Едно от най-големите притеснения при работа с и управление на бази данни е тяхната сложност на данни и размер. Често организациите се притесняват как да се справят с растежа и да управляват въздействието върху растежа, защото управлението на базата данни се проваля. Сложността идва с опасения, които не са били разгледани първоначално и не са били забелязани или биха могли да бъдат пренебрегнати, тъй като технологията, която се използва в момента, ще може да се справи сама. Управлението на сложна и голяма база данни трябва да бъде съответно планирано, особено когато се очаква типът данни, които управлявате или обработвате, да нарасне значително или очаквано, или по непредсказуем начин. Основната цел на планирането е да се избегнат нежелани бедствия, или да кажем да не се издигате в дим! В този блог ще разгледаме как ефективно да управляваме големи бази данни.
Размерът на данните има значение
Размерът на базата данни има значение, тъй като оказва влияние върху производителността и методологията за управление. Начинът, по който данните се обработват и съхраняват, ще допринесе за това как ще се управлява базата данни, което важи както за данните в пренос, така и за покой. За много големи организации данните са злато и нарастването на данните може да доведе до драстична промяна в процеса. Ето защо е жизненоважно да имате предварителни планове за обработка на нарастващи данни в база данни.
В моя опит в работата с бази данни съм бил свидетел на клиентите, които имат проблеми при справянето с неустойките на производителността и управлението на екстремния растеж на данните. Възникват въпроси дали да се нормализират таблиците срещу денормализиране на таблиците.
Нормализиращи таблици
Нормализирането на таблици поддържа целостта на данните, намалява излишъка и улеснява организирането на данните по по-ефективен начин за управление, анализ и извличане. Работата с нормализирани таблици води до ефективност, особено при анализиране на потока от данни и извличане на данни чрез SQL изрази или работа с езици за програмиране като C/C++, Java, Go, Ruby, PHP, или Python интерфейси с MySQL конекторите.
Въпреки че проблемите с нормализираните таблици имат намаление на производителността и могат да забавят заявките поради поредица от обединявания при извличане на данните. Докато денормализираните таблици, всичко, което трябва да вземете предвид за оптимизация, разчита на индекса или първичния ключ за съхраняване на данни в буфера за по-бързо извличане, отколкото при търсене на множество дискове. Денормализираните таблици не изискват обединения, но жертва целостта на данните, а размерът на базата данни има тенденция да става все по-голям и по-голям.
Когато вашата база данни е голяма, помислете за наличието на DDL (език за дефиниране на данни) за вашата таблица на база данни в MySQL/MariaDB. Добавянето на първичен или уникален ключ за вашата таблица изисква повторно изграждане на таблица. Промяната на тип данни на колона също изисква повторно изграждане на таблица, тъй като алгоритъмът, приложим за прилагане, е само ALGORITHM=COPY.
Ако правите това във вашата производствена среда, това може да бъде предизвикателство. Удвоете предизвикателството, ако масата ви е огромна. Представете си милион или милиард числа редове. Не можете да приложите оператор ALTER TABLE директно към вашата таблица. Това може да блокира целия входящ трафик, който трябва да има достъп до таблицата, в която в момента прилагате DDL. Това обаче може да бъде смекчено чрез използване на pt-online-schema-change или големия gh-ost. Независимо от това, той изисква наблюдение и поддръжка, докато извършва процеса на DDL.
Разделяне и разделяне
С разделянето и разделянето помага за сегрегиране или сегментиране на данните според тяхната логическа идентичност. Например чрез разделяне въз основа на дата, азбучен ред, държава, щат или първичен ключ въз основа на дадения диапазон. Това помага размерът на вашата база данни да бъде управляем. Поддържайте размера на вашата база данни до нейния лимит, който да е управляем за вашата организация и вашия екип. Лесен за мащабиране, ако е необходимо или лесен за управление, особено когато възникне бедствие.
Когато казваме управляем, имайте предвид и ресурсите за капацитет на вашия сървър, както и вашия инженерен екип. Не можете да работите с големи и големи данни с малко инженери. Работата с големи данни като 1000 бази данни с голям брой набори от данни изисква огромно изискване от време. Умението и опитът са задължителни. Ако цената е проблем, това е времето, когато можете да използвате услугите на трети страни, които предлагат управлявани услуги или платени консултации или поддръжка за всяка подобна инженерна работа, която да бъде обслужена.
Набори от знаци и съпоставяне
Наборите от знаци и съпоставянията влияят върху съхранението и производителността на данните, особено върху дадения набор от знаци и избрани съпоставяния. Всеки набор от знаци и съпоставяния имат своето предназначение и най-вече изисква различни дължини. Ако имате таблици, изискващи други набори от знаци и съпоставяне поради кодиране на знаци, данните, които трябва да се съхраняват и обработват за вашата база данни и таблици или дори с колони.
Това засяга как да управлявате ефективно вашата база данни. Това се отразява на съхранението на данни и на производителността, както беше посочено по-рано. Ако сте разбрали видовете знаци, които трябва да бъдат обработени от вашето приложение, обърнете внимание на набора от знаци и съпоставянията, които ще се използват. LATIN типовете набори от знаци са достатъчни най-вече за буквено-цифровия тип знаци, който да се съхранява и обработва.
Ако това е неизбежно, разделянето и разделянето на дялове помагат поне за смекчаване и ограничаване на данните, за да се избегне раздуването на твърде много данни във вашия сървър на база данни. Управлението на много големи данни на един сървър на база данни може да повлияе на ефективността, особено за целите на архивиране, бедствие и възстановяване или възстановяване на данни, както и в случай на повреда или загуба на данни.
Сложността на базата данни влияе върху производителността
Голяма и сложна база данни има тенденция да има фактор, когато става въпрос за намаляване на производителността. Сложно в този случай означава, че съдържанието на вашата база данни се състои от математически уравнения, координати или цифрови и финансови записи. Сега смеси тези записи със заявки, които агресивно използват математическите функции, присъщи на неговата база данни. Разгледайте примерната SQL (съвместима с MySQL/MariaDB) заявка по-долу,
SELECT
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) a,
ATAN2( PI(),
SQRT(
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) -
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) -
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) b,
ATAN2( PI(),
SQRT(
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) *
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) /
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) c
FROM
a
LEFT JOIN `a`.`pk`=`b`.`pk`
LEFT JOIN `a`.`pk`=`c`.`pk`
WHERE
((`a`.`col1` * `c`.`col1` + `a`.`col1` * `b`.`col1`)/ (`a`.`col2`))
between 0 and 100
AND
SQRT(((
(0 + (
(((`a`.`col3` * `a`.`col4` + `b`.`col3` * `b`.`col4` + `c`.`col3` + `c`.`col4`)-(PI()))/(`a`.`col2`)) *
`b`.`col2`)) -
`c`.`col2) *
((0 + (
((( `a`.`col5`* `b`.`col3`+ `b`.`col4` * `b`.`col5` + `c`.`col2` `c`.`col3`)-(0))/( `c`.`col5`)) *
`b`.`col3`)) -
`a`.`col5`)) +
((
(0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * PI() + `c`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `b`.`col5`)) -
`b`.`col5` ) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `c`.`col2` + `b`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * -20.90625)) - `b`.`col5`)) +
(((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2` +`a`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2`5 + `c`.`col3` / `c`.`col2`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`
))) <=600
ORDER BY
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) DESC
Имайте предвид, че тази заявка се прилага към таблица, варираща от един милион реда. Има огромна възможност това да спре сървъра и може да е ресурсно интензивно, причинявайки опасност за стабилността на вашия клъстер от производствена база данни. Включените колони обикновено се индексират, за да оптимизират и да направят тази заявка ефективна. Въпреки това, добавянето на индекси към посочените колони за оптимална производителност не гарантира ефективността на управлението на вашите големи бази данни.
Когато се справяте със сложността, по-ефективният начин е да се избегне строгото използване на сложни математически уравнения и агресивното използване на тази вградена сложна изчислителна способност. Това може да се управлява и транспортира чрез сложни изчисления, използвайки бекенд езици за програмиране, вместо да се използва базата данни. Ако имате сложни изчисления, тогава защо да не съхраните тези уравнения в базата данни, да извлечете заявките, да ги организирате в по-лесни за анализиране или да отстраните грешки, когато е необходимо.
Използвате ли правилната машина за база данни?
Структурата от данни влияе върху производителността на сървъра на базата данни въз основа на комбинацията от дадената заявка и записите, които се четат или извличат от таблицата. Двигателите за бази данни в MySQL/MariaDB поддържат InnoDB и MyISAM, които използват B-Trees, докато NDB или Memory бази данни използват Hash Mapping. Тези структури от данни имат своята асимптотична нотация, която изразява ефективността на алгоритмите, използвани от тези структури от данни. Ние ги наричаме в компютърните науки като Big O нотация, която описва производителността или сложността на алгоритъм. Като се има предвид, че InnoDB и MyISAM използват B-Trees, той използва O(log n) за търсене. Докато хеш таблиците или хеш карти използват O(n). И двете споделят средния и най-лошия случай за неговата производителност с нотацията.
Сега обратно на конкретния двигател, като се има предвид структурата на данните на двигателя, заявката, която трябва да се приложи въз основа на целевите данни, които трябва да бъдат извлечени, разбира се, влияе върху производителността на вашия сървър на база данни. Хеш таблиците не могат да извършват извличане на диапазон, докато B-Trees е много ефективно за извършване на тези видове търсения и също така може да обработва големи количества данни.
Използвайки правилната машина за данните, които съхранявате, трябва да определите какъв тип заявка прилагате за тези конкретни данни, които съхранявате. Какъв тип логика ще формулират тези данни, когато се трансформират в бизнес логика.
Справянето с 1000 или хиляди бази данни, като използвате правилния двигател в комбинация от вашите заявки и данни, които искате да извлечете и съхраните, ще осигури добра производителност. Като се има предвид, че предварително сте определили и анализирали вашите изисквания за предназначението й за правилната среда на база данни.
Правилни инструменти за управление на големи бази данни
Много е трудно и трудно да управлявате много голяма база данни без солидна платформа, на която можете да разчитате. Дори с добри и квалифицирани инженери на база данни, технически сървърът на базата данни, който използвате, е податлив на човешка грешка. Една грешка от всякакви промени в конфигурационните параметри и променливи може да доведе до драстична промяна, която да доведе до влошаване на производителността на сървъра.
Извършването на архивиране на вашата база данни на много голяма база данни понякога може да бъде предизвикателство. Има случаи, при които архивирането може да се провали поради някои странни причини. Обикновено заявките, които могат да спрат сървъра, където се изпълнява архивирането, причиняват неуспех. В противен случай трябва да проучите причината за това.
Използването на автоматизация като Chef, Puppet, Ansible, Terraform или SaltStack може да се използва като IaC за осигуряване на по-бързи задачи за изпълнение. Докато използвате и други инструменти на трети страни, които да ви помогнат да наблюдавате и предоставяте висококачествени графични изображения. Системите за известяване и аларми също са много важни, за да ви уведомяват за проблеми, които могат да възникнат от ниво на предупреждение до ниво на критично състояние. Това е мястото, където ClusterControl е много полезен в този вид ситуации.
ClusterControl предлага лекота за управление на голям брой бази данни или дори с разчленени типове среди. Той е тестван и инсталиран хиляди пъти и работи в продукции, предоставящи аларми и известия на администраторите на база данни, инженерите или DevOps, работещи със средата на базата данни. Обхват от етапи или разработка, QA, до производствена среда.
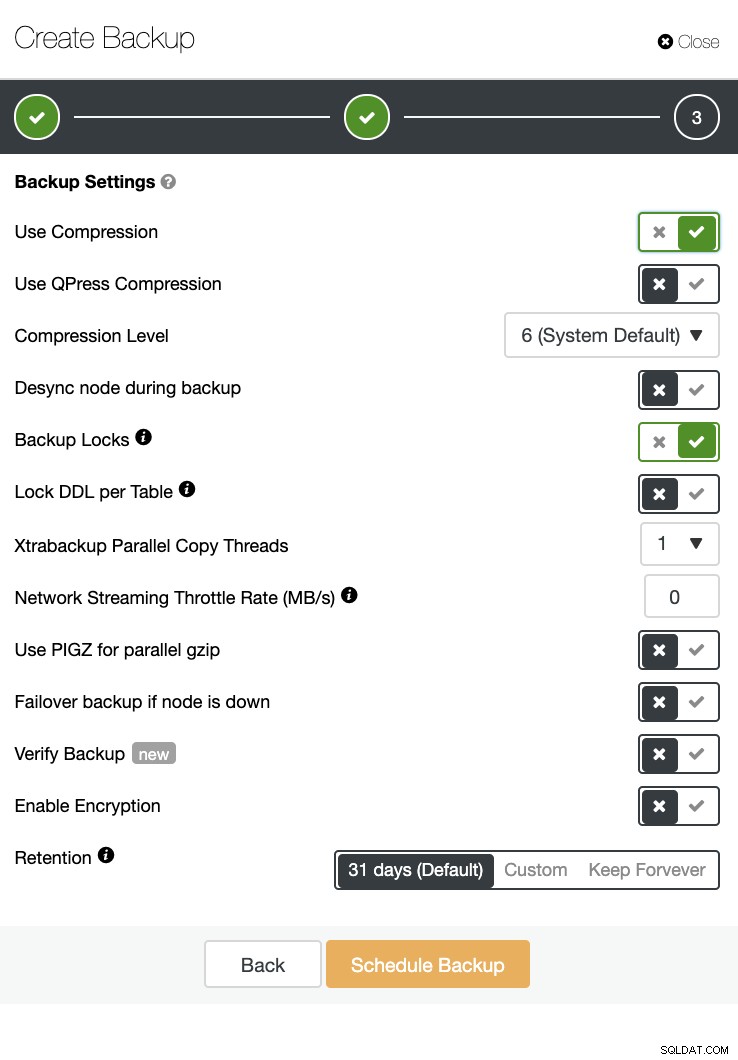
ClusterControl също може да извършва архивиране и възстановяване. Дори с големи бази данни, той може да бъде ефективен и лесен за управление, тъй като потребителският интерфейс осигурява планиране и също така има опции за качването му в облака (AWS, Google Cloud и Azure).
Има също потвърждаване на резервно копие и много опции като криптиране и компресиране. Вижте екранната снимка по-долу например (създаване на резервно копие за MySQL с помощта на Xtrabackup):
Заключение
Управлението на големи бази данни като хиляда или повече може да се извърши ефективно, но трябва да се определи и подготви предварително. Използването на правилните инструменти като автоматизация или дори абониране за управлявани услуги помага драстично. Въпреки че е свързано с разходи, оборотът на услугата и бюджетът, който трябва да се излее за придобиване на квалифицирани инженери, могат да бъдат намалени, стига да са налични правилните инструменти.



