Производствените прекъсвания са почти гарантирани в даден момент. Приемането на този факт и анализирането на времевата линия и сценария на отказ от прекъсване на вашата база данни може да помогне за по-добра подготовка, диагностика и възстановяване от следващото. За да смекчат въздействието от престоя, организациите се нуждаят от подходящ план за възстановяване при бедствия (DR). Планирането на DR е критична задача за много SysOps/DevOps, но въпреки че е предвидено; често не съществува.
В тази публикация в блога ще анализираме различни сценарии за архивиране и откази в системите за бази данни MongoDB. Ние също така ще ви преведем през процедурите за възстановяване и преодоляване на срив за всеки съответен сценарий. Тези случаи на употреба ще варират от възстановяване на един възел, възстановяване на възел в съществуващ replicaSet и засаждане на нов възел в replicaSet. Надяваме се, че това ще ви даде добро разбиране на рисковете, пред които може да се сблъскате и какво да вземете предвид при проектирането на вашата инфраструктура.
Преди да започнем да обсъждаме възможни сценарии на срив, нека да разгледаме как MongoDB съхранява данни и какви типове архивиране са налични.
Как MongoDB съхранява данни
MongoDB е документно-ориентирана база данни. Вместо да съхранява вашите данни в таблици, направени от отделни редове (както прави релационната база данни), той съхранява данни в колекции, направени от отделни документи. В MongoDB документът е голям JSON blob без конкретен формат или схема. Освен това данните могат да бъдат разпределени в различни възли на клъстер чрез споделяне или репликирани на подчинени сървъри с replicaSet.
MongoDB позволява много бързо записване и актуализации по подразбиране. Компромисът е, че често не сте уведомени изрично за неуспехи. По подразбиране повечето драйвери извършват асинхронно, опасно записване. Това означава, че драйверът не връща директно грешка, подобно на INSERT DELAYED с MySQL. Ако искате да знаете дали нещо е успяло, трябва ръчно да проверите за грешки с помощта на getLastError.
За оптимална производителност е за предпочитане да използвате SSD вместо HDD за съхранение. Необходимо е да се погрижите дали вашето хранилище е локално или отдалечено и да вземете съответните мерки. По-добре е да използвате RAID за защита на хардуерни дефекти и схеми за възстановяване, но не разчитайте изцяло на него, тъй като не предлага защита срещу неблагоприятни повреди. Правилният хардуер е градивният елемент за вашето приложение за оптимизиране на производителността и избягване на голям провал.
Повреда на данни на ниво диск или липсващи файлове с данни могат да попречат на стартирането на mongod екземпляри и файловете на журнала може да са недостатъчни за автоматично възстановяване.
Ако работите с активирано дневникиране, почти никога няма нужда да стартирате ремонт, тъй като сървърът може да използва файловете на дневника, за да възстанови автоматично файловете с данни до чисто състояние. Въпреки това може да се наложи да извършите поправка в случаите, когато трябва да се възстановите от повреда на данни на ниво диск.
Ако журналирането не е активирано, единствената ви опция може да бъде да изпълните команда за поправка. mongod --repair трябва да се използва само ако нямате други опции, тъй като операцията премахва (и не записва) всички повредени данни по време на процеса на поправка. Този тип операция винаги трябва да се предшества от архивиране.
Сценарий за аварийно възстановяване на MongoDB
В план за възстановяване при неуспех, вашата цел за точка на възстановяване (RPO) е ключов параметър за възстановяване, който диктува колко данни можете да си позволите да загубите. RPO е посочен във времето, от милисекунди до дни и е пряко зависим от вашата система за архивиране. Той взема предвид възрастта на вашите архивни данни, които трябва да възстановите, за да възобновите нормалните операции.
За да оцените RPO, трябва да си зададете няколко въпроса. Кога се архивират данните ми? Какво е SLA, свързано с извличането на данните? Приемливо ли е възстановяването на резервно копие на данните или данните трябва да са онлайн и готови за запитване във всеки един момент?
Отговорите на тези въпроси ще ви помогнат да изберете какъв тип решение за архивиране ви е необходимо.
Решения за архивиране на MongoDB
Технологиите за архивиране имат различно въздействие върху производителността на работещата база данни. Някои решения за архивиране влошават производителността на базата данни достатъчно, че може да се наложи да планирате архивиране, за да избегнете пикова употреба или прозорци за поддръжка. Може да решите да разположите нови вторични сървъри само за поддържане на архивиране.
Трите най-често срещани решения за архивиране на вашия MongoDB сървър/клъстер са...
- Mongodump/Mongorestore – логическо архивиране.
- Система за управление на Mongo (облак) – Производствените бази данни могат да бъдат архивирани с помощта на MongoDB Ops Manager или ако използвате услугата MongoDB Atlas, можете да използвате напълно управлявано решение за архивиране.
- Моментни снимки на базата данни (архивиране на ниво диск)
Mongodump/Mongorestore
При извършване на mongodump всички колекции в рамките на определените бази данни ще бъдат извлечени като BSON изход. Ако не е посочена база данни, MongoDB ще изхвърли всички бази данни с изключение на администраторската, тестовата и локалната база данни, тъй като те са запазени за вътрешна употреба.
По подразбиране mongodump ще създаде директория, наречена dump, с директория за всяка база данни, съдържаща BSON файл за всяка колекция в тази база данни. Като алтернатива можете да кажете на mongodump да съхранява архива в един архивен файл. Параметърът archive ще обединява изхода от всички бази данни и колекции в един единствен поток от двоични данни. Освен това, параметърът gzip може естествено да компресира този архив, използвайки gzip. В ClusterControl ние предаваме поточно всички наши архиви, така че активираме параметрите за архивиране и gzip.
Подобно на mysqldump с MySQL, ако създадете резервно копие в MongoDB, то ще замрази колекциите, докато изхвърля съдържанието в архивния файл. Тъй като MongoDB не поддържа транзакции (променено в 4.2), не можете да направите 100% напълно последователно архивиране, освен ако не създадете архива с параметъра oplog. Активирането на това в архивирането включва транзакциите от oplog, които се изпълняваха по време на правенето на архива.
За по-добра автоматизация и можете да стартирате MongoDB от командния ред или да използвате външни инструменти като ClusterControl. ClusterControl е препоръчителна опция за управление на архивиране и автоматизация на архивиране, тъй като позволява създаване на усъвършенствани стратегии за архивиране за различни системи за бази данни с отворен код.
ClusterControl ви позволява да качите резервното си копие в облака. Той поддържа пълно архивиране и възстановява криптирането на mongodump. Ако искате да видите как работи, на нашия уебсайт има демонстрация.
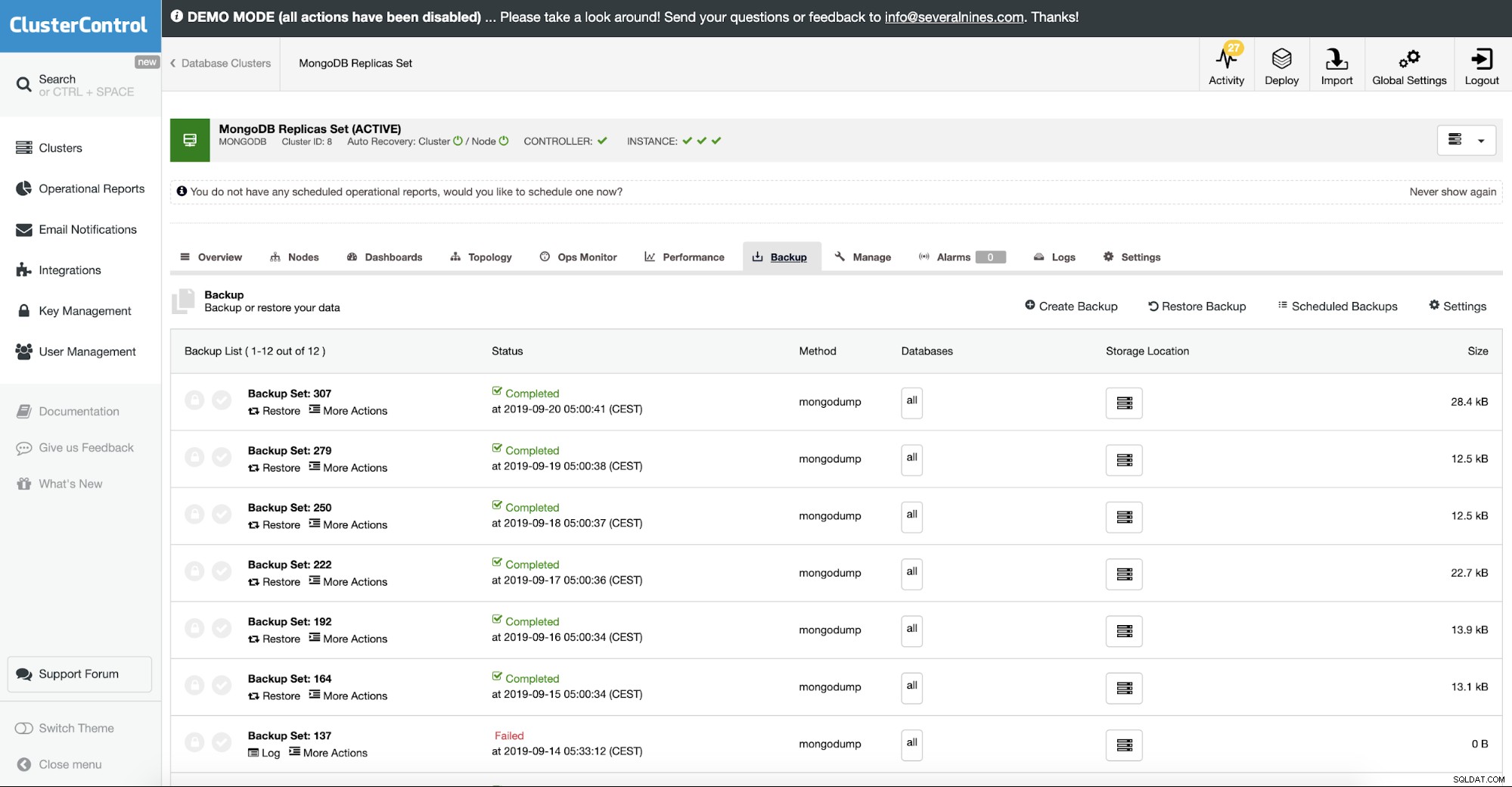
Възстановяване на MongoDB от резервно копие
По принцип има два начина, по които можете да използвате дъмп във формат BSON:
- Изпълнете mongod директно от резервната директория
- Стартирайте mongorestore и възстановете архива
Изпълнете mongod директно от резервно копие
Предпоставка за стартиране на mongod директно от архива е целта за архивиране да е стандартен дъмп и да не се архивира в gzip.
След това демонът MongoDB ще провери целостта на директорията с данни, ще добави администраторската база данни, дневниците, каталозите за колекции и индекси и някои други файлове, необходими за стартиране на MongoDB. Ако преди сте стартирали WiredTiger като машина за съхранение, сега той ще изпълнява съществуващите колекции като MMAP. За прости дъмпове на данни или проверки на целостта, това работи добре.
Изпълнение на mongorestore
По-добър начин за възстановяване очевидно би бил чрез възстановяване на възела с помощта на mongorestore.
mongorestore dump/Това ще възстанови архива в настройките на сървъра по подразбиране (localhost, порт 27017) и ще презапише всички бази данни в архива, които се намират на този сървър. Сега има много параметри за манипулиране на процеса на възстановяване и ние ще покрием някои от важните.
В ClusterControl това се прави в опцията за възстановяване на архивиране. Можете да изберете машината, когато архивът ще бъде възстановен и да обработите, като се погрижите за останалото. Това включва криптирано архивиране, където обикновено трябва да дешифрирате архива си.
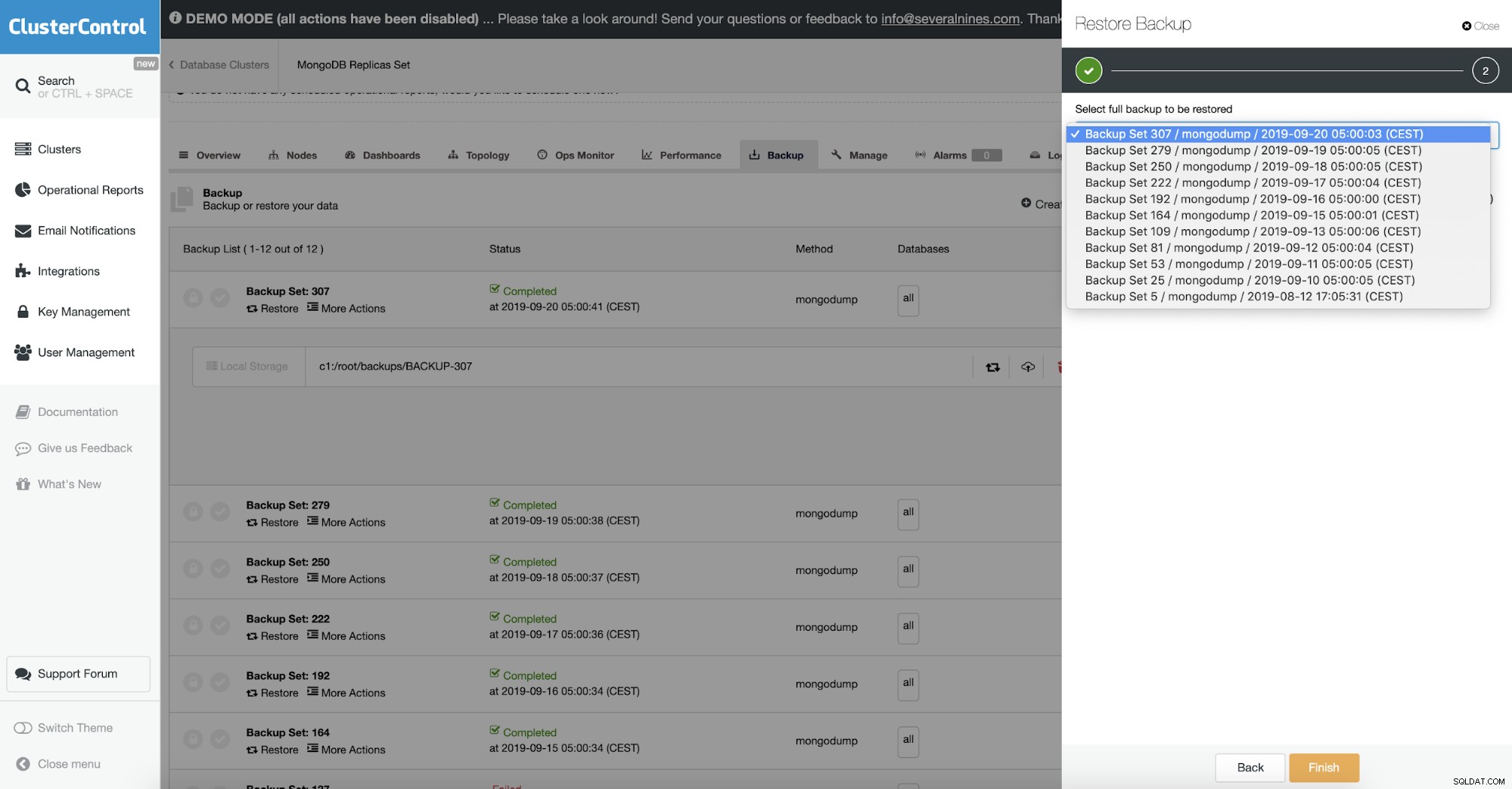
Проверка на обекта
Тъй като архивът съдържа BSON данни, очаквате съдържанието на архива да е правилно. Възможно е обаче изхвърленият документ да е неправилно оформен. Mongodump не проверява целостта на данните, които изхвърля.
За да се справим с тази употреба -- objcheck, който принуждава mongorestore да валидира всички заявки от клиенти при получаване, за да гарантира, че клиентите никога не вмъкват невалидни документи в базата данни. Може да има малко влияние върху производителността.
Възпроизвеждане на Oplog
Oplog към вашия архив ще ви позволи да извършвате последователно архивиране и да извършвате възстановяване в момента. Активирайте параметъра oplogReplay, за да приложите oplog по време на процеса на възстановяване. За да контролирате колко далеч да възпроизвеждате oplog, можете да дефинирате времеви печат в параметъра oplogLimit. Тогава ще бъдат приложени само транзакции до времевата марка.
Възстановяване на пълен набор от реплики от резервно копие
Възстановяването на replicaSet не е много по-различно от възстановяването на един възел. Или първо трябва да настроите replicaSet и да възстановите директно в replicaSet. Или първо възстановявате един възел и след това използвате този възстановен възел, за да създадете replicaSet.
Първо възстановете възела, след това създайте replicaSet
Сега вторият и третият възел ще синхронизират данните си от първия възел. След като синхронизирането приключи, нашият replicaSet е възстановен.
Първо създайте ReplicaSet, след това възстановете
За разлика от предишния процес, можете първо да създадете replicaSet. Първо конфигурирайте и трите хоста с активиран replicaSet, стартирайте и трите демона и инициирайте replicaSet на първия възел:
Сега, когато създадохме replicaSet, можем директно да възстановим резервното си копие в него:
Според нас възстановяването на replicaSet по този начин е много по-елегантно. Това е по-близо до начина, по който обикновено настройвате нов replicaSet от нулата и след това го запълвате с (производствени) данни.
Поставяне на нов възел в набор от реплики
Когато мащабирате клъстер чрез добавяне на нов възел в MongoDB, трябва да се случи първоначалното синхронизиране на набора от данни. С репликацията на MySQL и Galera сме толкова свикнали да използваме резервно копие, за да създадем първоначалното синхронизиране. С MongoDB това е възможно, но само като се направи двоично копие на директорията с данни. Ако нямате средства да направите моментна снимка на файловата система, ще трябва да се сблъскате с престой на един от съществуващите възли. Процесът с престой е описан по-долу.
Засяване с резервно копие
И така, какво ще се случи, ако вместо това възстановите новия възел от резервно копие на mongodump и след това го накарате да се присъедини към replicaSet? Възстановяването от резервно копие на теория би трябвало да даде същия набор от данни. Тъй като този нов възел е възстановен от резервно копие, няма да му липсва replicaSetId и MongoDB ще забележи. Тъй като MongoDB не вижда този възел като част от replicaSet, тогава командата rs.add() винаги ще задейства първоначалното синхронизиране на MongoDB. Първоначалното синхронизиране винаги ще задейства изтриване на всички съществуващи данни на възела MongoDB.
ReplicaSetId се генерира при иницииране на replicaSet и за съжаление не може да бъде зададен ръчно. Това е жалко, тъй като възстановяването от резервно копие (включително повторно възпроизвеждане на oplog) теоретично би ни дало 100% идентичен набор от данни. Би било хубаво първоначалното синхронизиране да е по избор в MongoDB, за да удовлетвори този случай на употреба.



