Тази публикация в блога е продължение на предишната част 1, където разгледахме основите на SNMP интеграцията с ClusterControl.
В тази публикация в блога ще се съсредоточим върху SNMP капаните и предупрежденията. SNMP капаните са най-често използваните предупредителни съобщения, изпращани от отдалечено устройство с активиран SNMP (агент) до централен колектор, „SNMP мениджър“. В случай на ClusterControl, капанът може да бъде сигнал, след като критичната аларма за клъстер не е 0, което показва, че се случва нещо лошо.
Както е показано в предишната публикация в блога, за целите на това доказателство на концепцията имаме две дефиниции за уведомления за прихващане на SNMP:
criticalAlarmNotification NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification if critical alarm is not 0"
::= { alarmNotification 1 }
criticalAlarmNotificationEnded NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification ended - Critical alarm is 0"
::= { alarmNotification 2 }Уведомленията (или капановете) са CriticalAlarmNotification и CriticalAlarmNotificationEnded. И двете събития за уведомяване могат да се използват за сигнализиране на нашата услуга Nagios, независимо дали клъстерът има активно критични аларми или не. В Nagios терминът за това е пасивна проверка, при която Nagios не се опитва да определи дали хостът/услугата е НЕДОСТЪПНА или НЕДОСТЪПНА. Ние също така ще конфигурираме активните проверки, при които проверките се инициират от логиката за проверка в демона Nagios, като използваме дефиницията на услугата, за да наблюдаваме и критичните/предупредителни аларми, докладвани от нашия клъстер.
Обърнете внимание, че тази публикация в блога изисква Severalnines MIB и SNMP агент да са конфигурирани правилно, както е показано в първата част от тази поредица от блогове.
Инсталиране на Nagios Core
Nagios Core е безплатната версия на пакета за наблюдение на Nagios. На първо място, трябва да го инсталираме и всички необходими пакети, последвани от плъгините Nagios, snmptrapd и snmptt. Имайте предвид, че инструкциите в тази публикация в блога предполагат, че всички възли работят на CentOS 7.
Инсталирайте необходимите пакети, за да стартирате Nagios:
$ yum -y install httpd php gcc glibc glibc-common wget perl gd gd-devel unzip zip sendmail net-snmp-utils net-snmp-perlСъздайте потребител на nagios и група nagcmd, за да позволите на външните команди да се изпълняват през уеб интерфейса, добавете потребителя nagios и apache да бъдат част от групата nagcmd:
$ useradd nagios
$ groupadd nagcmd
$ usermod -a -G nagcmd nagios
$ usermod -a -G nagcmd apacheИзтеглете най-новата версия на Nagios Core от тук, компилирайте и инсталирайте:
$ cd ~
$ wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.6.tar.gz
$ tar -zxvf nagios-4.4.6.tar.gz
$ cd nagios-4.4.6
$ ./configure --with-nagios-group=nagios --with-command-group=nagcmd
$ make all
$ make install
$ make install-init
$ make install-config
$ make install-commandmodeИнсталирайте уеб конфигурацията на Nagios:
$ make install-webconfПо избор инсталирайте темата за ексфолиране Nagios (или можете да се придържате към темата по подразбиране):
$ make install-exfoliationСъздайте потребителски акаунт (nagiosadmin) за влизане в уеб интерфейса на Nagios. Запомнете паролата, която задавате на този потребител:
$ htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminРестартирайте уеб сървъра на Apache, за да влязат в сила новите настройки:
$ systemctl restart httpd
$ systemctl enable httpdИзтеглете плъгините Nagios от тук, компилирайте и инсталирайте:
$ cd ~
$ wget https://nagios-plugins.org/download/nagios-plugins-2.3.3.tar.gz
$ tar -zxvf nagios-plugins-2.3.3.tar.gz
$ cd nagios-plugins-2.3.3
$ ./configure --with-nagios-user=nagios --with-nagios-group=nagios
$ make
$ make installПроверете конфигурационните файлове на Nagios по подразбиране:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
Nagios Core 4.4.6
Copyright (c) 2009-present Nagios Core Development Team and Community Contributors
Copyright (c) 1999-2009 Ethan Galstad
Last Modified: 2020-04-28
License: GPL
Website: https://www.nagios.org
Reading configuration data...
Read main config file okay...
Read object config files okay...
Running pre-flight check on configuration data...
Checking objects...
Checked 8 services.
Checked 1 hosts.
Checked 1 host groups.
Checked 0 service groups.
Checked 1 contacts.
Checked 1 contact groups.
Checked 24 commands.
Checked 5 time periods.
Checked 0 host escalations.
Checked 0 service escalations.
Checking for circular paths...
Checked 1 hosts
Checked 0 service dependencies
Checked 0 host dependencies
Checked 5 timeperiods
Checking global event handlers...
Checking obsessive compulsive processor commands...
Checking misc settings...
Total Warnings: 0
Total Errors: 0
Things look okay - No serious problems were detected during the pre-flight check
If everything looks okay, start Nagios and configure it to start on boot:
$ systemctl start nagios
$ systemctl enable nagiosОтворете браузъра и отидете на https://{IPaddress}/nagios и трябва да видите изскачащо HTTP основно удостоверяване, където трябва да посочите потребителското име като nagiosadmin с избраната от вас парола, създадена по-рано.
Добавяне на сървър на ClusterControl в Nagios
Създайте файл с дефиниция на хост Nagios за ClusterControl:
$ vim /usr/local/nagios/etc/objects/clustercontrol.cfgИ добавете следните редове:
define host {
use linux-server
host_name clustercontrol.local
alias clustercontrol.mydomain.org
address 192.168.10.50
}
define service {
use generic-service
host_name clustercontrol.local
service_description Critical alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.2 -c0
}
define service {
use generic-service
host_name clustercontrol.local
service_description Warning alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.3 -w0
}
define service {
use snmp_trap_template
host_name clustercontrol.local
service_description Critical alarm traps
check_interval 60 ; Don't clear for 1 hour
}
Някои обяснения:
-
В първия раздел дефинираме нашия хост с името на хоста и адреса на сървъра ClusterControl.
-
Секциите на услугите, в които поставяме дефинициите на нашите услуги, за да бъдат наблюдавани от Nagios. Първите две основно казват на услугата да провери изхода на SNMP за конкретен идентификатор на обект. Първата услуга е за критичната аларма, затова добавяме -c0 в командата check_snmp, за да посочим, че трябва да бъде критичен сигнал в Nagios, ако стойността надхвърли 0. Докато за предупредителните аларми, ние ще го посочим с предупреждение, ако стойността е 1 и по-висока.
-
Последната дефиниция на услугата е за SNMP капаните, които бихме очаквали да идват от сървъра на ClusterControl, ако критичната аларма повдигнато е по-високо от 0. Този раздел ще използва дефиницията на snmp_trap_template, както е показано в следващата стъпка.
Конфигурирайте snmp_trap_template, като добавите следните редове в /usr/local/nagios/etc/objects/templates.cfg:
define service {
name snmp_trap_template
service_description SNMP Trap Template
active_checks_enabled 1 ; Active service checks are enabled
passive_checks_enabled 1 ; Passive service checks are enabled/accepted
parallelize_check 1 ; Active service checks should be parallelized
process_perf_data 0
obsess_over_service 0 ; We should obsess over this service (if necessary)
check_freshness 0 ; Default is to NOT check service 'freshness'
notifications_enabled 1 ; Service notifications are enabled
event_handler_enabled 1 ; Service event handler is enabled
flap_detection_enabled 1 ; Flap detection is enabled
process_perf_data 1 ; Process performance data
retain_status_information 1 ; Retain status information across program restarts
retain_nonstatus_information 1 ; Retain non-status information across program restarts
check_command check-host-alive ; This will be used to reset the service to "OK"
is_volatile 1
check_period 24x7
max_check_attempts 1
normal_check_interval 1
retry_check_interval 1
notification_interval 60
notification_period 24x7
notification_options w,u,c,r
contact_groups admins ; Modify this to match your Nagios contactgroup definitions
register 0
}
Включете конфигурационния файл на ClusterControl в Nagios, като добавите следния ред вътре
/usr/local/nagios/etc/nagios.cfg:
cfg_file=/usr/local/nagios/etc/objects/clustercontrol.cfgИзпълнете проверка на конфигурацията преди полета:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgУверете се, че получавате следния ред в края на изхода:
"Things look okay - No serious problems were detected during the pre-flight check"Рестартирайте Nagios, за да заредите промяната:
$ systemctl restart nagiosСега, ако погледнем страницата Nagios под секцията Service (меню отляво), ще видим нещо подобно:
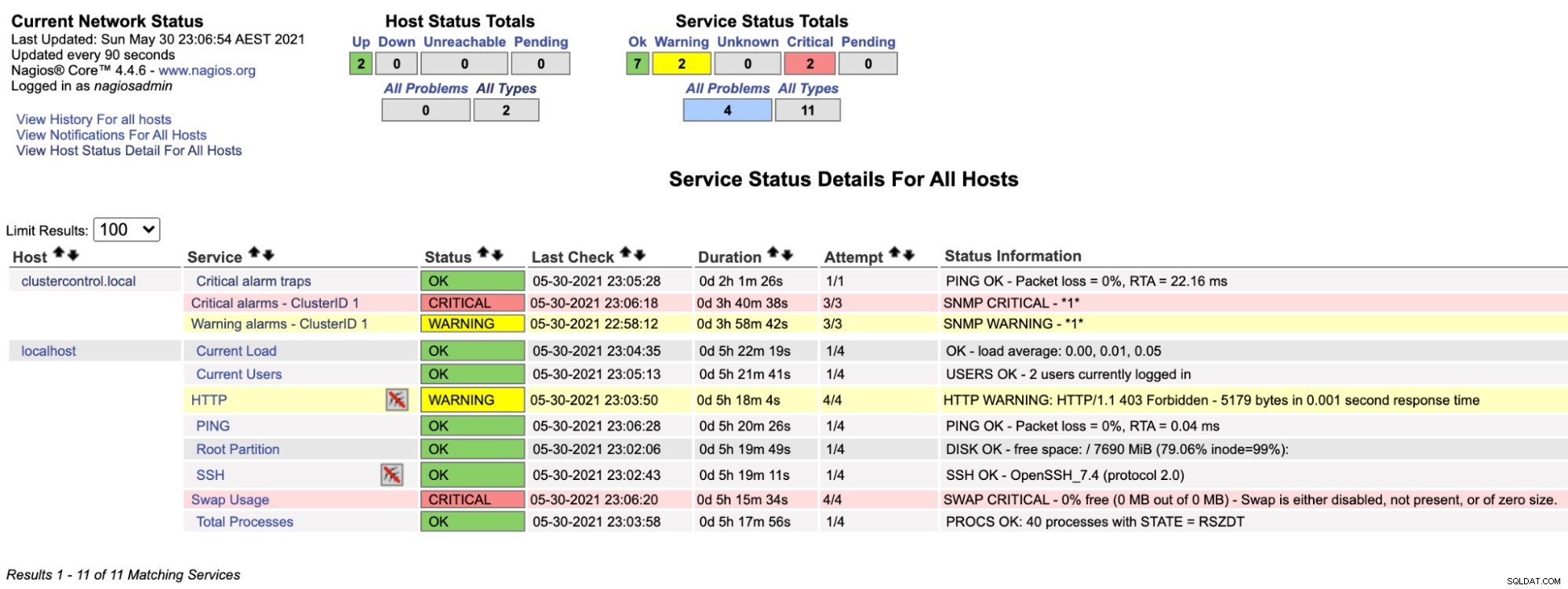
Забележете, че редът "Критични аларми - ClusterID 1" става червен, ако стойността на критичната аларма, докладвана от ClusterControl, е по-голяма от 0, докато "Предупредителни аларми - ClusterID 1" е жълто, което показва, че има повдигната предупредителна аларма. В случай, че не се случи нищо интересно, ще видите, че всичко е зелено за clustercontrol.local.
Конфигуриране на Nagios за получаване на капан
Капаните се изпращат от отдалечени устройства към сървъра на Nagios, това се нарича пасивна проверка. В идеалния случай не знаем кога ще бъде изпратен капан, тъй като зависи от това, което изпращащото устройство реши, че ще изпрати капан. Например с UPS (резервна батерия), веднага щом устройството загуби захранване, то ще изпрати капан, за да каже "хей, загубих захранване". По този начин Nagios се информира незабавно.
За да получаваме SNMP капани, трябва да конфигурираме сървъра Nagios със следните неща:
-
snmptrapd (демон на приемник за улавяне на SNMP)
-
snmptt (SNMP Trap Translator, демонът за обработка на trap)
След като snmptrapd получи капан, той ще го предаде на snmptt, където ще го конфигурираме да актуализира системата Nagios и след това Nagios ще изпрати предупреждение според конфигурацията на групата за контакти.
Инсталирайте EPEL хранилище, последвано от необходимите пакети:
$ yum -y install epel-release
$ yum -y install net-snmp snmptt net-snmp-perl perl-Sys-SyslogКонфигурирайте SNMP trap демона в /etc/snmp/snmptrapd.conf и задайте следните редове:
disableAuthorization yes
traphandle default /usr/sbin/snmptthandlerГоворното просто означава, че капаните, получени от демона snmptrapd, ще бъдат предадени на /usr/sbin/snmptthandler.
Добавете SEVERALNINES-CLUSTERCONTROL-MIB.txt в /usr/share/snmp/mibs, като създадете /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt:
$ ll /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt
-rw-r--r-- 1 root root 4029 May 30 20:08 /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txtСъздайте /etc/snmp/snmp.conf (забележете без "d") и добавете нашия персонализиран MIB там:
mibs +SEVERALNINES-CLUSTERCONTROL-MIBСтартирайте услугата snmptrapd:
$ systemctl start snmptrapd
$ systemctl enable snmptrapdСлед това трябва да конфигурираме следните конфигурационни редове в /etc/snmp/snmptt.ini:
net_snmp_perl_enable = 1
snmptt_conf_files = <<END
/etc/snmp/snmptt.conf
/etc/snmp/snmptt-cc.conf
ENDОбърнете внимание, че активирахме модула net_snmp_perl и сме добавили друг път за конфигурация, /etc/snmp/snmptt-cc.conf вътре в snmptt.ini. Тук трябва да дефинираме ClusterControl snmptt събития, за да могат да бъдат предадени на Nagios. Създайте нов файл в /etc/snmp/snmptt-cc.conf и добавете следните редове:
MIB: SEVERALNINES-CLUSTERCONTROL-MIB (file:/usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt) converted on Sun May 30 19:17:33 2021 using snmpttconvertmib v1.4.2
EVENT criticalAlarmNotification .1.3.6.1.4.1.57397.1.1.3.1 "Status Events" Critical
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 2 "Critical - Critical alarm is $1 for cluster ID $2"
SDESC
Notification if critical alarm is not 0
Variables:
1: totalCritical
2: clusterId
EDESC
EVENT criticalAlarmNotificationEnded .1.3.6.1.4.1.57397.1.1.3.2 "Status Events" Normal
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 0 "Normal - Critical alarm is $1 for cluster ID $2"
SDESC
Notification ended - critical alarm is 0
Variables:
1: totalCritical
2: clusterId
EDESCНякои обяснения:
-
Имаме дефинирани два капана – CriticalAlarmNotification и CriticalAlarmNotificationEnded.
-
CriticalAlarmNotification просто повдига критичен сигнал и го предава на услугата "Критични алармени капани", дефинирана в Nagios. $aA означава връщане на IP адреса на агента за прихващане. Стойността 2 е стойността на резултата от проверката, която в този случай е критична (0=ОК, 1=ПРЕДУПРЕЖДЕНИЕ, 2=КРИТИЧНО, 3=НЕИЗВЕСТНО).
-
CriticalAlarmNotificationEnded просто подава сигнал OK и го предава на услугата "Critical alarm traps", за да отмени предишен капан след като всичко се върне към нормалното. $aA означава връщане на IP адреса на агента за прихващане. Стойността 0 е стойността на резултата от проверката, която в този случай е ОК. За повече подробности относно заместванията на низове, разпознати от snmptt, вижте тази статия в секцията „ФОРМАТ“.
-
Можете да използвате snmpttconvertmib за генериране на файл за обработка на snmptt събития за конкретен MIB.
Имайте предвид, че по подразбиране пътят на обработчиците на събития не се предоставя от Nagios Core. Следователно, трябва да копираме тази директория eventhandlers от източника Nagios в директорията contrib, както е показано по-долу:
$ cp -Rf nagios-4.4.6/contrib/eventhandlers /usr/local/nagios/share/
$ chown -Rf nagios:nagios /usr/local/nagios/share/eventhandlersСъщо така трябва да присвоим snmptt група като част от групата nagcmd, за да може да изпълни nagios.cmd вътре в скрипта submit_check_result:
$ usermod -a -G nagcmd snmpttСтартирайте услугата snmptt:
$ systemctl start snmptt
$ systemctl enable snmpttSNMP Manager (Nagios сървър) вече е готов да приеме и обработва нашите входящи SNMP капани.
Изпращане на капан от сървъра на ClusterControl
Да предположим, че някой иска да изпрати SNMP trap до SNMP мениджъра, 192.168.10.11 (сървър Nagios), тъй като общият брой на критичните аларми е достигнал 2 за клъстер ID 1, човек ще изпълни следната команда на сървърът ClusterControl (от страна на клиента), 192.168.10.50:
$ snmptrap -v2c -c private 192.168.10.11 '' SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification \
SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical i 2 \
SEVERALNINES-CLUSTERCONTROL-MIB::clusterId i 1Или във формат OID (препоръчително):
$ snmptrap -v2c -c private 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.1 \
.1.3.6.1.4.1.57397.1.1.1.2 i 2 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Където, .1.3.6.1.4.1.57397.1.1.3.1 е равно на критично събитие за улавяне на критично предупреждение, а следващите OID са представяния на общия брой на текущите критични аларми и идентификатора на клъстера, съответно .
На сървъра Nagios трябва да забележите, че услугата trap е станала червена:
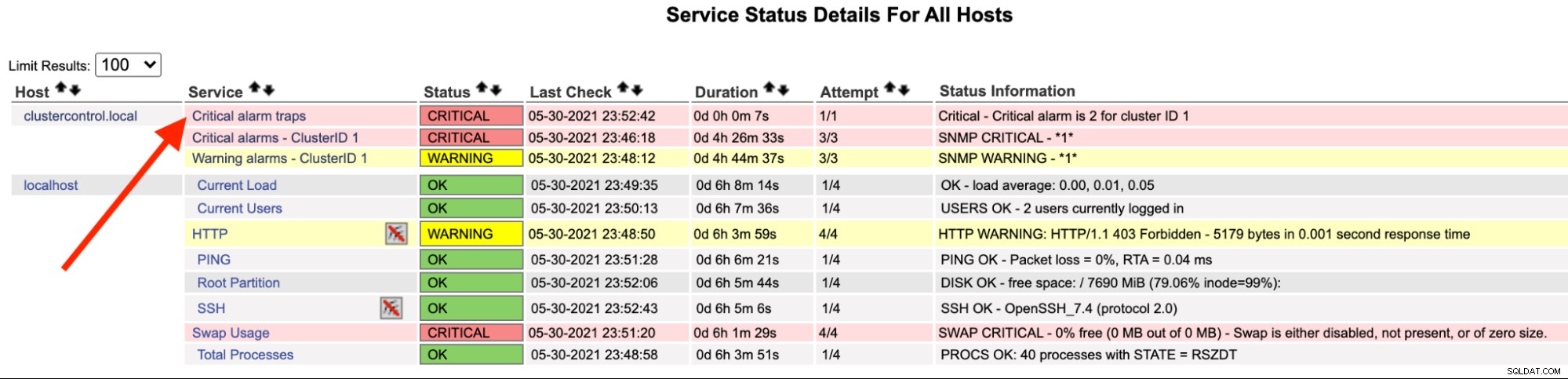
Можете също да го видите в /var/log/messages на следния ред:
May 30 23:52:39 ip-10-15-2-148 snmptrapd[27080]: 2021-05-30 23:52:39 UDP: [192.168.10.50]:33151->[192.168.10.11]:162 [UDP: [192.168.10.50]:33151->[192.168.10.11]:162]:#012DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (2423020) 6:43:50.20#011SNMPv2-MIB::snmpTrapOID.0 = OID: SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification#011SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical = INTEGER: 2#011SEVERALNINES-CLUSTERCONTROL-MIB::clusterId = INTEGER: 1
May 30 23:52:42 nagios.local snmptt[29557]: .1.3.6.1.4.1.57397.1.1.3.1 Critical "Status Events" UDP192.168.10.5033151-192.168.10.11162 - Notification if critical alarm is not 0
May 30 23:52:42 nagios.local nagios: EXTERNAL COMMAND: PROCESS_SERVICE_CHECK_RESULT;192.168.10.50;Critical alarm traps;2;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: PASSIVE SERVICE CHECK: clustercontrol.local;Critical alarm traps;0;PING OK - Packet loss = 0%, RTA = 22.16 ms
May 30 23:52:42 nagios.local nagios: SERVICE NOTIFICATION: nagiosadmin;clustercontrol.local;Critical alarm traps;CRITICAL;notify-service-by-email;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: SERVICE ALERT: clustercontrol.local;Critical alarm traps;CRITICAL;HARD;1;Critical - Critical alarm is 2 for cluster ID 1След като алармата се разреши, за да изпратим нормален капан, можем да изпълним следната команда:
$ snmptrap -c private -v2c 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.2 \
.1.3.6.1.4.1.57397.1.1.1.2 i 0 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Където, .1.3.6.1.4.1.57397.1.1.3.2 е равно на критично събитие завършване на тревога, а следващите OID са представяния на общия брой на текущите критични аларми (трябва да е 0 за този случай ) и съответно ID на клъстера.
На сървъра Nagios трябва да забележите, че услугата trap отново е зелена:
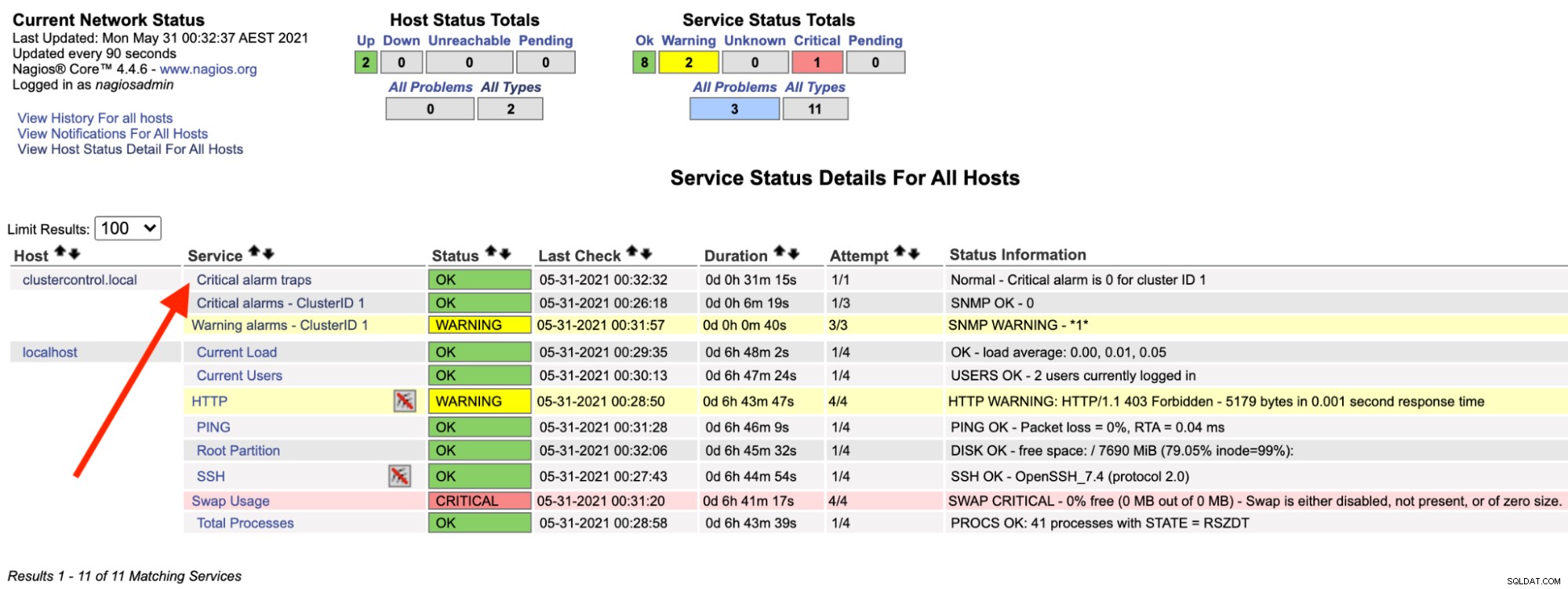
Гореното може да бъде автоматизирано с прост bash скрипт:
#!/bin/bash
# alarmtrapper.bash - SNMP trapper for ClusterControl alarms
CLUSTER_ID=1
SNMP_MANAGER=192.168.10.11
INTERVAL=10
send_critical_snmp_trap() {
# send critical trap
local val=$1
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.1 .1.3.6.1.4.1.57397.1.1.1.1 i ${val} .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
send_zero_critical_snmp_trap() {
# send OK trap
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.2 .1.3.6.1.4.1.57397.1.1.1.1 i 0 .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
while true; do
count=$(s9s alarm --list --long --cluster-id=${CLUSTER_ID} --batch | grep CRITICAL | wc -l)
[ $count -ne 0 ] && send_critical_snmp_trap $count || send_zero_critical_snmp_trap
sleep $INTERVAL
doneЗа да стартирате скрипта във фонов режим, просто направете:
$ bash alarmtrapper.bash &В този момент би трябвало да можем да видим услугата „Критични алармени капани“ на Nagios в действие, ако има повреда в нашия клъстер автоматично.
Последни мисли
В тази серия от блогове ние показахме доказателство за концепцията за това как ClusterControl може да бъде конфигуриран за наблюдение, генериране/обработка на капани и сигнали с помощта на протокол SNMP. Това също бележи началото на нашето пътуване към включване на SNMP в бъдещите ни версии. Останете на линия, тъй като ще пуснем още актуализации за тази вълнуваща функция.



