В този блог ще ви предоставим пълното представяне на Hadoop Mapper . аз
В този блог ще отговорим какво представлява Mapper в Hadoop MapReduce, как работи hadoop Mapper, какви са процесите на маппер в Mapreduce, как Hadoop генерира двойка ключ-стойност в MapReduce.
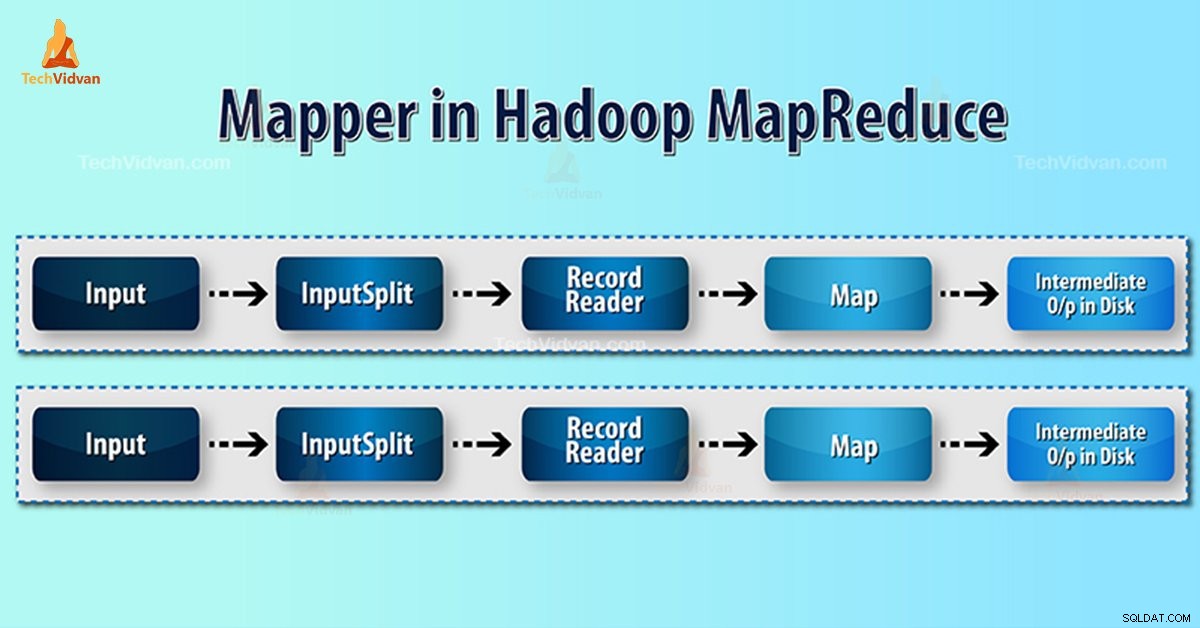
Въведение в Hadoop Mapper
Hadoop Mapper обработва входен запис, създаден от RecordReader и генерира междинни двойки ключ-стойност. Междинният изход е напълно различен от входната двойка.
Резултатът от картографа е пълната колекция от двойки ключ-стойност. Преди да напишете изхода за всяка задача на картографа, разделянето на изхода се извършва въз основа на ключа. По този начин разделянето посочва, че всички стойности за всеки ключ са групирани заедно.
Hadoop MapReduce генерира една задача за карта за всеки InputSplit.
Hadoop MapReduce разбира само двойки ключ-стойност данни. Така че, преди да изпрати данни към картографа, рамката на Hadoop трябва да скрие данните в двойката ключ-стойност.
Как се генерира двойка ключ-стойност в Hadoop?
Тъй като разбрахме какво е mapper в hadoop, сега ще обсъдим как Hadoop генерира двойка ключ-стойност?
- InputSplit – Това е логическото представяне на данните, генерирани от InputFormat. В програмата MapReduce той описва единица работа, която съдържа една задача за карта.
- RecordReader- Той комуникира с inputSplit. И след това преобразува данните в двойки ключ-стойност, подходящи за четене от Mapper. RecordReader по подразбиране използва TextInputFormat за преобразуване на данни в двойката ключ-стойност.
Процес на Mapper в Hadoop MapReduce
InputSplit преобразува физическото представяне на блоковете в логическо за Mapper. Например, за да прочетете файла от 100 MB, той ще изисква 2 InputSplit. За всеки блок рамката създава един InputSplit. Всеки InputSplit създава един картограф.
MapReduce InputSplit не винаги зависи от броя на блоковете данни . Можем да променим номера на разделяне, като зададем свойство mapred.max.split.size по време на изпълнение на заданието.
MapReduce RecordReader е отговорен за четенето/преобразуването на данни в двойки ключ-стойност до края на файла. RecordReader присвоява байтово изместване на всеки ред във файла.
След това Mapper получава тази двойка ключове. Mapper произвежда междинния изход (двойки ключ-стойност, които е разбираемо за намаляване).
Колко задачи за карти в Hadoop?
Броят на картографските задачи зависи от общия брой блокове на входните файлове. В MapReduce map правилното ниво на паралелизъм изглежда е около 10-100 карти/възел. Но има 300 карта за задачи с карта с осветление на процесора.
Например, имаме размер на блок от 128 MB. И очакваме 10TB входни данни. Така той произвежда 82 000 карти. Следователно броят на картите зависи от InputFormat.
Mapper =(общ размер на данните)/ (размер на входно разделяне)
Пример – размерът на данните е 1 TB. Размерът на разделяне на входа е 100 MB.
Mapper =(1000*1000)/100 =10 000
Заключение
Следователно Mapper в Hadoop взема набор от данни и го преобразува в друг набор от данни. По този начин той разделя отделни елементи на кортежи (двойки ключ/стойност).
Надяваме се, че ви харесва този блок, ако имате някакви запитвания за Hadoop mapper, така че, моля, оставете коментар в раздел, даден по-долу. Ще се радваме да ги разрешим.



