcid, и около 1-5% сpcid. - OLAP – регресията е до 20% без
pcid, и около 1-5% сpcid. - За натоварвания, свързани с I/O (напр. OLTP с най-голям набор от данни), Meltdown има незначително въздействие.
Въздействието изглежда е много по-ниско от първоначалните оценки, които предполагат (30%), поне за тестваните работни натоварвания. Много системи работят на 70-80% CPU в пиковите периоди, а тези 30% биха наситили напълно капацитета на CPU. Но на практика ефектът изглежда е под 5%, поне когато pcid се използва опцията.
Не ме разбирайте погрешно, 5% спад все още е сериозна регресия. Това със сигурност е нещо, което би ни интересувало по време на разработката на PostgreSQL, напр. при оценка на въздействието на предложените пластири. Но това е нещо, с което съществуващите системи трябва да се справят добре – ако 5% увеличение на използването на процесора превъзхожда системата ви, имате проблеми дори без Meltdown/Spectre.
Ясно е, че това не е краят на поправките на Meltdown/Spectre. Разработчиците на ядрото все още работят върху подобряването на защитите и добавянето на нови, а Intel и други производители на процесори работят върху актуализации на микрокодове. И не е като да знаем за всички възможни варианти на уязвимостите, тъй като изследователите успяха да намерят нови варианти на атаките.
Така че предстои още и ще бъде интересно да видим какво ще бъде въздействието върху производителността.