Получете общ преглед на наличните механизми за архивиране на данни, съхранявани в Apache HBase, и как да възстановите тези данни в случай на различни сценарии за възстановяване/отказ при отказ
С увеличеното приемане и интегриране на HBase в критични бизнес системи, много предприятия трябва да защитят този важен бизнес актив, като изградят стабилни стратегии за архивиране и възстановяване след бедствие (BDR) за своите HBase клъстери. Колкото и обезсърчително да звучи бързо и лесно архивирането и възстановяването на потенциално петабайти данни, HBase и екосистемата Apache Hadoop предоставят много вградени механизми за постигане на точно това.
В тази публикация ще получите общ преглед на високо ниво на наличните механизми за архивиране на данни, съхранявани в HBase, и как да възстановите тези данни в случай на различни сценарии за възстановяване/отказ при отказ на данни. След като прочетете тази публикация, трябва да сте в състояние да вземете образовано решение за това коя BDR стратегия е най-добра за нуждите на вашия бизнес. Трябва също да разберете плюсовете, минусите и последиците за производителността на всеки механизъм. (Подробностите тук се отнасят за CDH 4.3.0/HBase 0.94.6 и по-нови версии.)
Забележка:Към момента на писане на това писане Cloudera Enterprise 4 предлага готова за производство функция за архивиране и възстановяване след бедствие за HDFS и Hive Metastore чрез Cloudera BDR 1.0 като индивидуално лицензирана функция. HBase не е включена в тази версия на GA; следователно са необходими различните механизми, описани в този блог. (Cloudera Enterprise 5, в момента в бета версия, предлага управление на моментни снимки на HBase чрез Cloudera BDR.)
Резервно копие
HBase е лог-структурирано хранилище за разпределени данни в дървовидно сливане със сложни вътрешни механизми за гарантиране на точността на данните, последователността, управлението на версиите и т.н. И така, как в света можете да получите последователно резервно копие на тези данни, което се намира в комбинация от HFiles и Write-Ahead-Logs (WALs) на HDFS и в паметта на десетки регионални сървъри?
Нека започнем с най-малко разрушителния, най-малък отпечатък на данни, механизъм с най-малко влияние върху производителността и да продължим към най-разрушителния инструмент, подобен на мотокар:
- Снимки
- Репликация
- Експортиране
- CopyTable
- HTable API
- Офлайн архивиране на HDFS данни
Следващата таблица предоставя общ преглед за бързо сравняване на тези подходи, които ще опиша подробно по-долу.
| Влияние върху производителността | Отпечатване на данни | Престой | Постепенно архивиране | Леснота на внедряване | Средно време за възстановяване (MTTR) | |
| Снимки | Минимално | Мъничко | Кратко (само при възстановяване) | Не | Лесно | Секунди |
| Репликация | Минимално | Голям | Няма | Присъщи | Средно | Секунди |
| Експортиране | Висока | Голям | Няма | Да | Лесно | Висока |
| CopyTable | Висока | Голям | Няма | Да | Лесно | Висока |
| API | Средно | Голям | Няма | Да | Трудно | Вие зависи от вас |
| Ръководство | N/A | Голям | Дълги | Не | Средно | Висока |
Снимки
От CDH 4.3.0 моментните снимки на HBase са напълно функционални, богати на функции и не изискват прекъсване на клъстерите по време на тяхното създаване. Моят колега Матео Бертоци покри много добре моментните снимки в своя запис в блога и последвалото дълбоко гмуркане. Тук ще дам само общ преглед на високо ниво.
Моментните снимки просто улавят момент от времето за вашата таблица, като създават еквивалента на твърди връзки в UNIX към файловете за съхранение на вашата таблица на HDFS (Фигура 1). Тези моментни снимки завършват в рамките на секунди, не поставят почти никаква производителност върху клъстера и създават незначителен отпечатък от данни. Вашите данни изобщо не се дублират, а просто се каталогизират в малки файлове с метаданни, което позволява на системата да се върне към този момент във времето, ако трябва да възстановите тази моментна снимка.
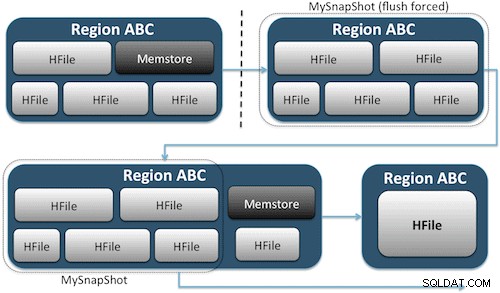
Създаването на моментна снимка на таблица е толкова просто, колкото да изпълните тази команда от обвивката на HBase:
hbase(main):001:0> snapshot 'myTable', 'MySnapShot'
След като издадете тази команда, ще намерите някои малки файлове с данни, разположени в /hbase/.snapshot/myTable (CDH4) или /hbase/.hbase-snapshots (Apache 0.94.6.1) в HDFS, които съдържат необходимата информация за възстановяване на вашата моментна снимка . Възстановяването е толкова просто, колкото издаването на тези команди от обвивката:
hbase(main):002:0> disable 'myTable' hbase(main):003:0> restore_snapshot 'MySnapShot' hbase(main):004:0> enable 'myTable'
Забележка:Както можете да видите, възстановяването на моментна снимка изисква кратко прекъсване, тъй като таблицата трябва да е офлайн. Всички данни, добавени/актуализирани след направата на възстановената моментна снимка, ще бъдат загубени.
Ако вашите бизнес изисквания са такива, че трябва да имате резервно копие на вашите данни извън сайта, можете да използвате командата exportSnapshot, за да дублирате данните на таблица във вашия локален HDFS клъстер или отдалечен HDFS клъстер по ваш избор.
Моментните снимки са пълно изображение на вашата маса всеки път; в момента няма налична функционалност за инкрементално моментно изображение.
Репликация на HBase
Репликацията на HBase е друг инструмент за архивиране с много ниски режийни разходи. (Моят колега Химаншу Вашишта разглежда подробно репликацията в тази публикация в блога.) В обобщение, репликацията може да бъде дефинирана на ниво семейство колони, работи във фонов режим и поддържа всички редакции в синхрон между клъстери във веригата на репликация.
Репликацията има три режима:главен->подчинен, главен<->главен и цикличен. Този подход ви дава гъвкавост да приемате данни от всеки център за данни и гарантира, че те се репликират във всички копия на тази таблица в други центрове за данни. В случай на катастрофално прекъсване в един център за данни, клиентските приложения могат да бъдат пренасочени към алтернативно местоположение за данните, използвайки DNS инструменти.
Репликацията е стабилен, устойчив на грешки процес, който осигурява „евентуална последователност“, което означава, че във всеки един момент последните редакции на таблица може да не са налични във всички реплики на тази таблица, но е гарантирано, че в крайна сметка ще стигнат до там.
Забележка:За съществуващи таблици се изисква първо ръчно да копирате таблицата източник в таблицата местоназначение чрез един от другите начини, описани в тази публикация. Репликацията действа само при нови записи/редактирания, след като я активирате.

(От страницата за репликация на Apache)
Експортиране
Инструментът за експортиране на HBase е вградена помощна програма HBase, която позволява лесното експортиране на данни от таблица на HBase в обикновени SequenceFiles в HDFS директория. Той създава задание MapReduce, което прави серия от извиквания на HBase API към вашия клъстер и едно по едно, получава всеки ред данни от определената таблица и записва тези данни в определената от вас HDFS директория. Този инструмент е с по-висока производителност за вашия клъстер, тъй като използва MapReduce и клиентския API на HBase, но е богат на функции и поддържа филтриране на данни по версия или период от време – като по този начин позволява инкрементално архивиране.
Ето примерна команда в най-простата й форма:
hbase org.apache.hadoop.hbase.mapreduce.Export
След като вашата таблица бъде експортирана, можете да копирате получените файлове с данни навсякъде, където искате (като съхранение извън сайта/извън клъстера). Можете също да посочите отдалечен HDFS клъстер/директория като изходно място на командата и Експортът директно ще запише съдържанието в отдалечения клъстер. Моля, имайте предвид, че този подход ще въведе мрежов елемент в пътя за запис на експортирането, така че трябва да потвърдите, че мрежовата ви връзка с отдалечения клъстер е надеждна и бърза.
CopyTable
Помощната програма CopyTable е обхваната добре в записа в блога на Jon Hsieh, но аз ще обобщя основите тук. Подобно на Export, CopyTable създава задание MapReduce, което използва HBase API за четене от изходна таблица. Основната разлика е, че CopyTable записва изхода си директно в целева таблица в HBase, която може да бъде локална на вашия изходен клъстер или на отдалечен клъстер.
Пример за най-простата форма на командата е:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=testCopy test
Тази команда ще копира съдържанието на таблица с име „test“ в таблица в същия клъстер с име „testCopy“.
Имайте предвид, че CopyTable има значителни разходи за производителност, тъй като използва отделни „поставяния“ за запис на данните, ред по ред, в таблицата на местоназначението. Ако таблицата ви е много голяма, CopyTable може да доведе до запълване на memstore на сървърите на целевия регион, което изисква изтриване на memstore, което в крайна сметка ще доведе до уплътняване, събиране на боклука и т.н.
Освен това трябва да вземете предвид последиците за производителността от стартиране на MapReduce през HBase. С големи набори от данни този подход може да не е идеален.
API на HTable (като персонализирано Java приложение)
Както винаги се случва с Hadoop, винаги можете да напишете свое собствено персонализирано приложение, което използва публичния API и директно запитва таблицата. Можете да направите това чрез задания MapReduce, за да използвате предимствата на разпределената пакетна обработка на тази рамка или чрез всякакви други средства по ваш собствен дизайн. Този подход обаче изисква задълбочено разбиране на разработката на Hadoop и всички API и последиците за производителността от използването им във вашия производствен клъстер.
Офлайн архивиране на необработени HDFS данни
Механизмът за архивиране с най-груба сила - също и най-разрушителният - включва най-големия отпечатък на данни. Можете да изключите чисто своя HBase клъстер и ръчно да копирате всички данни и структури на директории, намиращи се в /hbase във вашия HDFS клъстер. Тъй като HBase не работи, това ще гарантира, че всички данни са запазени в HFiles в HDFS и ще получите точно копие на данните. Въпреки това, постепенните архиви ще бъдат почти невъзможни за получаване, тъй като няма да можете да установите какви данни са променени или добавени при опит за бъдещи резервни копия.
Също така е важно да се отбележи, че възстановяването на вашите данни ще изисква офлайн мета ремонт, тъй като .META. таблицата ще съдържа потенциално невалидна информация към момента на възстановяване. Този подход също изисква бърза надеждна мрежа за прехвърляне на данните извън сайта и възстановяването им по-късно, ако е необходимо.
Поради тези причини Cloudera силно обезкуражава този подход към архивирането на HBase.
Възстановяване след бедствие
HBase е проектирана да бъде изключително устойчива на грешки разпределена система с естествено резервиране, като се приеме, че хардуерът ще се повреди често. Възстановяването при бедствия в HBase обикновено се предлага в няколко форми:
- Катастрофална повреда на ниво център за данни, изискваща преминаване към резервно местоположение
- Нуждае се от възстановяване на предишно копие на вашите данни поради потребителска грешка или случайно изтриване
- Възможността за възстановяване на копие на вашите данни в даден момент за целите на одита
Както при всеки план за възстановяване при бедствия, бизнес изискванията ще определят как е проектиран планът и колко пари да инвестирате в него. След като създадете резервните копия по ваш избор, възстановяването приема различни форми в зависимост от вида на необходимото възстановяване:
- Отказ за архивиране на клъстер
- Импортиране на таблица/възстановяване на моментна снимка
- Насочете основната директория на HBase към местоположението за архивиране
Ако стратегията ви за архивиране е такава, че сте репликирали вашите HBase данни в резервен клъстер в друг център за данни, отказът е толкова лесен, колкото да насочите приложенията на крайния ви потребител към резервния клъстер с DNS техники.
Имайте предвид обаче, че ако планирате да разрешите записването на данни във вашия резервен клъстер по време на периода на прекъсване, ще трябва да се уверите, че данните се връщат обратно в основния клъстер, когато прекъсването приключи. Репликацията от главен към главен или циклична ще се справи с този процес автоматично вместо вас, но схемата за репликация главен-подчинен ще остави вашия главен клъстер несинхронизиран, което ще изисква ръчна намеса след прекъсването.
Заедно с функцията за експортиране, описана по-горе, има съответен инструмент за импортиране, който може да вземе данните, архивирани преди това от експортиране, и да ги възстанови в таблица на HBase. Същите последици за производителността, които се прилагат за Експортиране, са в игра и с Импортирането. Ако вашата схема за архивиране включва правене на моментни снимки, връщането към предишно копие на вашите данни е толкова просто, колкото и възстановяването на тази моментна снимка.
Можете също така да се възстановите от бедствие, като просто модифицирате свойството hbase.root.dir в hbase-site.xml и го насочите към резервно копие на вашата /hbase директория, ако сте направили грубо офлайн копие на HDFS структурите от данни . Това обаче е и най-малко желаната опция за възстановяване, тъй като изисква продължително прекъсване, докато копирате цялата структура от данни обратно във вашия производствен клъстер и както беше споменато по-горе, .META. може да не е синхронизиран.
Заключение
В обобщение, възстановяването на данни след някаква форма на загуба или прекъсване изисква добре разработен план за BDR. Силно ви препоръчвам да разберете добре вашите бизнес изисквания за време на работа, точност/наличност на данните и възстановяване след бедствие. Въоръжени с подробни познания за вашите бизнес изисквания, можете внимателно да изберете инструментите, които най-добре отговарят на тези нужди.
Изборът на инструменти обаче е само началото. Трябва да проведете мащабни тестове на вашата BDR стратегия, за да се уверите, че тя функционира функционално във вашата инфраструктура, отговаря на вашите бизнес нужди и че вашите оперативни екипи са добре запознати с необходимите стъпки, преди да се случи прекъсване и вие ще разберете по трудния начин, че вашият BDR план няма да работи.
Ако искате да коментирате или обсъдите тази тема допълнително, използвайте нашия форум на общността за HBase.
Допълнително четене:
- Презентация на Jon Hsieh Strata + Hadoop World 2012
- HBase:Окончателното ръководство (Ларс Джордж)
- HBase в действие (Ник Димидук/Амандийп Хурана)



