Тази публикация в блога ще представи прост пример за „здравей свят“ за това как да получите данни, които се съхраняват в S3, индексирани и обслужвани от услуга на Apache Solr, хоствана в клъстер за откриване и изследване на данни в CDP. За любопитните:DDE е предварително изготвена, оптимизирана за Solr опция за внедряване на клъстер в CDP и наскоро пусната в технически преглед . В този блог ще разгледаме само AWS и S3 среди. Опциите за внедряване на Azure и ADLS също са налични в техническа визуализация, но ще бъдат разгледани в бъдеща публикация в блога.
Ще изобразим най-простия сценарий, за да улесним да започнете. Разбира се, има по-усъвършенствани настройки на конвейера за данни и възможни по-богати схеми, но това е добра отправна точка за начинаещ.
Предположения:
- Вече имате CDP акаунт и имате правомощия на потребител или администратор за средата, в която планирате да развиете тази услуга.
Ако нямате CDP AWS акаунт, моля, свържете се с любимия си представител на Cloudera или се регистрирайте за CDP пробен период тук. - Имате картографирани и конфигурирани среди и самоличности. По-изрично, всичко, от което се нуждаете, е да имате съпоставянето на CDP потребителя с роля на AWS, която предоставя достъп до конкретната s3 кофа, от която искате да четете (и да пишете).
- Вече имате зададена парола за натоварване (FreeIPA).
- Имате работещ DDE клъстер. Можете също да намерите повече информация за използването на шаблони в CDP Data Hub тук.
- Имате CLI достъп до този клъстер.
- SSH портът е отворен в AWS като за вашия IP адрес. Можете да получите публичния IP адрес за един от възлите на Solr в детайлите на клъстера на Datahub. Научете тук как да направите SSH към AWS клъстер.
- Имате регистрационен файл в S3 bucket, който е достъпен за вашия потребител (
/sample.log в този пример). Ако нямате такъв, ето линк към този, който използвахме.
Работен поток
Следващите раздели ще ви преведат през стъпките за индексиране на данни с помощта на инструмента Crunch Indexer, който идва от кутията с DDE.

Създайте колекция, която да съхранява вашия индекс
В HUE има дизайнер на индекси; обаче, докато DDE е в Tech Preview, той ще бъде донякъде в процес на реконструкция и не се препоръчва на този етап. Но, моля, опитайте го, след като DDE стане GA, и ни уведомете какво мислите.
Засега можете да създадете вашата Solr схема и конфигурации с помощта на CLI инструмента „solrctl“. Създайте конфигурация, наречена „my-own-logs-config“ и колекция, наречена „my-own-logs“. Това изисква да имате достъп до CLI.
1. SSH към всеки от работните възли във вашия клъстер.
2. kinit като потребител с разрешение за създаване на конфигурацията на колекцията:
кинит
3. Уверете се, че променливата на средата SOLR_ZK_ENSEMBLE е зададена в /etc/solr/conf/solr-env.sh. Запазете стойността му, тъй като това ще се изисква в следващите стъпки.
Натиснете Enter и въведете вашата парола за натоварване (FreeIPA).
Например:
cat /etc/solr/conf/solr-env.sh
Очакван изход:
експортиране SOLR_ZK_ENSEMBLE=zk01.example.com:2181,zk02.example.com:2181,zk03.example.com:2181/solr
Това се задава автоматично на хостове с роля на Solr Server или Gateway в Cloudera Manager.
4. За да генерирате конфигурационни файлове за колекцията, изпълнете следната команда:
solrctl config --create my-own-logs-config schemalessTemplate -p immutable=false
schemalessTemplate е един от шаблоните по подразбиране, доставяни със Solr в CDP, но тъй като е шаблон, той е неизменим. За целите на този работен процес трябва да го копирате и по този начин да създадете нов, който е променлив (това прави опцията immutable=false). Това ви осигурява гъвкава конфигурация без схема. Създаването на добре проектирана схема е нещо, в което си струва да инвестирате време за проектиране, но не е необходимо за проучвателна употреба. Поради тази причина това е извън обхвата на тази публикация в блога. В реална производствена среда обаче силно препоръчваме използването на добре проектирани схеми – и се радваме да предоставим експертна помощ, ако е необходимо!
5. Създайте нова колекция, като използвате следната команда:
solrctl collection --create my-own-logs -s 1 -c my-own-logs-config
Това създава колекцията „my-own-logs“ въз основа на конфигурацията на колекцията „my-own-logs-config“ на един шард.
6. За да потвърдите, че колекцията е създадена, можете да отидете до потребителския интерфейс на Solr Admin. Колекцията за „my-own-logs“ ще бъде достъпна чрез падащо меню в лявата навигация.

Индексирайте вашите данни
Тук описваме с помощта на прост пример как да конфигурирате и стартирате вградения Crunch Indexer Tool за бързо индексиране на данни в S3 и обслужване чрез Solr в DDE. Тъй като защитата на клъстера може да използва CM Auto TLS, Knox, Kerberos и Ranger, „Spark submit“ може да зависи от аспекти, които не са обхванати в тази публикация.
Индексирането на данни от S3 е същото като индексирането от HDFS.
Изпълнете тези стъпки на работния възел на Yarn (наричан „Yarnworker“ в уеб интерфейса на конзолата за управление).
1. SSH към специалния работен възел на Yarn на DDE клъстера като администратор на Solr.
За да разберете IP адреса на работния възел на Yarn, щракнете върху Хардуер раздела на страницата с подробности за клъстера, след което превъртете до възела „Yarnworker“.

2. Отидете до вашата директория с ресурси (или създайте такава, ако все още нямате:
cd
Използвайте началната папка на потребителя на администратора като директория с ресурси (
3. Свържете своя потребител :
кинит
Натиснете Enter и въведете вашата парола за натоварване (FreeIPA).
4. Изпълнете следната команда curl, като замените
curl --negotiate -u:"https://: /solr/admin?op=GETDELEGATIONTOKEN" --insecure> tokenFile.txt
5. Създайте конфигурационен файл Morphline за инструмента Crunch Indexer, read-log-morphline.conf в този пример. Заменете
SOLR_LOCATOR :{ # Име на колекция от solr :my-own-logs #zk ensemble zkHost :
Този Morphline чете следите на стека от дадения регистрационен файл, след това записва дневник за запис на отстраняване на грешки и го зарежда в посочения Solr.
6. Създайте файл log4j.properties за конфигурация на журнала:
log4j.rootLogger=INFO, A1# A1 е настроен да бъде ConsoleAppender.log4j.appender.A1=org.apache.log4j.ConsoleAppender# A1 използва PatternLayout.log4j.appender.A1.layout=org.apache.log4j .PatternLayoutlog4j.appender.A1.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
7. Проверете дали файлът, който искате да прочетете, съществува на S3 (ако нямате такъв, ето връзка към този, който използвахме за този прост пример:
aws s3 ls s3://
8. Изпълнете командата spark-submit:
Заменете заместителите в и със стойностите, които сте задали.
export myDriverJarDir=/opt/cloudera/parcels/CDH/lib/solr/contrib/crunchexport myDependencyJarDir=/opt/cloudera/parcels/CDH/lib/search/lib/search-crunchexport myDriverJar=$(find.) maxdepth 1 -name 'search-crunch-*.jar' ! -name '*-job.jar' ! -name '*-sources.jar')export myDependencyJarFiles=$(намери $myDependencyJarDir -name '*.jar' | сортиране | tr '\n' ',' | head -c -1)експорт myDependencyJarPaths=$(намери $myDependencyJarDir -name '*.jar' | сортиране | tr '\n' ':' | глава -c -1) export myJVMOptions="-DmaxConnectionsPerHost=10000 -DmaxConnections=10000 -Djava.io.tmpdir=/tmp/dir/ "export myResourcesDir="
Ако срещнете подобно съобщение, може да го пренебрегнете:
WARN metadata.Hive:Неуспешно регистриране на всички functions.org.apache.hadoop.hive.ql.metadata.HiveException:org.apache.thrift.transport.TTransportException
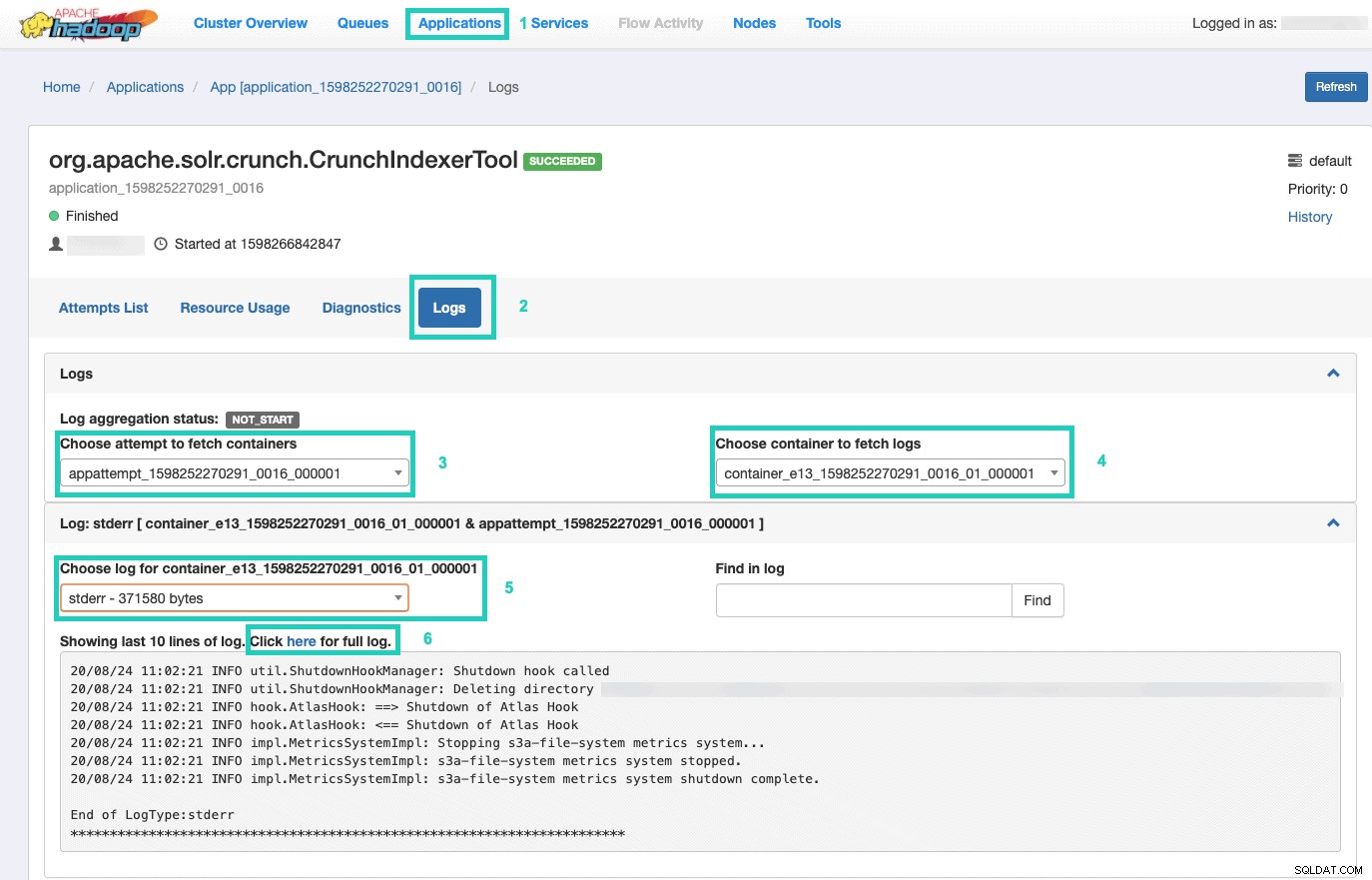
9. За да наблюдавате изпълнението на командата, отидете на Resource Manager.

След като сте там, изберете Приложения раздел > Щракнете върху Идентификационния номер на приложението от опита за приложение, който искате да наблюдавате > Изберете Регистри> Изберете опит за извличане на контейнери> Изберете контейнер за извличане на регистрационни файлове> Изберете регистрационен файл за контейнер> Изберете stderr log> Щракнете върху Щракнете тук за пълен регистър .
Обслужвайте вашия индекс
Имате много опции как да обслужвате индексираните данни с възможност за търсене на крайни потребители. Можете да създадете свое собствено богато приложение, базирано на богатите API на Solr (много често). Можете да свържете любимия си инструмент на трета страна, като Qlik, Tableau и т.н. през техните сертифицирани връзки на Solr. Можете да използвате простото табло за управление на Solr на Hue, за да създадете прототипни приложения.
За да направите последното:
1. Отидете на Hue.

2. В изгледа на таблото за управление отидете до избрания индексен файл (напр. този, който току-що създадохте).
3. Започнете да плъзгате и пускате различни елементи на таблото и изберете полетата от индекса, за да попълните данните за визуалния елемент.
Тук можете да намерите кратко видео с урок за табло за управление от миналото за вдъхновение.
Ще оставим по-дълбоко гмуркане за бъдеща публикация в блога.
Резюме
Надяваме се, че сте научили много от тази публикация в блога за това как да получите данни в S3, индексирани от Solr в DDE с помощта на Crunch Indexer Tool. Разбира се, има много други начини (Spark в изживяването на Data Engineering, Nifi в изживяването на Data Flow, Kafka в опита за управление на потоци и така нататък), но те ще бъдат разгледани в бъдещи публикации в блога. Надяваме се, че сте много успешни в продължаващото си пътуване към изграждането на мощни приложения за прозрение, включващи текст и други неструктурирани данни. Ако решите да изпробвате DDE в CDP, моля, уведомете ни как мина всичко!



