Досега разгледахме въведението на Hadoop и Hadoop HDFS подробно. В този урок ще ви предоставим подробно описание на Hadoop Reducer.
Тук ще обсъдим какво представлява Reducer в MapReduce, как работи Reducer в Hadoop MapReduce, различните фази на Hadoop Reducer, как можем да променим броя на Reducer в Hadoop MapReduce.
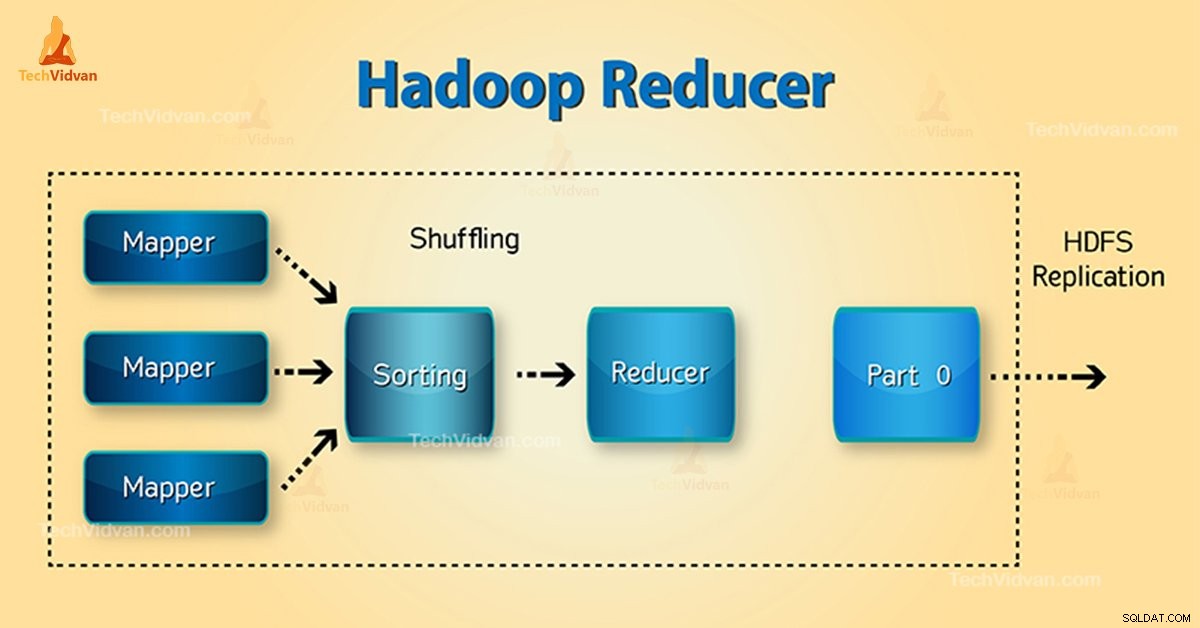
Какво е Hadoop Reducer?
Редуктор в Hadoop MapReduce намалява набор от междинни стойности, които споделят ключ, до по-малък набор от стойности.
В потока за изпълнение на задание MapReduce Reducer приема набор от междинна двойка ключ-стойност произведено отmapperа като вход. След това Reducer обединява, филтрира и комбинира двойки ключ-стойност и това изисква широк спектър от обработка.
Едно-единствено съпоставяне се извършва между клавишите и редукторите при изпълнение на заданието MapReduce. Те работят паралелно, тъй като са независими един от друг. Потребителят решава броя на редукторите в MapReduce.
Фази на Hadoop Reducer
Три фази на Редуктор са както следва:
1. Фаза на разбъркване
Това е фазата, в която сортираният изход от мапера е вход за редуктор. Рамката с помощта на HTTP извлича съответния дял от изхода на всички картографи в тази фаза. Фаза на сортиране
2. Фаза на сортиране
Това е фазата, в която входът от различни карти отново се сортира въз основа на подобни ключове в различни карти.
Разбъркването и сортирането се извършват едновременно.
3. Намаляване на фазата
Тази фаза настъпва след разбъркване и сортиране. Задачата Reduce агрегира двойките ключ-стойност. С OutputCollector.collect() свойство, изходът от задачата за намаляване се записва във файловата система. Изходът на редуктора не е сортиран.
Брой редуктор в Hadoop MapReduce
Потребителят задава броя на редукторите с помощта на Job.setNumreduceTasks(int) Имот. По този начин точният брой редуктори по формулата:
0,95 или 1,75, умножено по (<брой възли> * <бр. максимален контейнер на възел>)
Така че с 0.95 всички редуктори веднага стартират. След това започнете да прехвърляте изходите на картата, когато картите завършат.
По-бързият възел завършва първия кръг на редукторите с 1,75. След това стартира втората вълна на редуктор, който върши много по-добра работа за балансиране на натоварването.
С увеличаване на броя на редукторите:
- Увеличават се допълнителните разходи за рамката.
- Балансирането на натоварването се увеличава.
- Цената на неуспехите намалява.
Заключение
Следователно, Reducer приема изхода на картографи като вход. След това обработете двойките ключ-стойност и произведете изхода. Изходът на редуктора е крайният изход. Ако харесвате този блог или имате въпроси, свързани с Hadoop Reducer, моля, споделете с нас, като оставите коментар.
Надяваме се, че ще ви помогнем.



