Балансирането на натоварването на базата данни разпределя едновременни клиентски заявки към множество сървъри на бази данни, за да намали количеството натоварване на всеки един сървър. Това може да подобри драстично производителността на вашата база данни. За щастие MongoDB може да обработва заявки на множество клиенти за четене и запис на едни и същи данни едновременно по подразбиране. Той използва някои механизми за контрол на паралелността и протоколи за заключване, за да гарантира последователност на данните по всяко време.
По този начин MongoDB също така гарантира, че всички клиенти получават последователен изглед на данните по всяко време. Поради тази вградена функция за обработка на заявки от множество клиенти, не е нужно да се притеснявате за добавяне на външен балансьор на натоварване върху вашите MongoDB сървъри. Въпреки че, ако все пак искате да подобрите производителността на вашата база данни с помощта на балансиране на натоварването, ето няколко начина да постигнете това.
Вертикално мащабиране на MongoDB
Опростено казано, вертикалното мащабиране означава добавяне на повече ресурси към вашия сървър, които да обработвате за зареждане. Както всички системи за бази данни, MongoDB предпочита повече RAM и IO капацитет. Това е най-простият начин за повишаване на производителността на MongoDB, без да се разпределя натоварването между множество сървъри. Вертикалното мащабиране на базата данни MongoDB обикновено включва увеличаване на капацитета на процесора или капацитета на диска и увеличаване на пропускателната способност (I/O операции). Чрез добавяне на повече ресурси вашият монго сървър става по-способен да обработва множество заявки на клиенти. По този начин по-добро балансиране на натоварването за вашата база данни.
Недостатъкът на използването на този подход е техническото ограничение за добавяне на ресурси към всяка отделна система. Освен това всички доставчици на облак имат ограничения за добавяне на нови хардуерни конфигурации. Другият недостатък на този подход е една точка на провал. При този подход всички ваши данни се съхраняват в една система, което може да доведе до трайна загуба на данните ви.
Хоризонтално мащабиране на MongoDB
Хоризонталното мащабиране се отнася до разделяне на вашата база данни на парчета и съхраняването им на множество сървъри. Основното предимство на този подход е, че можете да добавяте допълнителни сървъри в движение, за да увеличите производителността на вашата база данни с нулев престой. MongoDB осигурява хоризонтално мащабиране чрез разделяне. Разделянето на MongoDB дава допълнителен капацитет за разпределение на натоварването при запис между множество сървъри (шардове). Тук всеки фрагмент може да се разглежда като една независима база данни и колекцията от всички фрагменти може да се разглежда като една голяма логическа база данни. Разделянето позволява на вашия MongoDB да разпространява данните между множество сървъри, за да обработва ефективно едновременни клиентски заявки. Следователно, той увеличава пропускателната способност за четене и запис на вашата база данни.
Sharding MongoDB
Шардът може да бъде единичен екземпляр на mongod или набор от реплика, който съдържа подмножеството на mongo sharded база данни. Можете да конвертирате фрагмент в набор от реплики, за да осигурите висока наличност на данни и излишък.
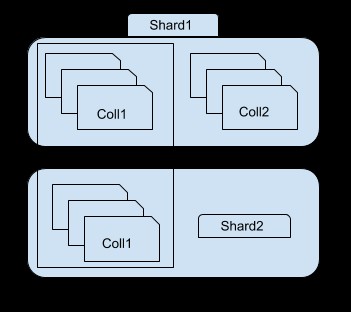
Както можете да видите на изображението по-горе, фрагмент 1 съдържа подмножество от колекция 1 и цялата колекция2, докато фрагмент 2 съдържа само друго подмножество от колекция1. Можете да получите достъп до всеки шард, като използвате екземпляра mongos. Например, ако се свържете с екземпляр на shard1, ще можете да видите/достъпите само до подмножество от колекция1.
Монго
Mongos е рутерът за заявки, който осигурява достъп до разчленен клъстер за клиентски приложения. Можете да имате няколко екземпляра на mongos за по-добро балансиране на натоварването. Например във вашия производствен клъстер можете да имате един mongos екземпляр за всеки сървър на приложения. Сега тук можете да използвате външен балансьор на натоварване, който ще пренасочи заявката на вашия сървър на приложения към подходящ mongos екземпляр. Докато добавяте такива конфигурации към вашия производствен сървър, уверете се, че връзката от всеки клиент винаги се свързва към един и същ mongo екземпляр всеки път, тъй като някои mongo ресурси, като курсори, са специфични за mongos екземпляр.
Конфигуриране на сървъри
Конфигурационните сървъри съхраняват конфигурационните настройки и метаданните за вашия клъстер. От MongoDB версия 3.4 трябва да разположите конфигурационните сървъри като набор от реплики. Ако активирате разделяне в производствена среда, тогава е задължително да използвате три отделни конфигурационни сървъра, всеки на различни машини.
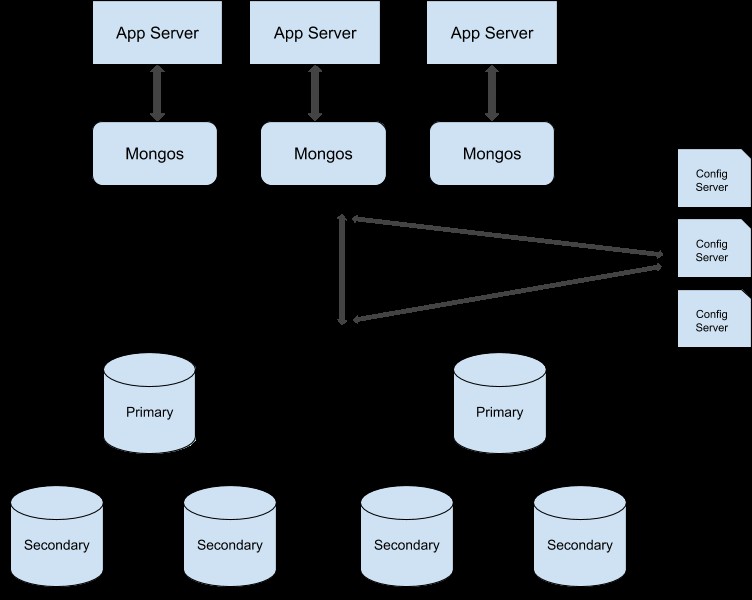
Можете да следвате това ръководство, за да преобразувате своя клъстер от набор от реплики в разделен клъстер. Ето примерната илюстрация на разделен производствен клъстер:
Балансиране на натоварването на MongoDB с помощта на репликация
Понякога репликацията на MongoDB може да се използва за обработка на повече трафик от клиенти и за намаляване на натоварването на основния сървър. За да направите това, можете да инструктирате клиентите да четат от вторични вместо от основния сървър. Това може да намали количеството натоварване на основния сървър, тъй като всички заявки за четене, идващи от клиенти, ще се обработват от вторични сървъри, а основният сървър ще се грижи само за заявките за запис.
Следва командата за задаване на предпочитанието за четене на вторично:
db.getMongo().setReadPref('secondary')Можете също да посочите някои маркери за насочване към конкретни вторични, докато обработвате заявките за четене.
db.getMongo().setReadPref(
"secondary", [
{ "datacenter": "APAC" },
{ "region": "East"},
{}
])Тук MongoDB ще се опита да намери вторичния възел със стойността на тага на центъра за данни като APAC. Ако бъде намерен, Mongo ще обслужва заявките за четене от всички вторични с таг център за данни:„APAC“. Ако не бъде намерен, тогава Mongo ще се опита да намери вторични с регион на етикета:„Изток“. Ако все още не са намерени вторични източници, тогава {} ще работи като регистър по подразбиране и Mongo ще обслужва заявките от всички отговарящи на условията вторични източници.
Този подход за балансиране на натоварването обаче не е препоръчително да се използва за увеличаване на пропускателната способност на четене. Тъй като всеки режим на предпочитания за четене, различен от основния, може да върне стари данни в случай на скорошни актуализации на запис на основния сървър. Обикновено основният сървър ще отнеме известно време, за да обработи заявките за запис и да разпространи промените към вторични сървъри. През това време, ако някой поиска операция за четене на същите данни, вторичният сървър ще върне остарели данни, тъй като те не са в синхрон с основния сървър. Можете да използвате този подход, ако вашето приложение е тежко за операциите за четене в сравнение с операциите за запис.
Заключение
Тъй като MongoDB може да обработва едновременни заявки сам, няма нужда да добавяте балансьор на натоварване във вашия MongoDB клъстер. За балансиране на натоварването на клиентските заявки можете да изберете или вертикално мащабиране, или хоризонтално мащабиране, тъй като не е препоръчително да използвате вторични елементи за мащабиране на вашите операции за четене и запис. Вертикалното мащабиране може да достигне техническите граници, както беше обсъдено по-горе. Поради това е подходящ за малки по мащаб приложения. За големи приложения хоризонталното мащабиране чрез разделяне е най-добрият подход за балансиране на натоварването на операциите за четене и запис.



