Оценяването кой архитектурен модел за стрийминг е най-подходящ за вашия случай на употреба е предпоставка за успешно внедряване в производството.
Екосистемата Apache Hadoop се превърна в предпочитана платформа за предприятия, които се стремят да обработват и разбират широкомащабни данни в реално време. Технологии като Apache Kafka, Apache Flume, Apache Spark, Apache Storm и Apache Samza все повече разширяват границите на възможното. Често е изкушаващо да се обединят мащабни случаи на използване на поточно предаване заедно, но в действителност те са склонни да се разпадат на няколко различни архитектурни модела, като различни компоненти на екосистемата са по-подходящи за различни проблеми.
В тази публикация ще очертая четирите основни модела за стрийминг, които сме срещали с клиенти, работещи в производствени центрове за корпоративни данни, и ще обясня как да имплементирате тези модели архитектурно в Hadoop.
Модели за поточно предаване
Четирите основни модела за стрийминг (често използвани в тандем) са:
- Поемане на поток: Включва запазване на събития с ниска латентност към HDFS, Apache HBase и Apache Solr.
- Обработка на събития в почти реално време (NRT) с външен контекст: Предприема действия като предупреждение, маркиране, трансформиране и филтриране на събития, когато пристигнат. Може да се предприемат действия въз основа на сложни критерии, като модели за откриване на аномалии. Често срещаните случаи на употреба, като откриване и препоръка на NRT измами, често изискват ниски латентности под 100 милисекунди.
- Разпределена обработка на събитие NRT: Подобно на обработката на събития на NRT, но извличане на ползи от разделянето на данните - като съхраняване на по-подходяща външна информация в паметта. Този модел също изисква забавяне на обработката под 100 милисекунди.
- Сложна топология за агрегати или ML: Светият граал на обработката на потоци:получава отговори в реално време от данни със сложен и гъвкав набор от операции. Тук, тъй като резултатите често зависят от изчисления в прозорец и изискват по-активни данни, фокусът се измества от свръхниска латентност към функционалност и точност.
В следващите раздели ще разгледаме препоръчаните начини за внедряване на такива модели по изпитан, доказан и поддържаем начин.
Поглъщане на поточно предаване
Традиционно Flume е препоръчителната система за поглъщане на поточно предаване. Неговата голяма библиотека от източници и мивки покрива всички основи на това какво да консумираме и къде да пишем. (За подробности как да конфигурирате и управлявате Flume, Използване на Flume , книгата O’Reilly Media от софтуерния инженер на Cloudera/члена на Flume PMC Хари Шридхаран е страхотен ресурс.)
През последната година Kafka също стана популярен заради мощни функции като възпроизвеждане и репликация. Поради припокриването между целите на Флум и Кафка, връзката им често е объркваща. Как се съчетават? Отговорът е прост:Kafka е тръба, подобна на абстракцията на Flume's Channel, макар и по-добра тръба поради поддръжката на функциите, споменати по-горе. Един често срещан подход е използването на Flume за източника и мивката и Kafka за тръбата между тях.
Диаграмата по-долу илюстрира как Kafka може да служи като източник на данни нагоре по поток към Flume, дестинация надолу по потока на Flume или Flume Channel.
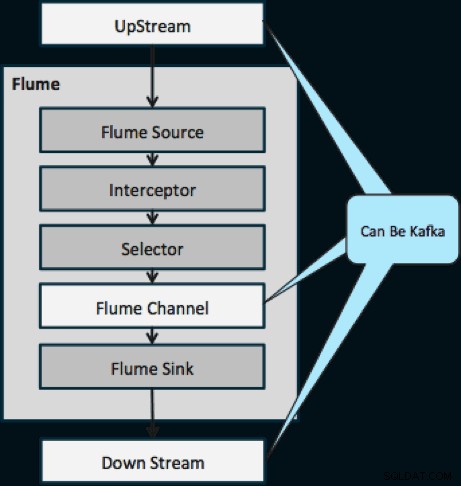
Дизайнът, илюстриран по-долу, е масово мащабируем, закален в битки, централно наблюдаван чрез Cloudera Manager, устойчив на грешки и поддържа повторно възпроизвеждане.
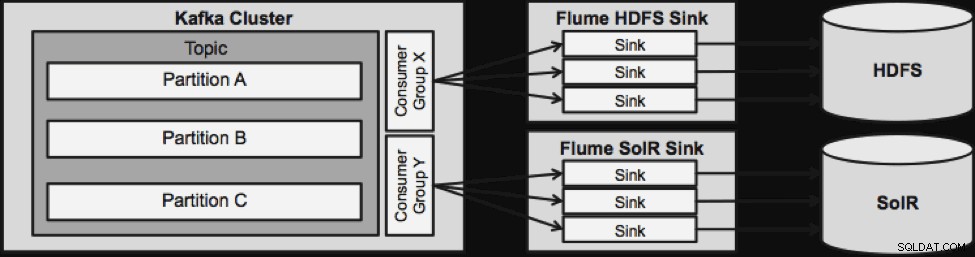
Едно нещо, което трябва да се отбележи, преди да преминем към следващата стрийминг архитектура, е как този дизайн грациозно се справя с провала. The Flume Sinks се изтеглят от Kafka Consumer Group. Потребителската група проследява изместването на темата с помощта на Apache ZooKeeper. Ако се изгуби мивката на Flume, потребителят на Kafka ще преразпредели натоварването към останалите мивки. Когато Flume Sink се върне, потребителската група ще преразпредели отново.
Обработка на NRT събитие с външен контекст
За да повторим, честият случай на използване на този модел е да се разглеждат потоците на събития и да се вземат незабавни решения, или за трансформиране на данните, или за предприемане на някакъв вид външно действие. Логиката на решението често зависи от външни профили или метаданни. Лесен и мащабируем начин за прилагане на този подход е да добавите прехващач Source или Sink Flume към вашата архитектура Kafka/Flume. При скромна настройка не е трудно да се постигнат латентности в ниските милисекунди.
Flume Interceptors приемат събития или партиди от събития и позволяват на потребителския код да променя или предприема действия въз основа на тях. Потребителският код може да взаимодейства с локална памет или външна система за съхранение като HBase, за да получи информация за профила, необходима за вземане на решения. HBase обикновено може да ни даде нашата информация за около 4-25 милисекунди в зависимост от мрежата, дизайна на схемата и конфигурацията. Можете също така да настроите HBase така, че никога да не се прекъсва или прекъсва, дори в случай на повреда.
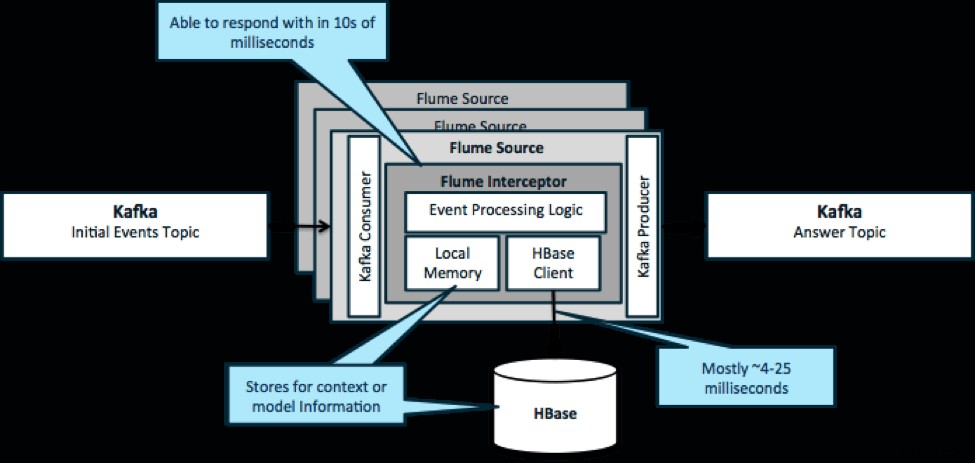
Внедряването не изисква почти никакво кодиране извън специфичната за приложението логика в прехващача. Cloudera Manager предлага интуитивен потребителски интерфейс за внедряване на тази логика чрез колети, както и за свързване, конфигуриране и наблюдение на услугите.
Обработка на разделено събитие на NRT с външен контекст
В архитектурата, илюстрирана по-долу (неразделено решение), ще трябва да извиквате често HBase, тъй като външният контекст, свързан с конкретни събития, не се вписва в локалната памет на прехващачите на Flume.
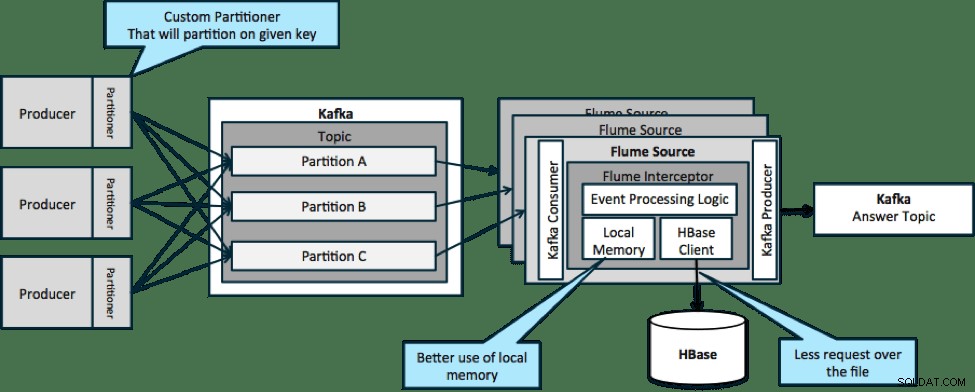
Ако обаче дефинирате ключ за разделяне на вашите данни, можете да съпоставите входящите данни с подмножеството на контекстните данни, което е от значение за тях. Ако разделите данните 10 пъти, тогава трябва да държите само 1/10 от профилите в паметта. HBase е бърз, но локалната памет е по-бърза. Kafka ви позволява да дефинирате персонализиран разделител, който да използва за разделяне на вашите данни.
Имайте предвид, че Flume не е строго необходим тук; основното решение тук е просто потребител на Kafka. Така че можете да използвате само консуматор в YARN или само MapReduce приложение.
Сложна топология за агрегации или ML
До този момент ние проучвахме операции на ниво събитие. Понякога обаче имате нужда от по-сложни операции като броене, средни стойности, сесия или изграждане на модел за машинно обучение, които работят върху партиди данни. В този случай Spark Streaming е идеалният инструмент по няколко причини:
- Разработва се лесно в сравнение с други инструменти. Богатите и кратки API на Spark правят лесно изграждането на сложни топологии.
- Подобен код за поточно предаване и пакетна обработка. С няколко промени кодът за малки партиди в реално време може да се използва за огромни партиди офлайн. В допълнение към намаляването на размера на кода, този подход намалява времето, необходимо за тестване и интегриране.
- Трябва да знаете един двигател. Има разходи, които влизат в обучението на персонала за странностите и вътрешните елементи на разпределените машини за обработка. Стандартизирането на Spark консолидира тази цена както за поточно предаване, така и за пакетно предаване.
- Микропакетирането ви помага да мащабирате надеждно. Потвърждаването на партидно ниво позволява по-голяма пропускателна способност и дава възможност за решения без страх от двойно изпращане. Микропакетирането също помага при изпращането на промени към HDFS или HBase по отношение на производителност в мащаб.
- Интегрирането на екосистемата на Hadoop е заложено. Spark има дълбока интеграция с HDFS, HBase и Kafka.
- Няма риск от загуба на данни. Благодарение на WAL и Kafka, Spark Streaming избягва загуба на данни в случай на повреда.
- Лесно е за отстраняване на грешки и изпълнение. Можете да отстраните грешки и да преминете през своя код Spark Streaming в локална IDE без клъстер. Освен това кодът изглежда като нормален функционален програмен код, така че не отнема много време на разработчик на Java или Scala да направи скок. (Python също се поддържа.)
- Поточното предаване е с първоначално състояние. В Spark Streaming държавата е първокласен гражданин, което означава, че е лесно да се пишат приложения за поточно предаване, които са устойчиви на повреди на възли.
- Като де факто стандарт, Spark получава дългосрочни инвестиции от цялата екосистема.
Към момента на писането на тази статия имаше приблизително 700 ангажименти към Spark като цяло през последните 30 дни – в сравнение с други рамки за поточно предаване, като Storm, с 15 ангажименти за същото време. - Имате достъп до ML библиотеки.
MLlib на Spark става изключително популярен и функционалността му само ще се увеличава. - Можете да използвате SQL, където е необходимо.
Със Spark SQL можете да добавите SQL логика към вашето стрийминг приложение, за да намалите сложността на кода.
Заключение
Има много сила в стрийминг и няколко възможни модела, но както научихте в тази публикация, можете да правите наистина мощни неща с минимално кодиране, ако знаете кой модел съвпада най-добре с вашия случай на употреба.
Тед Маласка е архитект на решения в Cloudera, сътрудник на Spark, Flume и HBase и съавтор на книгата на O’Reilly, Архитектура на приложенията Hadoop.



