В предишната част тествахме времето за архивиране и ефективността на компресията за различни нива и методи на компресиране на архивиране. В този блог ще продължим усилията си и ще говорим за още настройки, които вероятно повечето от потребителите не променят наистина, но може да имат видим ефект върху процеса на архивиране.
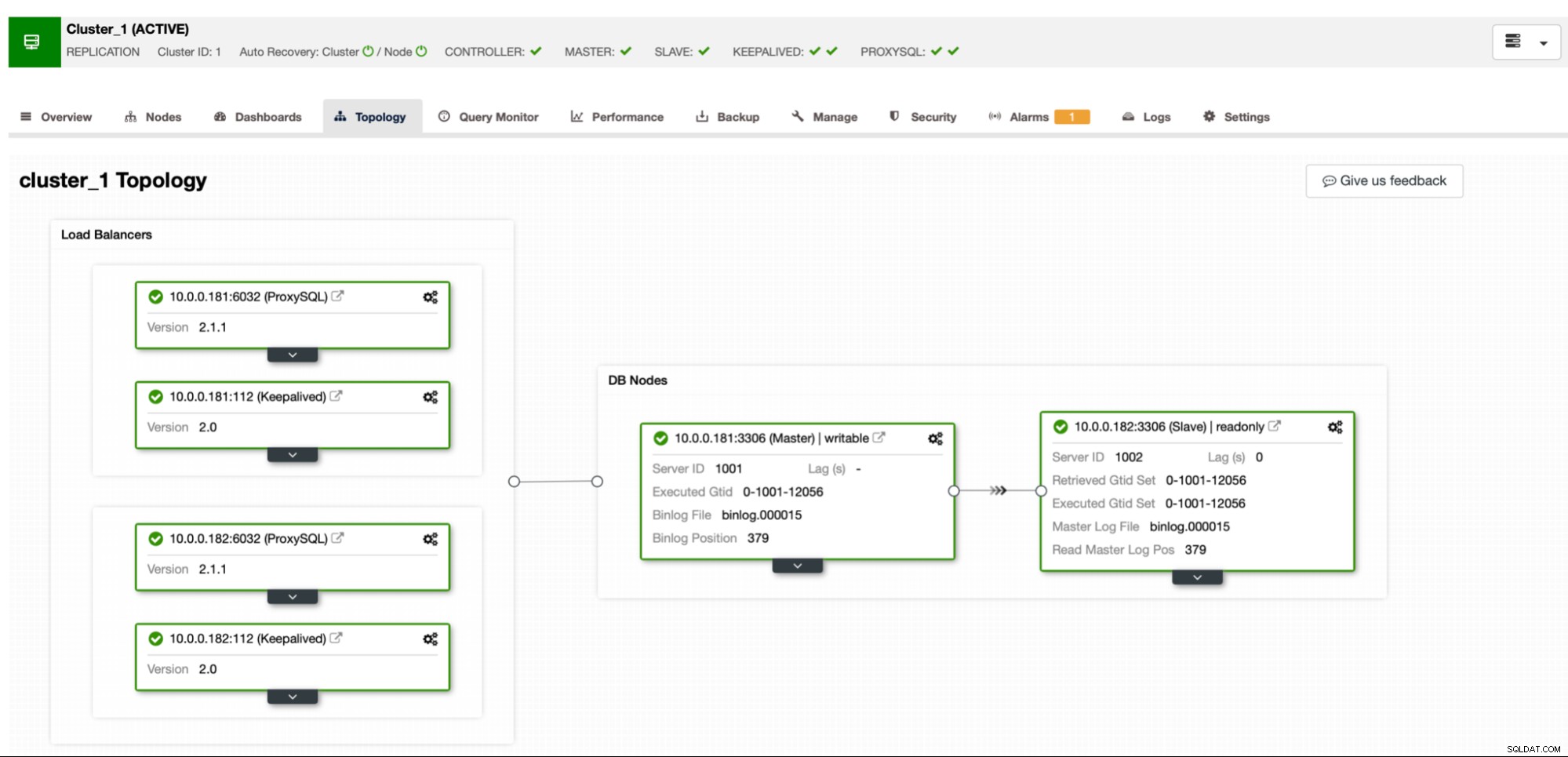
Настройката е същата като в предишната част:ще използваме MariaDB главен-подчинен клъстер за репликация с ProxySQL и Keepalived.
Генерирахме 7,6 GB данни с помощта на sysbench:
sysbench /root/sysbench/src/lua/oltp_read_write.lua --threads=4 --mysql-host=10.0.0.111 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=6033 --tables=32 --table-size=1000000 prepareИзползване на PIGZ
Този път ще активираме Използване на PIGZ за паралелен gzip за нашите архиви. Както и преди, ще тестваме всяко ниво на компресия, за да видим как се представя.
Ние съхраняваме резервното копие локално в потребителския модел, екземплярът е конфигуриран с 4 vCPU.
Резултатът е очакван. Процесът на архивиране беше значително по-бърз, отколкото когато използвахме само едно ядро на процесора. Размерът на архива остава почти същият, няма реална причина той да се променя значително. Ясно е, че използването на pigz подобрява времето за архивиране. Въпреки това има тъмна страна на използването на паралелен gzip и това е използването на процесора:
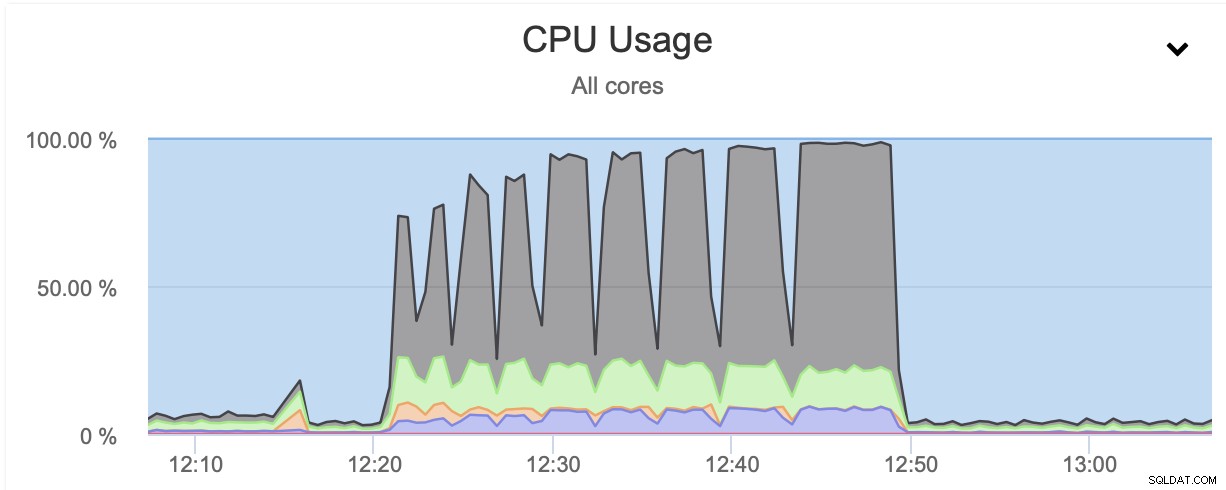
Както можете да видите, използването на процесора скача до небето и достига почти 100% за по-високи нива на компресия. Увеличаването на използването на CPU на сървъра на базата данни не е непременно най-добрата идея, тъй като обикновено искаме CPU да бъде наличен за базата данни. От друга страна, ако случайно имаме реплика, която е предназначена за вземане на архиви и, да кажем, по-тежки заявки - възел, който не се използва за обслужване на OLTP тип трафик, можем да активираме паралелен gzip, за да намалим значително архивирането време. Както може ясно да се види, това не е опция за всеки, но определено е нещо, което можете да намерите полезно в някои конкретни сценарии. Само имайте предвид, че използването на процесора е нещо, което трябва да проследите, тъй като ще повлияе на латентността на заявките и, както чрез него, ще повлияе на потребителското изживяване – нещо, което винаги трябва да вземем предвид, когато работим с базите данни.
Нишки за паралелно копиране на Xtrabackup
Друга настройка, която искаме да подчертаем, е Xtrabackup Parallel Copy Threads. За да разберем какво представлява, нека поговорим малко за начина, по който Xtrabackup (или MariaBackup) работи. Накратко, тези инструменти изпълняват две действия едновременно. Те копират данните, физическите файлове, от сървъра на базата данни към местоположението за архивиране, докато наблюдават регистрационните файлове за повторение на InnoDB за всякакви актуализации. Архивът се състои от файловете и записа на всички промени в InnoDB, настъпили по време на процеса на архивиране. Това, със заключвания на архивиране или FLUSH TABLES WITH READ LOCK, позволява да се създаде резервно копие, което е последователно в момента, когато трансферът на данни е завършен. Нишките за паралелно копиране на Xtrabackup определят броя на нишките, които ще извършат трансфера на данни. Ако го зададем на 1, един файл ще бъде копиран едновременно. Ако го зададем на 8, теоретично могат да се прехвърлят до 8 файла наведнъж. Разбира се, трябва да има достатъчно бързо съхранение, за да се възползвате действително от такава настройка. Ще извършим няколко теста, променяйки нишките за паралелно копиране на Xtrabackup от 1 до 2 и 4 на 8. Ще проведем тестове на ниво на компресия 6 (по подразбиране едно) със и без активиран паралелен gzip.
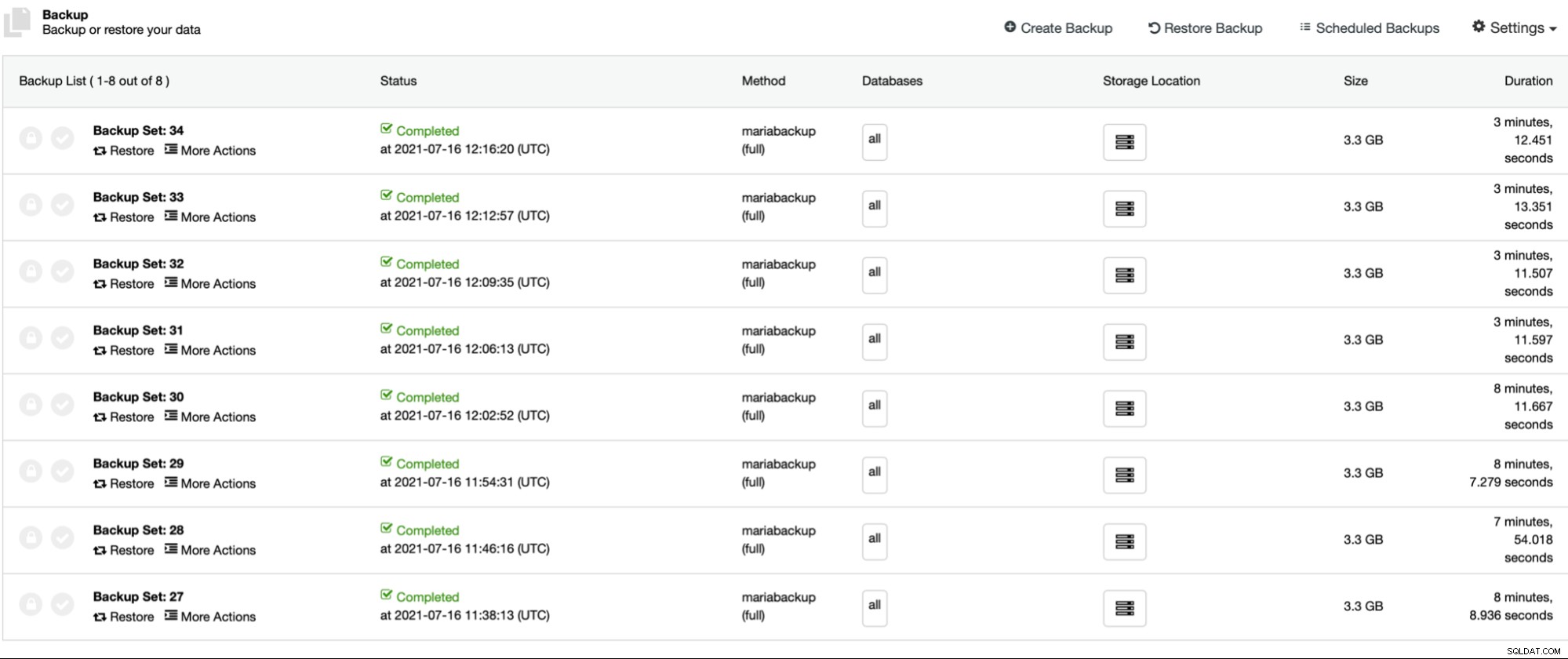
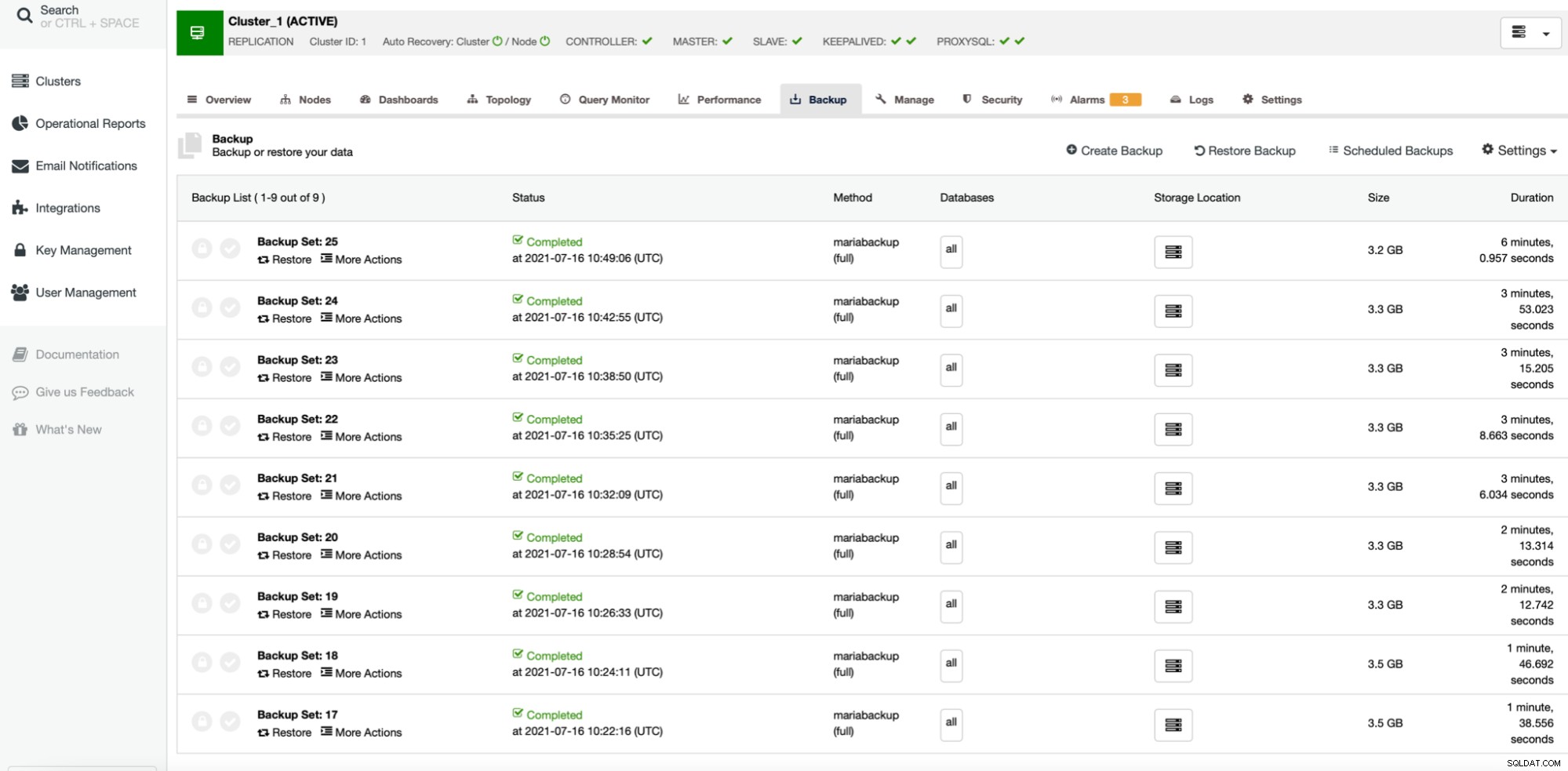
Първите четири резервни копия (27 - 30) са създадени без паралелен gzip, като се започне от 1 до 2, 4 и 8 успоредни копиращи нишки. След това повторихме същия процес за архиви от 31 до 34, този път използвайки паралелен gzip. Както можете да видите, в нашия случай едва ли има разлика между успоредните копиращи нишки. Това най-вероятно ще бъде по-въздействащо, ако увеличим размера на набора от данни. Също така би подобрило производителността на архивиране, ако използваме по-бързо и по-надеждно съхранение. Както обикновено, пробегът ви ще варира и в различни среди тази настройка може да повлияе на процеса на архивиране повече от това, което виждаме тук.
Намаляване на мрежата
Накрая, в тази част от нашата кратка поредица бихме искали да поговорим за възможността за ограничаване на използването на мрежата.
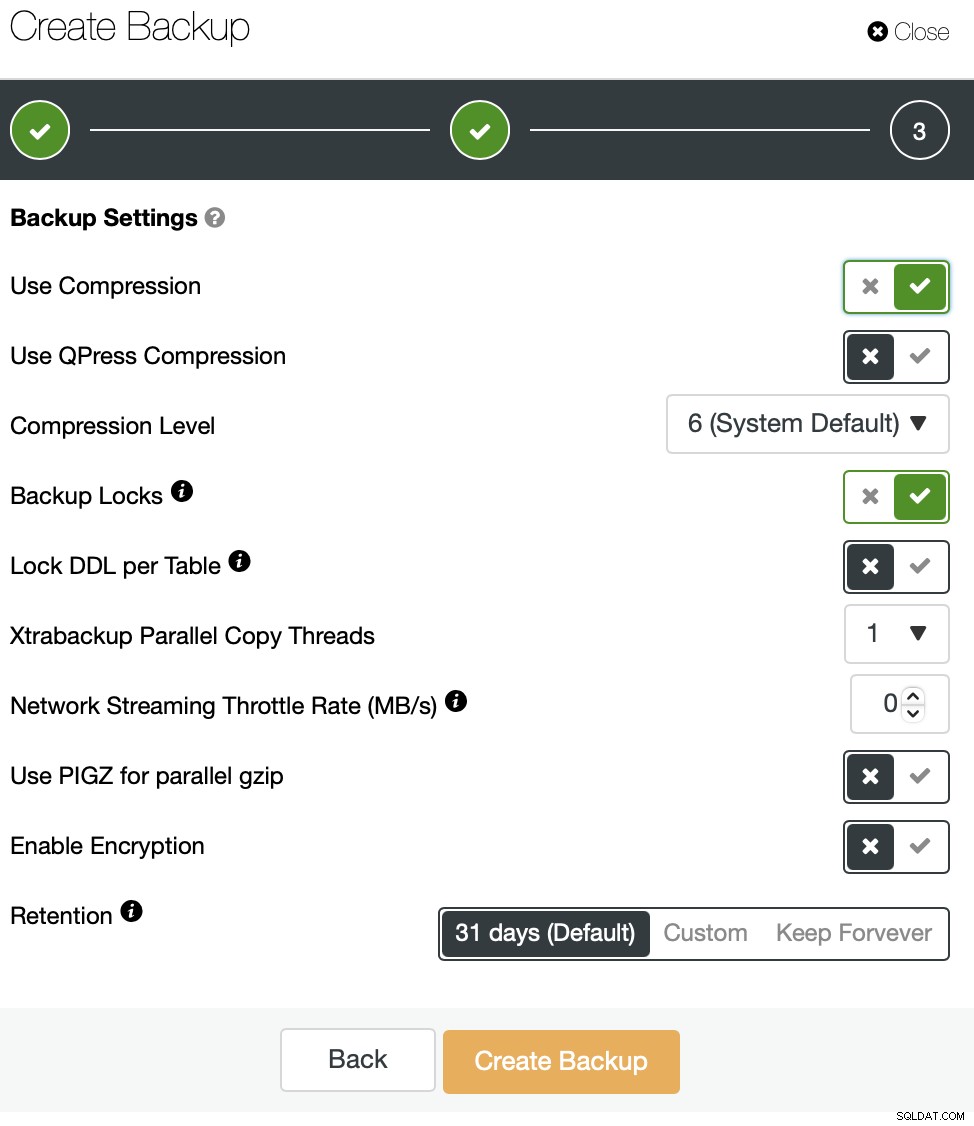
Както може би сте видели, резервните копия могат да се съхраняват локално на възела или може също да се предава поточно към хоста на контролера. Това се случва през мрежата и по подразбиране ще бъде направено „възможно най-бързо“.
В някои случаи, когато пропускателната способност на вашата мрежа е ограничена (например облачни екземпляри), може да искате да намалите използването на мрежата, причинено от MariaBackup, като зададете ограничение за мрежовото прехвърляне. Когато направите това, ClusterControl ще използва инструмент „pv“, за да ограничи наличната честотна лента за процеса.
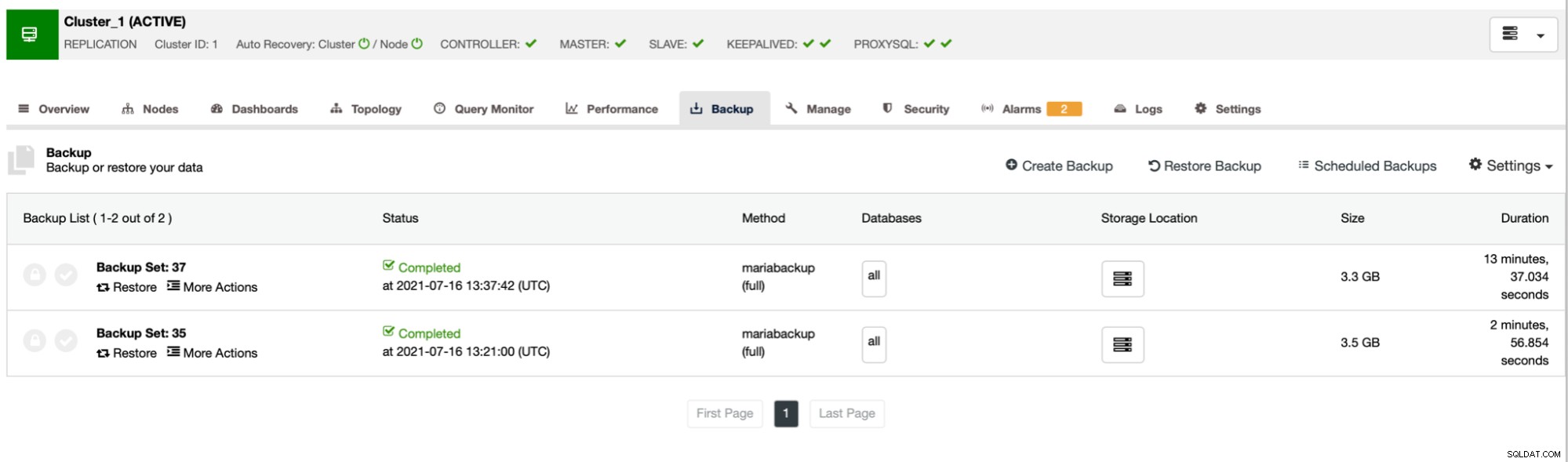
Както можете да видите, първото архивиране отне около 3 минути, но когато ние намали пропускателната способност на мрежата, архивирането отне 13 минути и 37 секунди.
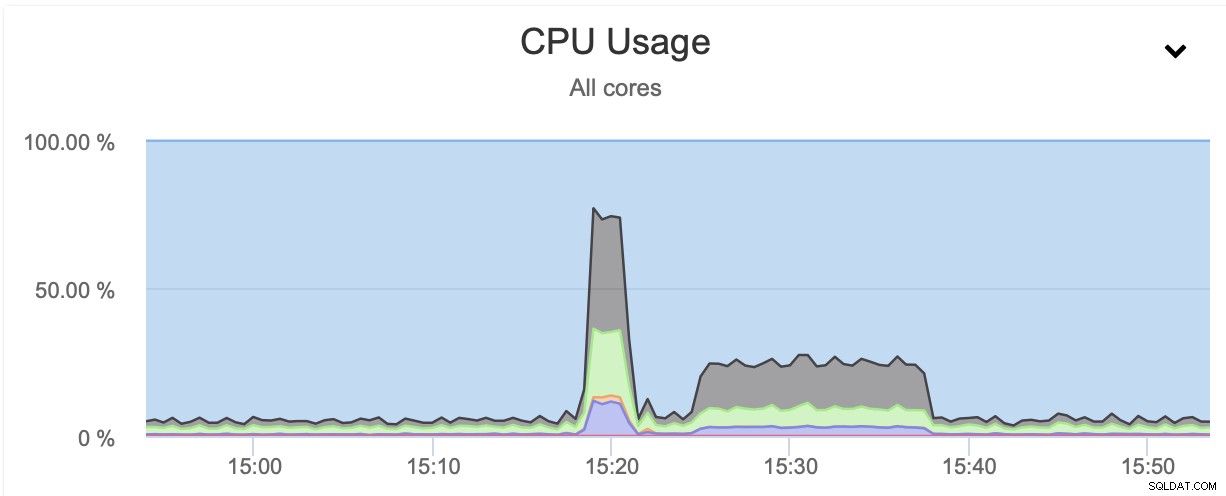
И в двата случая използвахме pigz и ниво на компресия 1. Графиката по-горе показва, че дроселирането на мрежата също намалява използването на процесора. Има смисъл, ако pigz трябва да изчака мрежата да прехвърли данните, не е нужно да натиска силно процесора, тъй като трябва да работи на празен ход през повечето време.
Надяваме се, че сте намерили този кратък блог интересен и може би ще ви насърчи да експериментирате с някои от не толкова често използвани функции и опции на MariaBackup. Ако искате да споделите част от вашия опит, бихме искали да чуем от вас в коментарите по-долу.