Ангажиментът за настройка на производителността може в крайна сметка да отнеме много завои, докато работите през него – всичко зависи от това какво се показва като проблем и какво ви казват данните. Някои дни попада на конкретна заявка или набор от заявки, които могат да бъдат подобрени с индекси – нови или модификации на съществуващи индекси. Една от любимите ми части от настройката е работата с индекси и докато си мислех за тази публикация, се изкуших да ознаменувам настройката на индекса като „по-лесна“ задача... но всъщност не е така.
Мисля за настройката на индекса като изкуство и наука. Трябва да опитате и да мислите като оптимизатора и трябва да разберете схемата на таблицата и заявката (или заявките), които се опитвате да настроите. И двете са базирани на данни и по този начин са в категорията на науката. Арт компонентът влиза в игра, когато мислите за другия индекси на таблицата и всички другият заявки, които включват таблицата, която може да бъде засегната от промени в индекса.
Стъпка 1:Идентифицирайте заявката и прегледайте плана
Когато идентифицирам заявка, която може да се възползва от индекс, веднага получавам нейния план. Често получавам плана за изпълнение от кеша на плана или хранилището на заявки и след това използвам SSMS, за да получа плана за изпълнение плюс статистика за времето на изпълнение (известен още като действителен план за изпълнение). Много пъти формата на тези два плана е една и съща; но това не е гаранция, поради което обичам да виждам и двете.
Планът може да има препоръка за липсващ индекс, може да има сканиране на клъстерен индекс (или сканиране на купчина, ако няма клъстериран индекс), може да използва неклъстериран индекс, но след това да има търсене за извличане на допълнителни колони. Коригирането на всеки от тези проблеми поотделно звучи доста лесно. Просто добавете липсващия индекс, нали? Ако има сканиране на клъстериран индекс или купчина, да създам индекса, който ми е необходим за заявката, и готово? Или ако има използван индекс, но той отива в таблицата, за да получи допълнителните колони, просто добавете колоните към този индекс?
Обикновено не е толкова лесно и дори когато е, все още преминавам през процеса, който описвам тук.
Стъпка 2:Определете кои таблици(и) да прегледате
Сега, когато имам своята заявка, трябва да разбера кои таблици не са индексирани правилно. В допълнение към прегледа на плана, аз също активирам статистика за IO и TIME в SSMS. Това вероятно е стара школа от моя страна, тъй като плановете за изпълнение съдържат все повече и повече информация – включително продължителност и IO номера на оператор – с всяка версия, но харесвам статистиката за IO, защото мога бързо да видя показанията за всяка таблица. За заявки, които са сложни с множество обединения, или подзаявки, или CTE, или вложени изгледи, разбирането къде се прекарват IO и/или времето в устройствата за заявки, където прекарвам времето си. Когато е възможно от този момент, вземам по-голямата, сложна заявка и я свеждам до частта, която причинява най-големия проблем.
Например, ако има заявка, която се присъединява към 10 таблици и има две подзаявки, планът (заедно с информация за IO и продължителност) ми помага да идентифицирам къде съществува проблемът. След това ще извадя тази част от заявката – проблемната таблица и може би няколко други, към които тя се присъединява – и ще се съсредоточа върху нея. Понякога това е само подзаявката, така че започвам оттам.
Стъпка 3:Вижте съществуващите индекси
След като заявката (или част от заявката) е дефинирана, се фокусирам върху съществуващите индекси за участващите таблици. За тази стъпка разчитам на версията на Кимбърли на sp_helpindex. Много предпочитам нейната версия пред стандартния sp_helpindex, защото също така изброява ВКЛЮЧЕНИ колони и дефиницията на филтъра (ако съществува такава). В зависимост от броя на индексите, които се показват за дадена таблица, често ще копирам това и го поставям в Excel, след което подреждам въз основа на ключа на индекса и след това на включените колони. Това ми позволява бързо да намирам всякакви съкращения.
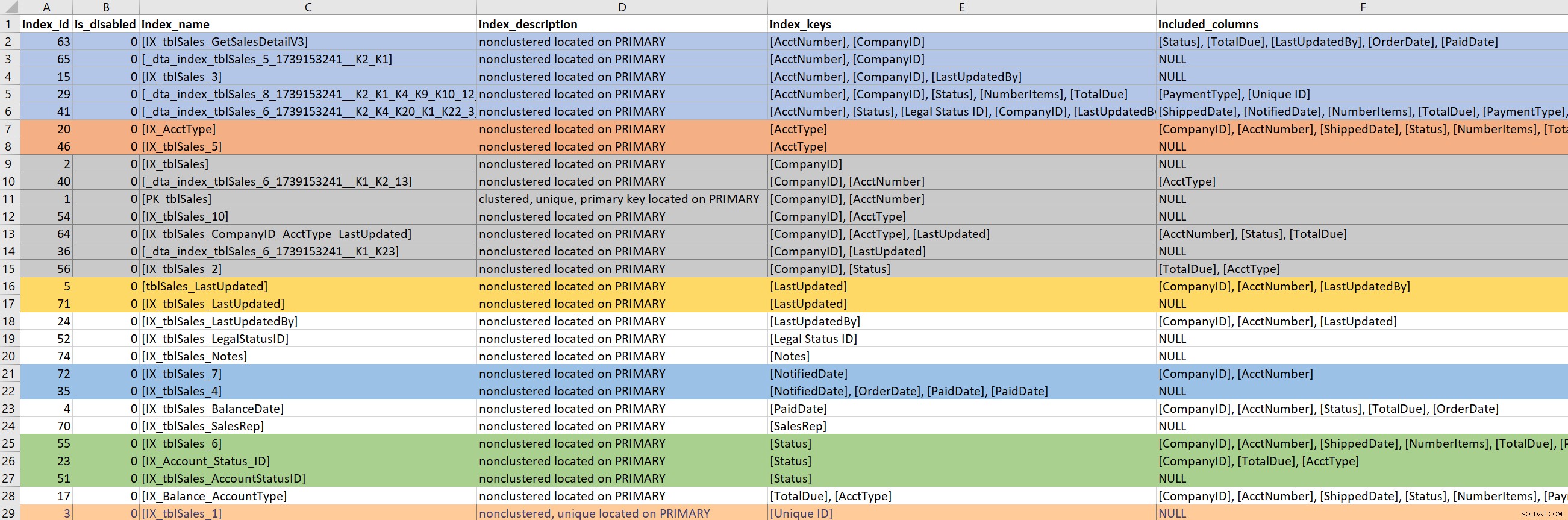
Въз основа на изходния пример по-горе, има седем индекса, които започват с CompanyID, пет, които започват с AcctNumber, и някои други потенциални съкращения. Макар че изглежда идеално да имате само един индекс, който води към определена колона (напр. CompanyID), за някои модели на заявки, това не е достатъчно.
Когато разглеждам съществуващите индекси, е много лесно да се спуснеш в заешка дупка. Гледам изхода по-горе и веднага започвам да питам защо има седем индекса, които започват с CompanyID, и искам да знам кой ги е създал, защо и за каква заявка. Но... ако моята проблемна заявка не използва CompanyID, трябва ли да ме интересува? Да… защото като цяло съм там, за да подобря производителността и ако това означава да разглеждам други индекси на таблицата по пътя, тогава така да бъде. Но тук е лесно да загубите представа за времето (и истинската цел).
Ако моята проблемна заявка се нуждае от индекс, който води към PaidDate, трябва да се справя само с един съществуващ индекс. Ако моята проблемна заявка се нуждае от индекс, който води към AcctNumber, става трудно. Когато съществуващите индекси покриват някак си заявка и търся да разширя индекс (добавя още колони) или да консолидирам (да слея два или може би три индекса в един), тогава трябва да се задълбоча.
Стъпка 4:Статистика за използване на индекс
Намирам, че много хора не улавят постоянно статистика за използване на индекса. Това е жалко, защото намирам данните за полезни, когато решавам кои индекси да се запазят и кои да се премахнат или слеят. В случай, че нямам исторически статистически данни за употребата, аз поне проверявам как изглежда използването в момента (от последното рестартиране на услугата):
SELECT
DB_NAME(ius.database_id),
OBJECT_NAME(i.object_id) [TableName],
i.name [IndexName],
ius.database_id,
i.object_id,
i.index_id,
ius.user_seeks,
ius.user_scans,
ius.user_lookups,
ius.user_updates
FROM sys.indexes i
INNER JOIN sys.dm_db_index_usage_stats ius
ON ius.index_id = i.index_id AND ius.object_id = i.object_id
WHERE ius.database_id = DB_ID(N'Sales2020')
AND i.object_id = OBJECT_ID('dbo.tblSales');
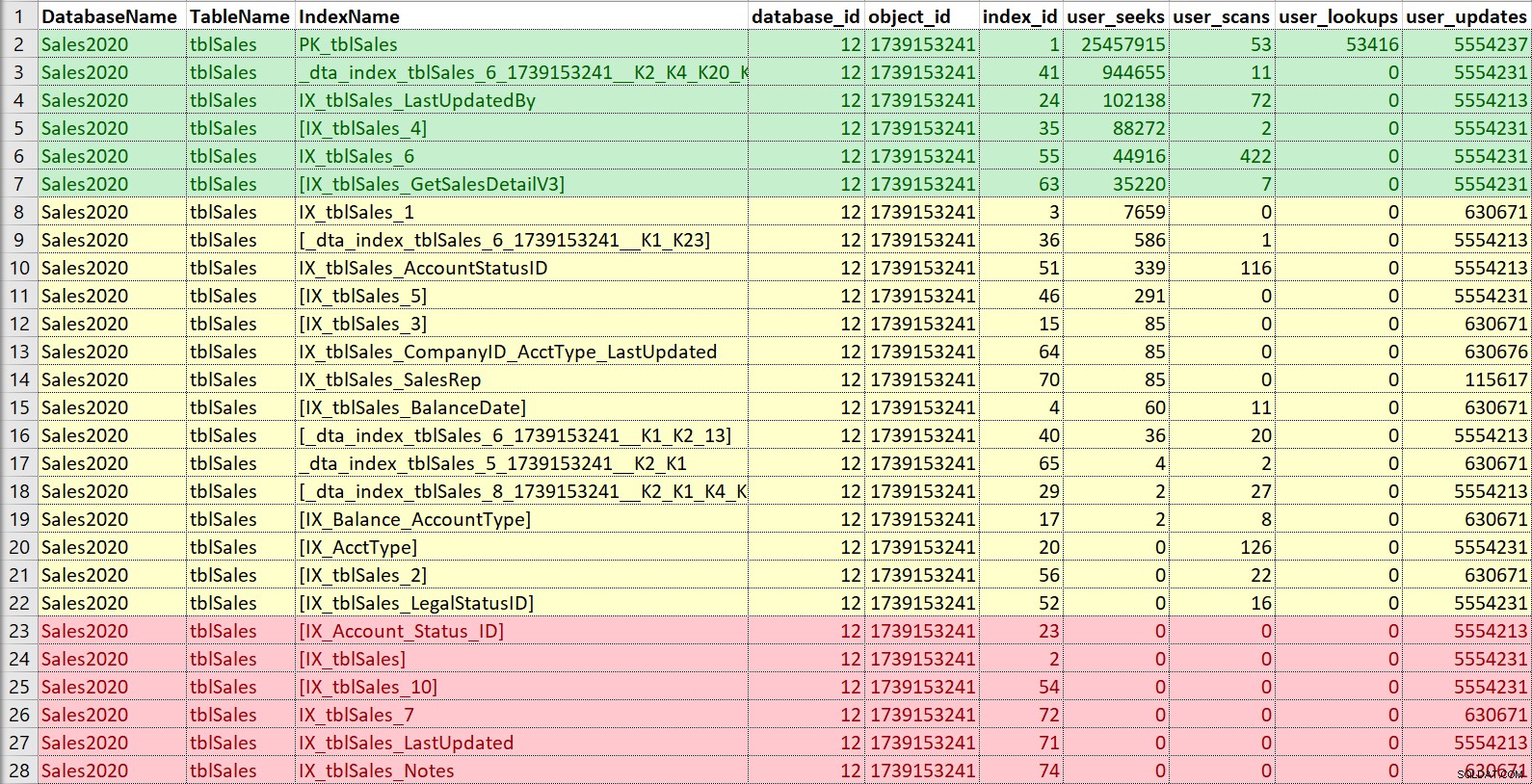
Отново обичам да поставям това в Excel, да сортирам по търсения и след това по сканиране и също така да взема под внимание актуализациите. За този пример индексите в червено са тези без търсене, сканиране или търсене... само актуализации. Това са кандидати за деактивиране и потенциално отпадане, ако наистина не се използват (отново, наличието на история на използване би помогнало тук). Индексите в зелено определено се използват, искам да ги запазя (въпреки че може би в някои случаи могат да бъдат коригирани). Тези в жълто... някои са използвани, други почти не се използват. Отново историята би била полезна тук или контекстът от други – понякога индексът може да е от решаващо значение за отчет или процес, който не се изпълнява постоянно.
Ако просто търся да променя или добавя нов индекс, срещу истинско почистване и консолидация, тогава най-вече съм загрижен за всички индекси, които са подобни на това, което искам да добавя или променя. Въпреки това ще се погрижа да посоча информацията за употреба на клиента и, ако времето позволява, ще помогна с цялостната стратегия за индексиране на таблицата.
Какво следва?
Не сме готови! Това е част 1 от моя подход към настройката на индекса и следващата ми част ще изброява останалите ми стъпки. Междувременно, ако не улавяте статистически данни за използването на индекса, това е нещо, което можете да поставите, като използвате заявката по-горе или друг вариант. Бих препоръчал да се заснемат статистически данни за употребата за всички потребителски бази данни, а не само за конкретна таблица и база данни, както направих по-горе, така че модифицирайте предиката, ако е необходимо. И накрая, като част от тази планирана работа за заснемане на тази информация в таблица, не забравяйте още една стъпка за почистване на таблицата, след като данните са били там известно време (пазя ги поне шест месеца; някои може да кажат година е необходима).