Значението на отказването
Отказът е една от най-важните практики за управление на база данни. Полезно е не само при управление на големи бази данни в производството, но и ако искате да сте сигурни, че вашата система е винаги достъпна, когато осъществявате достъп до нея – особено на ниво приложение.
Преди да може да се осъществи отказ, екземплярите на вашата база данни трябва да отговарят на определени изисквания. Тези изисквания всъщност са много важни за високата наличност. Едно от изискванията, на които трябва да отговарят вашите екземпляри на база данни, е излишък. Резервирането позволява преминаването при отказ да продължи, при което дублирането е настроено да има кандидат за отказ, който може да бъде реплика (вторичен) възел или от набор от реплики, действащи като възли в режим на готовност или горещ резерв. Кандидатът се избира ръчно или автоматично въз основа на най-модерния или актуален възел. Обикновено бихте искали реплика за горещ режим на готовност, тъй като тя може да спаси вашата база данни от изтегляне на индекси от диск, тъй като режимът на гореща готовност често попълва индекси в буферния пул на базата данни.
Отказът е терминът, използван за описване на възникнал процес на възстановяване. Преди процеса на възстановяване това се случва, когато основен (или главен) възел на базата данни се повреди след срив, след природни бедствия, след хардуерен отказ или може да е претърпял мрежово разделяне; това са най-честите случаи, поради които може да се осъществи отказ. Процесът на възстановяване обикновено протича автоматично и след това търси най-желания и актуален вторичен (реплика), както е посочено по-горе.
Разширено преодоляване на отказ
Въпреки че процесът на възстановяване по време на отказ е автоматичен, има определени случаи, когато не е необходимо да се автоматизира процесът и трябва да се наложи ръчен процес. Сложността често е основното съображение, свързано с технологиите, включващи целия стек на вашата база данни – автоматичното преминаване на отказ може да се смесва и с ръчно преминаване при отказ.
В повечето ежедневни съображения относно управлението на бази данни, по-голямата част от опасенията, свързани с автоматичното преминаване при отказ, наистина не са тривиални. Често е полезно да внедрите и настроите автоматично преминаване при отказ в случай, че възникнат проблеми. Въпреки че това звучи обещаващо, тъй като обхваща сложностите, идват усъвършенстваните механизми за преодоляване на отказ и това включва "предварителни" събития и "след" събития, които са свързани като куки в софтуер или технология за отказване.
Тези предварителни и последващи събития включват или проверки, или определени действия, които трябва да извършат, преди най-накрая да продължи с преодоляването на отказ, и след като преминаването на отказ е извършено, някои почиствания, за да се уверим, че превключването на отказ най-накрая е успешно един. За щастие има налични инструменти, които позволяват не само автоматично превключване при отказ, но разполагат и с възможност за прилагане на куки преди и след скриптове.
В този блог ще използваме ClusterControl (CC) автоматично превключване при отказ и ще обясним как да използвате куките за пред и след скриптове и за кой клъстер се прилагат.
Отказ при репликация на ClusterControl
Механизмът за преодоляване на отказ на ClusterControl е ефективно приложим при асинхронна репликация, която е приложима за варианти на MySQL (MySQL/Percona Server/MariaDB). Приложим е и за PostgreSQL/TimescaleDB клъстери - ClusterControl поддържа поточно репликация. Клъстерите MongoDB и Galera имат собствен механизъм за автоматично преминаване при отказ, вграден в собствената си технология за база данни. Прочетете повече за това как ClusterControl извършва автоматично възстановяване и преодоляване на базата данни.
Отказът на ClusterControl не работи, освен ако възстановяването на възел и клъстер (автоматичното възстановяване не е активирано). Това означава, че тези бутони трябва да са зелени.

В документацията се посочва, че тези опции за конфигурация могат да се използват и за активиране / деактивирайте следното:
| enable_cluster_autorecovery= |
|
| enable_node_autorecovery= |
|
$ systemctl restart cmon
За този блог ние се фокусираме основно върху това как да използваме куките за скриптове преди/след, което по същество е голямо предимство за разширено отказване при репликация.
Поддръжка на репликация при отказ на клъстер преди/след скрипт
Както споменахме по-рано, вариантите на MySQL, които използват асинхронна (включително полусинхронна) репликация и поточно репликация за PostgreSQL/TimescaleDB поддържат този механизъм. ClusterControl има следните опции за конфигурация, които могат да се използват за куки преди и след скриптове. По принцип тези опции за конфигурация могат да бъдат зададени чрез техните конфигурационни файлове или могат да бъдат зададени чрез уеб потребителския интерфейс (ще се заемем с това по-късно).
В нашата документация се посочва, че това са следните опции за конфигурация, които могат да променят механизма за преодоляване на отказ чрез използване на кукичките преди/след скрипт:
| replication_pre_failover_script= |
|
| replication_post_failover_script= |
|
| replication_post_unsuccessful_failover_script= |
|
Технически, след като зададете следните опции за конфигурация във вашия /etc/cmon.d/cmon_
$ systemctl restart cmonОсвен това можете да зададете опциите за конфигурация, като отидете на <изберете вашия клъстер> → Настройки → Конфигурация по време на изпълнение. Вижте екранната снимка по-долу:
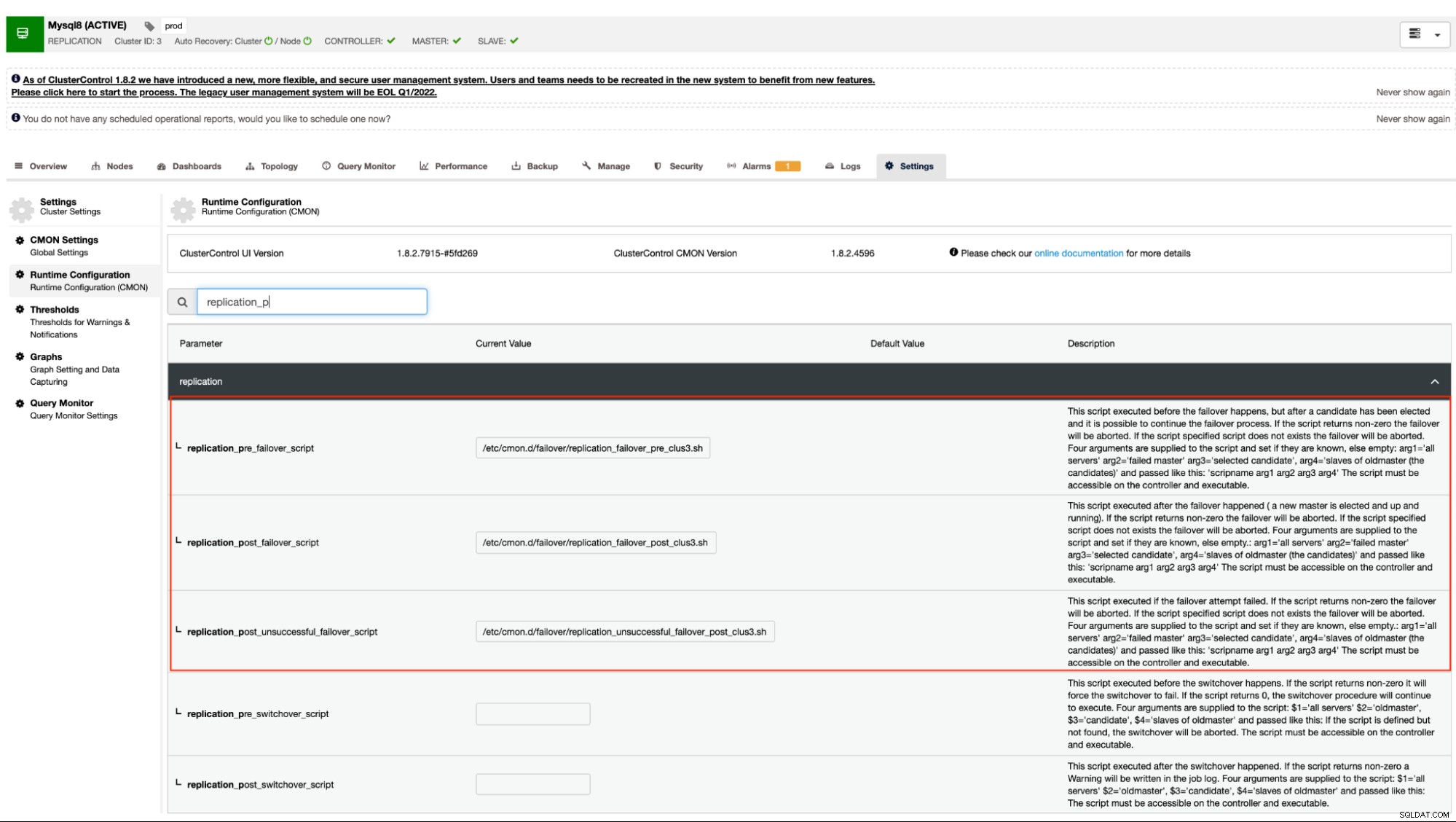
Този подход все пак ще изисква рестартиране на услугата cmon, преди да може да отрази направени промени за тези конфигурационни опции за куки преди/след скриптове.
Пример за куки преди/след скриптове
В идеалния случай куките за пред/след скриптове са предназначени, когато имате нужда от разширен отказ, за който ClusterControl не може да управлява сложността на настройката на вашата база данни. Например, ако използвате различни центрове за данни със засилена сигурност и искате да определите дали предупреждението за недостъпна мрежа не е фалшиво положителна аларма. Той трябва да провери дали основният и подчиненият могат да достигнат един до друг и обратно и може също да достигне от възлите на базата данни, отиващи към хоста на ClusterControl.
Нека направим това в нашия пример и да покажем как можете да се възползвате от него.
Подробности за сървъра и скриптовете
В този пример използвам клъстер за репликация на MariaDB само с основен и реплика. Управлява се от ClusterControl за управление на отказ.
ClusterControl =192.168.40.110
основен (debnode5) =192.168.30.50
реплика (debnode9) =192.168.30.90
В основния възел създайте скрипта, както е посочено по-долу,
example@sqldat.com:~# cat /opt/pre_failover.sh
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat >> /tmp/debnode5.tmp"Уверете се, че /opt/pre_failover.sh е изпълним, т.е.
$ chmod +x /opt/pre_failover.shСлед това използвайте този скрипт, за да участвате чрез cron. В този пример създадох файл /etc/cron.d/ccfailover и има следното съдържание:
example@sqldat.com:~# cat /etc/cron.d/ccfailover
#!/bin/bash
* * * * * vagrant /opt/pre_failover.shВ репликата си просто използвайте следните стъпки, които направихме за основния, освен да промените името на хоста. Вижте следното от това, което имам по-долу в моята реплика:
example@sqldat.com:~# tail -n+1 /etc/cron.d/ccfailover /opt/pre_failover.sh
==> /etc/cron.d/ccfailover <==
#!/bin/bash
* * * * * vagrant /opt/pre_failover.sh
==> /opt/pre_failover.sh <==
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat > /tmp/debnode9.tmp"и се уверете, че скриптът, извикан в нашия cron, е изпълним,
example@sqldat.com:~# ls -alth /opt/pre_failover.sh
-rwxr-xr-x 1 root root 104 Jun 14 05:09 /opt/pre_failover.shClusterControl пред/последващи скриптове
В тази демонстрация моят cluster_id е 3. Както беше посочено по-рано в нашата документация, той изисква тези скриптове да се намират в хоста на нашия CC контролер. Така че в моя /etc/cmon.d/cmon_3.cnf имам следното:
[example@sqldat.com cmon.d]# tail -n3 /etc/cmon.d/cmon_3.cnf
replication_pre_failover_script = /etc/cmon.d/failover/replication_failover_pre_clus3.sh
replication_post_failover_script = /etc/cmon.d/failover/replication_failover_post_clus3.sh
replication_post_unsuccessful_failover_script = /etc/cmon.d/failover/replication_unsuccessful_failover_post_clus3.shКато има предвид, че следният "предварителен" скрипт за преодоляване на отказ определя дали и двата възела са успели да достигнат до хоста на CC контролера. Вижте следното:
[example@sqldat.com cmon.d]# tail -n+1 /etc/cmon.d/failover/replication_failover_pre_clus3.sh
#!/bin/bash
arg1=$1
debnode5_tstamp=$(tail /tmp/debnode5.tmp)
debnode9_tstamp=$(tail /tmp/debnode9.tmp)
cc_tstamp=$(date -u +%s)
diff_debnode5=$(expr $cc_tstamp - $debnode5_tstamp)
diff_debnode9=$(expr $cc_tstamp - $debnode5_tstamp)
if [[ "$diff_debnode5" -le 60 && "$diff_debnode9" -le 60 ]]; then
echo "failover cannot proceed. It's just a false alarm. Checkout the firewall in your CC host";
exit 1;
elif [[ "$diff_debnode5" -gt 60 || "$diff_debnode9" -gt 60 ]]; then
echo "Either both nodes ($arg1) or one of them were not able to connect the CC host. One can be unreachable. Failover proceed!";
exit 0;
else
echo "false alarm. Failover discarded!"
exit 1;
fi
Whereas my post scripts just simply echoes and redirects the output to a file, just for the test.
[example@sqldat.com failover]# tail -n+1 replication_*_post*3.sh
==> replication_failover_post_clus3.sh <==
#!/bin/bash
echo "post failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_failover_script_cid3.txt
==> replication_unsuccessful_failover_post_clus3.sh <==
#!/bin/bash
echo "post unsuccessful failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_unsuccessful_failover_script_cid3.txt
Демонстрация на отказ
Сега нека се опитаме да симулираме прекъсване на мрежата на основния възел и да видим как ще реагира. В моя основен възел премахвам мрежовия интерфейс, който се използва за комуникация с репликата и CC контролера.
example@sqldat.com:~# ip link set enp0s8 downПо време на първия опит за преодоляване на отказ, CC успя да изпълни моя предварителен скрипт, който се намира на адрес /etc/cmon.d/failover/replication_failover_pre_clus3.sh. Вижте по-долу как работи:
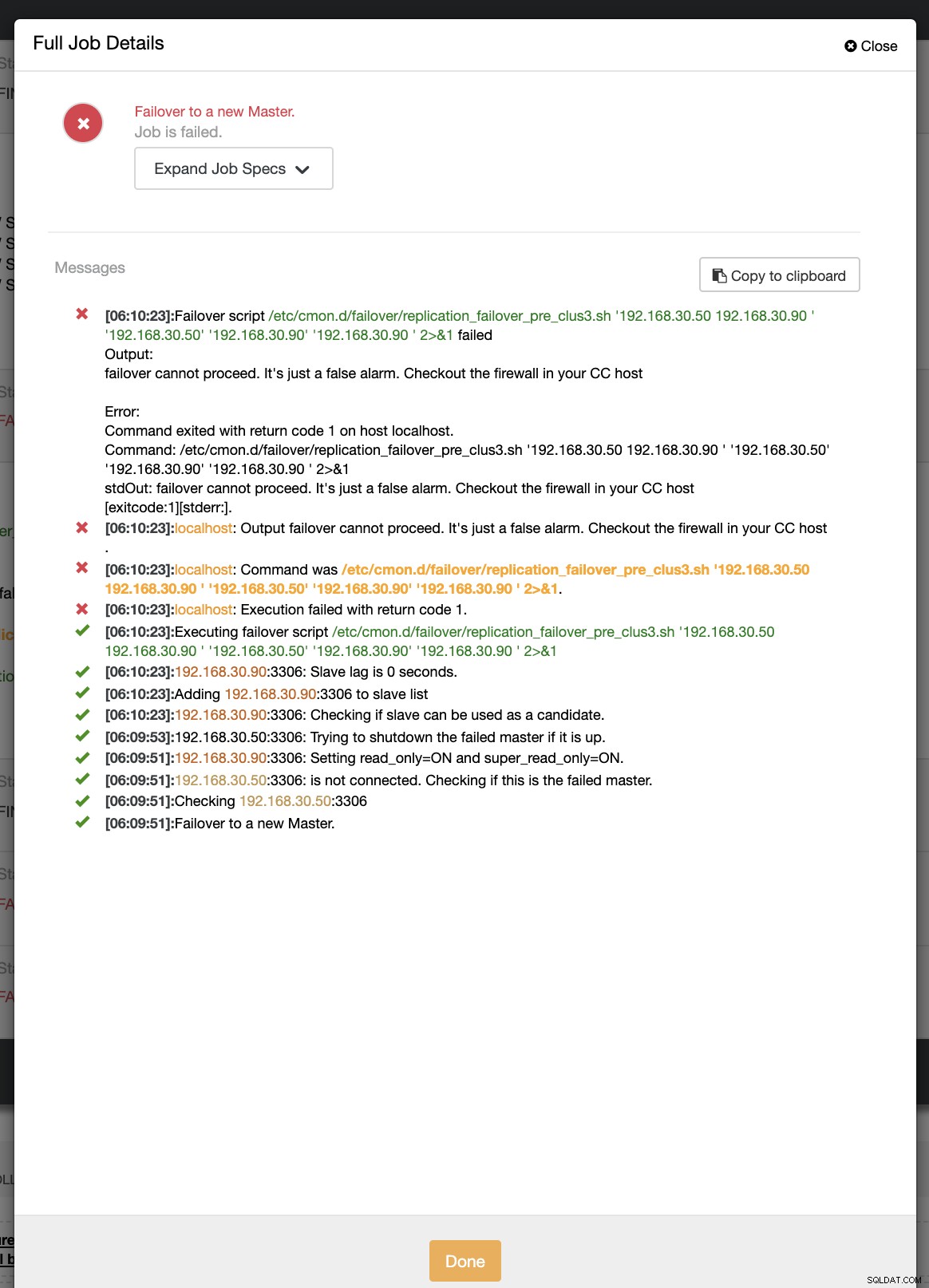
Очевидно е неуспешно, тъй като времевата марка, която е регистрирана, все още не е повече от минута или само преди няколко секунди основният все още може да се свърже с CC контролера. Очевидно това не е идеалният подход, когато имате работа с реален сценарий. Въпреки това, ClusterControl успя да извика и изпълни скрипта перфектно, както се очакваше. Сега, какво ще кажете, ако наистина достигне повече от минута (т.е.> 60 секунди)?
При втория ни опит за превключване при отказ, тъй като времевата марка достига повече от 60 секунди, тогава се счита, че е наистина положителна и това означава, че трябва да преминем към отказ, както е предвидено. CC успя да го изпълни перфектно и дори да изпълни постскрипта по предназначение. Това може да се види в дневника за работа. Вижте екранната снимка по-долу:
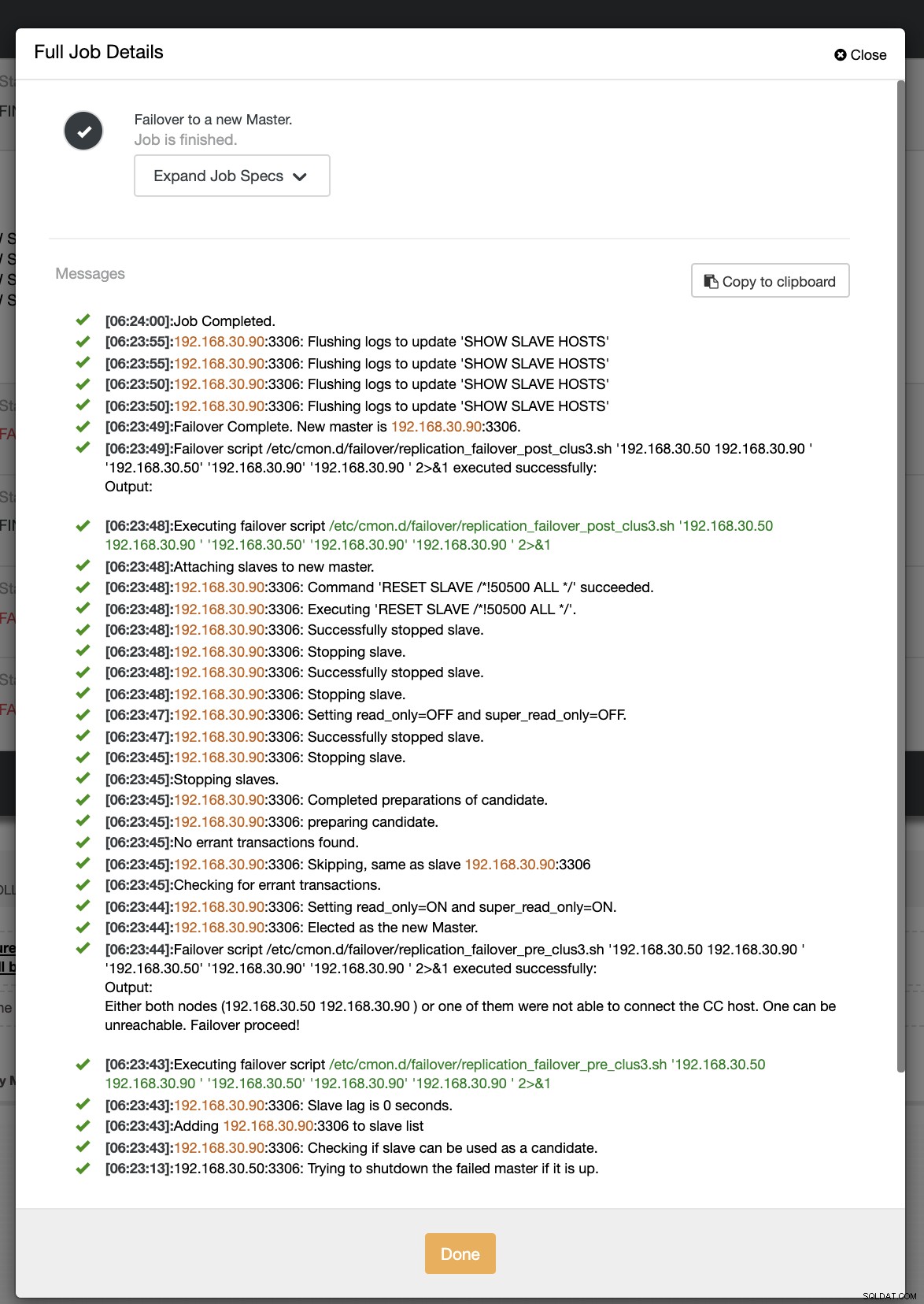
Проверка дали моят скрипт за публикация е стартиран, той успя да създаде дневника файл в директорията CC /tmp, както се очаква,
[example@sqldat.com tmp]# cat /tmp/post_failover_script_cid3.txtскрипт за преодоляване на отказ на клъстер 3 с аргументи:192.168.30.50 192.168.30.90 192.168.30.50 192.168.30.90 192.168.30.90.90.
Сега топологията ми беше променена и преодоляването на отказ беше успешно!
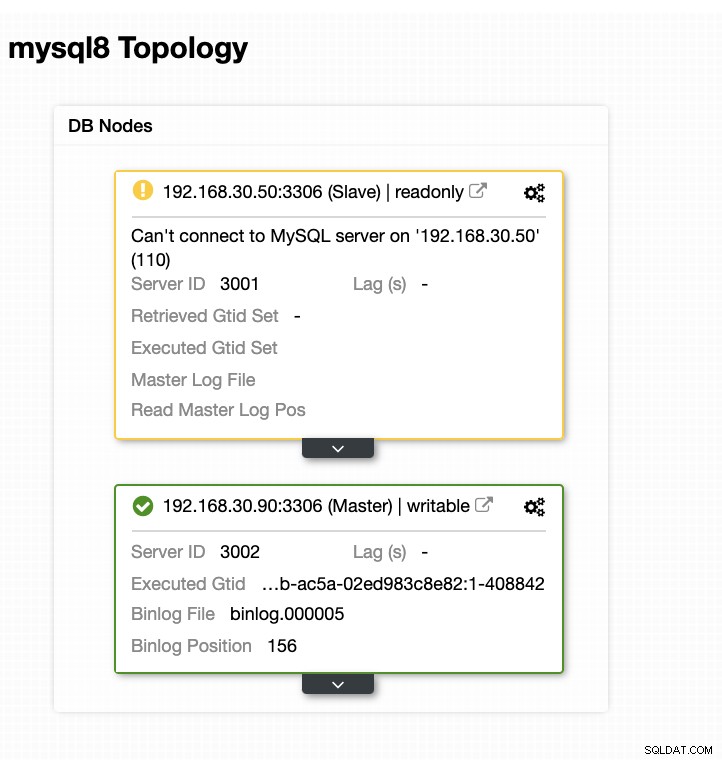
Заключение
За всяка сложна настройка на базата данни, която може да имате, когато се изисква разширено преодоляване на срив, скриптовете преди/последването могат да бъдат много полезни, за да направят нещата постижими. Тъй като ClusterControl поддържа тези функции, ние демонстрирахме колко мощен и полезен е той. Дори и с неговите ограничения, винаги има начини да направите нещата постижими и полезни, особено в производствена среда.