Въведение
Да разберете какъв вид инфраструктура на базата данни ви е необходима, за да съответства на изискванията за производителност, надеждност и мащабиране на вашите приложения, може да бъде трудна задача. Изборът, който правите за топологията на вашата база данни, може да повлияе на това как целият ви стек от приложения реагира на различни видове използване и какви сценарии на неуспех може да отчете. Поради това е важно да разберете възможностите си и да вземете информирано решение, което съответства на целите ви.
Има много различни начини да преминете от една база данни, която обработва всички ваши инфраструктурни нужди, към по-сложни системи. Заедно с това има много компромиси, които трябва да се вземат предвид.
В това ръководство ще представим някои от най-често срещаните модели за инфраструктура на релационна база данни и как те се привеждат в съответствие с различни модели на използване. Ще разгледаме какви предимства предлага всяка конфигурация, както и някои от недостатъците, които трябва да вземете предвид. Ще говорим и за въздействието на различните решения върху цялостната сложност на операциите ви. След като приключите, трябва да можете да вземете по-добро решение за това кои дизайни са най-подходящи за текущите ви нужди и с кои опции може да искате да експериментирате, когато нуждите ви се променят.
Вертикално мащабиране
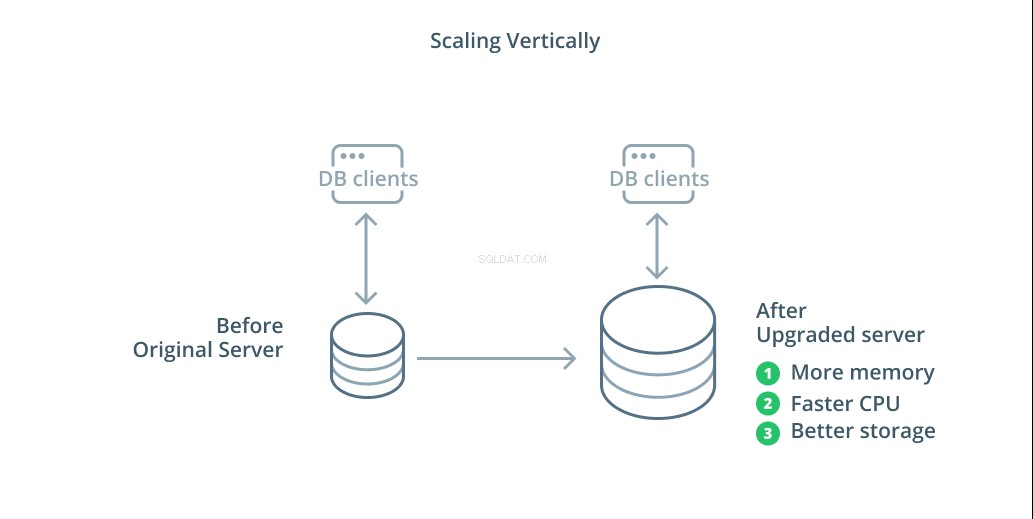
Най-простият начин за мащабиране на система от база данни е вертикалното мащабиране. Вертикално мащабиране , наричан още увеличаване на мащаба , означава добавяне на капацитет към сървъра, който управлява вашата база данни. Чрез увеличаване на процесорната мощност, разпределението на паметта или капацитета за съхранение можете да увеличите производителността и обема, с които може да се справи една система от база данни, без да увеличавате сложността на системата като цяло.
Като общо правило, мащабирането на вашата база данни е добра първа стъпка, тъй като увеличава възможностите на вашата база данни, без да засяга топологията на вашата инфраструктура. Увеличаването обикновено също е доста просто, тъй като машина с по-голям капацитет може да бъде конфигурирана като последовател на репликация, докато не бъде синхронизирана и след това може да се задейства отказ, за да стане новият основен сървър.
Увеличаването обаче има своите ограничения, тъй като количеството ресурси, които могат разумно да бъдат разпределени на една машина, е ограничено. Той също така представлява единична точка на отказ, ако не са конфигурирани последователи на репликация да поемат, когато възникнат проблеми. Тези опасения се решават от някои от другите опции за мащабиране.
Разделяне на отговорността за командна заявка (CQRS) и реплики само за четене
Другият основен начин за мащабиране на вашата инфраструктура на база данни е мащабирането. Намаляване означава, че вместо да увеличавате капацитета на един сървър, вие увеличавате броя на сървърите, предназначени за обслужване на конкретна нужда. Така че добавяте капацитет, като добавяте допълнителни машини към вашата инфраструктура.
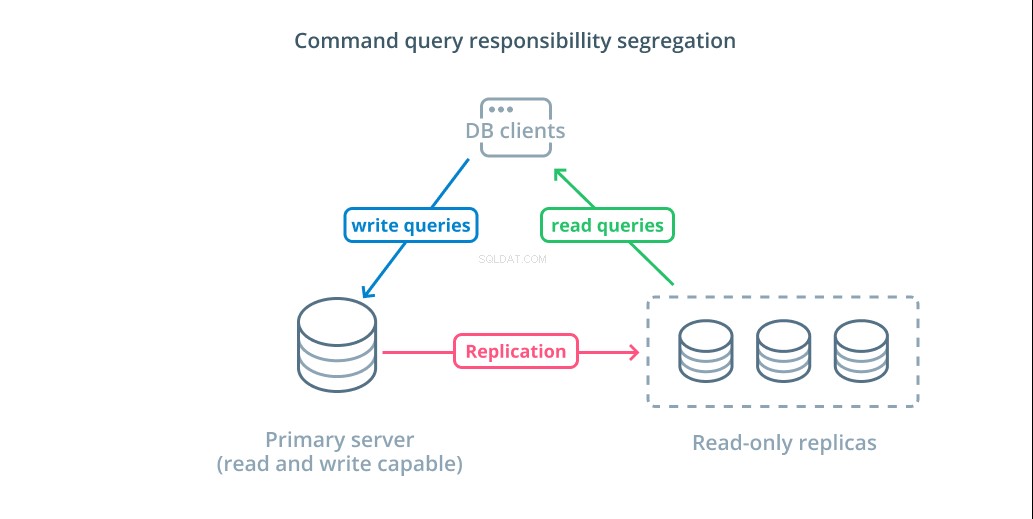
Разделяне на отговорността за командна заявка (CQRS) е термин, използван за описване на добавяне на логика за отделяне на заявки, които мутират данни (записи за запис) от тези, които не го правят (заявки за четене). Това ви позволява да насочвате тези различни категории заявки към различни хостове, за да помогнете за разпределението на натоварването.
Най-основната инфраструктура, която да се възползва от този дизайн, е първичен сървър, който може да приема заявки за четене и запис, комбинирани с един или повече сървъри реплики, следващи основния сървър, който може да приема заявки за четене. Този дизайн е подходящ за модели на използване на приложения, които са натоварени с четене, тъй като операциите за четене могат да се обработват от всеки от сървърите на базата данни.
Освен това, тази система осигурява известна излишък на вашата архитектура, тъй като системата ще продължи да функционира, ако някой от сървърите изпадне. Ако един последовател падне, заявките за четене могат да бъдат насочени към другите сървъри. Ако основният сървър се повреди, един от последователите на репликата може да бъде повишен да приема заявки за писане.
Многоосновна репликация
Докато използването на CQRS с реплики само за четене ви помага да адресирате по-голям брой заявки за четене, това не оказва значително влияние върху производителността на запис на вашата инфраструктура. За да увеличите броя на записванията, които вашата архитектура може да поеме, трябва да помислите дали можете да приемете дизайн с много първична репликация.
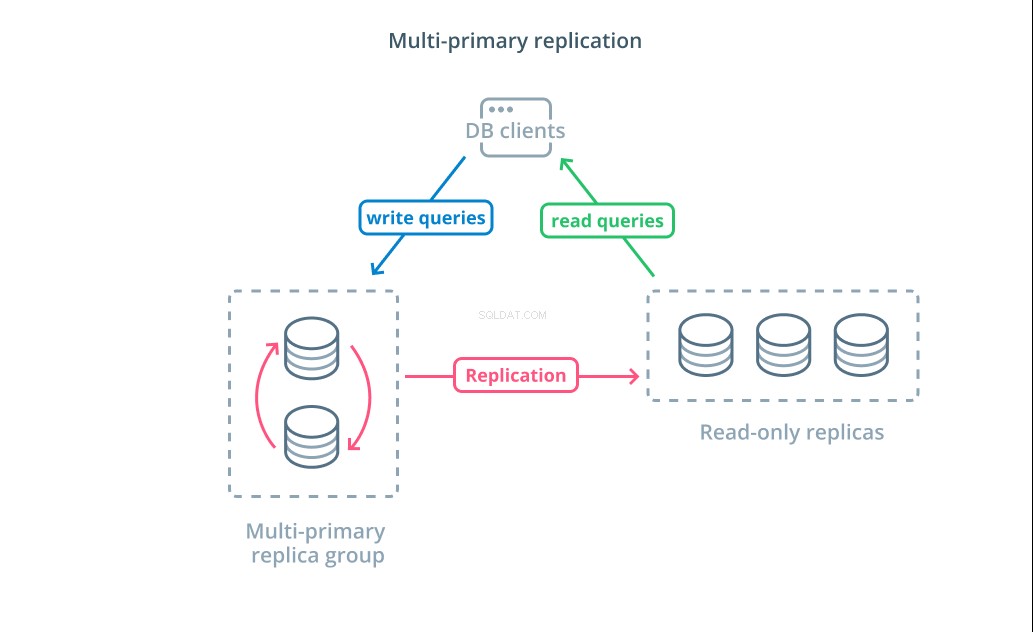
Много първична репликация е форма на репликация, при която множество сървъри могат да приемат заявки за запис. Някои системи са конфигурирани така, че всеки сървър да може да обработва заявки за запис, докато други са проектирани така, че основна група от първични сървъри да обработва записите с по-голям брой последователи само за четене. Независимо от внедряването, многоосновната репликация увеличава броя на сървърите, които отговарят за заявките за писане.
Въпреки че този дизайн звучи идеално в началото, има някои големи предизвикателства, които пречат на това да бъде широко разпространен модел. Докато множество сървъри могат да обработват заявки за запис, те все пак трябва да координират, за да репликират промените между техните сървъри и да разрешават конфликти в промените в данните. Това може да доведе или до дълги времена за реакция при договаряне на конфликти, или до възможност за непоследователни данни.
Всяка система избира свой собствен подход за справяне с тези предизвикателства. Това е демонстрация на CAP теорема — изявление, описващо взаимодействието между последователност, наличност и толерантност на дялове в разпределените системи — в действие. Някои системи предлагат по-слаби гаранции за последователност за поддържане на наличност, докато други бази данни отказват да приемат промени, ако техните партньори не могат да координират транзакцията по време на записа. Изборът на подхода, който най-добре отговаря на вашите нужди, е важен фактор при вземането на решение между различни реализации.
Кеширане на заявки за четене
Докато използването на реплики само за четене е начин за увеличаване на наличните бази данни, които могат да отговарят на заявки за четене, то не подобрява основната производителност на заявки на сложни операции за четене. Все още се очаква един от сървърите да изпълнява операцията за четене всеки път, когато бъде направена заявка, дори ако резултатите са идентични с предишното търсене.
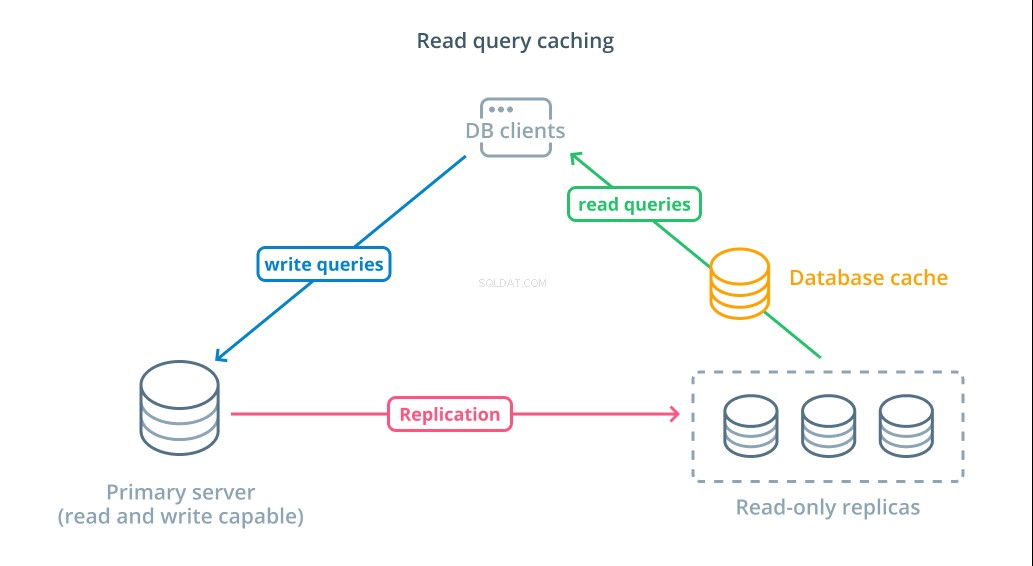
За да намалите времето за отговор, кеширане на заявка за четене слой може да бъде въведен. Добавянето на кеш между клиентите на вашата база данни и самите бази данни може значително да намали времето за заявка за често срещани заявки. Приложението може да поиска резултати за четене от кеша и да ги получи почти веднага, ако има такива. В случаите, когато резултатите не се намират в кеша, те се извличат от самата база данни и се добавят към кеша за следващия път.
Конфигурирането на кеширане по този начин е невероятно ефективно за сценарии, при които няма вероятност данните да се променят всеки път, когато се направи заявка. Това е особено полезно за скъпи заявки за четене, които консултират множество таблици и включват сложни операции за свързване. Тези резултати могат да бъдат изпълнени веднъж и след това запазени за бъдещи заявки.
В случаите, когато данните се променят по-бързо, кешът за четене може да не помогне почти толкова. В зависимост от конфигурираното поведение, кешовете рискуват да върнат остарели данни в тези ситуации и трябва да се прилагат обмислени стратегии за невалидиране на кеша, за да се премахнат остарели данни от кеша при промяна.
Споделяне на данни
Досега проектите, които обсъждахме, имат сегментирани компоненти на базата данни въз основа на това дали отговарят на заявки за писане или не. Въпреки това, друг начин за разделяне на отговорността е да се раздели действителният набор от данни на множество части.
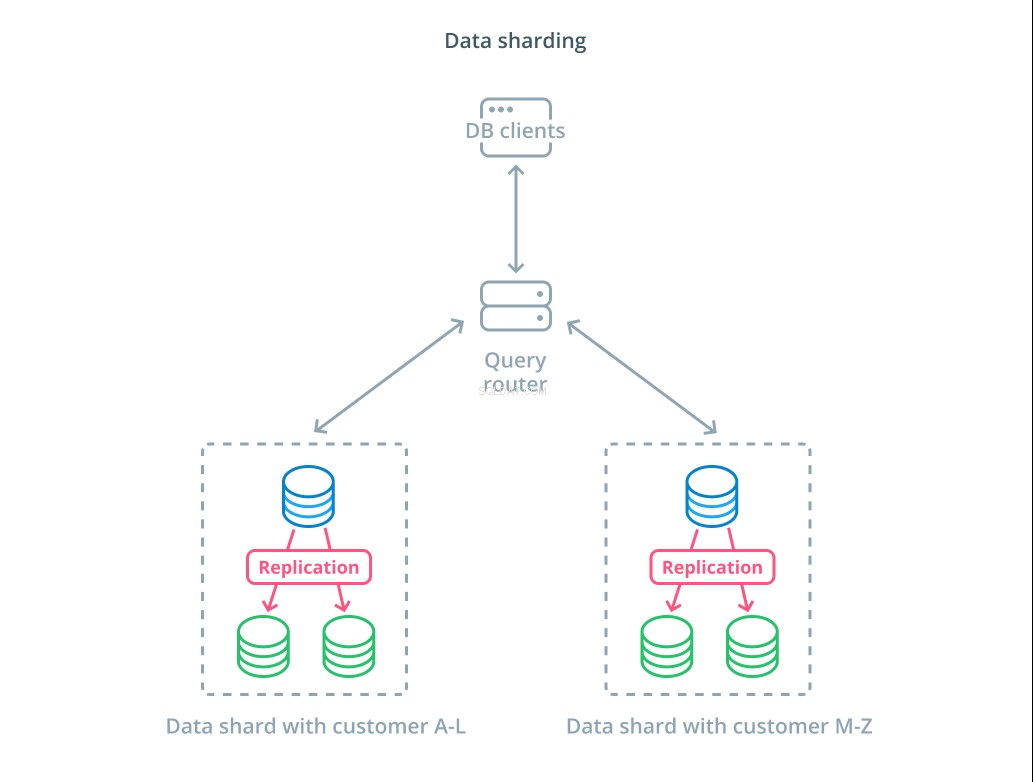
Разделяне е процесът на разбиване на логически набор от данни на по-малки подмножества, за да се разпредели управлението им на различни машини. Всеки сървър на база данни обработва само част от данните и е въведена механика за маршрутизиране, която разбира кои машини са отговорни за какви части от данни.
Обикновено разделянето се извършва в сценарии, при които работата с целия набор от данни наведнъж е ненужна или необичайна. Наборът от данни се сегментира въз основа на стойността на всеки запис за конкретен ключ, известен като ключ за споделяне . Например, можете ръчно да разделите данни въз основа на местоположението на клиентите. Можете също да разделите автоматично с помощта на алгоритъм за хеширане, за да определите кои възли трябва да обработват кои ключове. Това може да помогне на вашата система да избегне небалансирано разпределение в случаите, когато ключовото пространство на сегмента е неравномерно разпределено.
Разделянето внася доста сложност в системите за данни и не е подходящо за всички сценарии. Операциите, които взаимодействат с множество фрагменти, ще претърпят значителни наказания за производителност, тъй като извличат резултати от всеки член. Това може да се случи за обобщени заявки или ако конкретният ключ на сегмента не е известен предварително. Освен това, неравномерното разпределение на фрагменти може също да причини неефективност и тесни места, които трябва да бъдат отстранени чрез повторно балансиране на разпределението на целия набор от данни.
Децентрализирано функционално управление на данни
Вместо да се разделят стойностите на набор от данни на множество сегменти, в много случаи е по-разумно да се използват различни бази данни за различни функционални цели. Например, ако имате услуга за сметки и услуга за продукти, наличието на специални бази данни, които съвпадат с всеки проблем, може да ви помогне да мащабирате различни компоненти независимо.
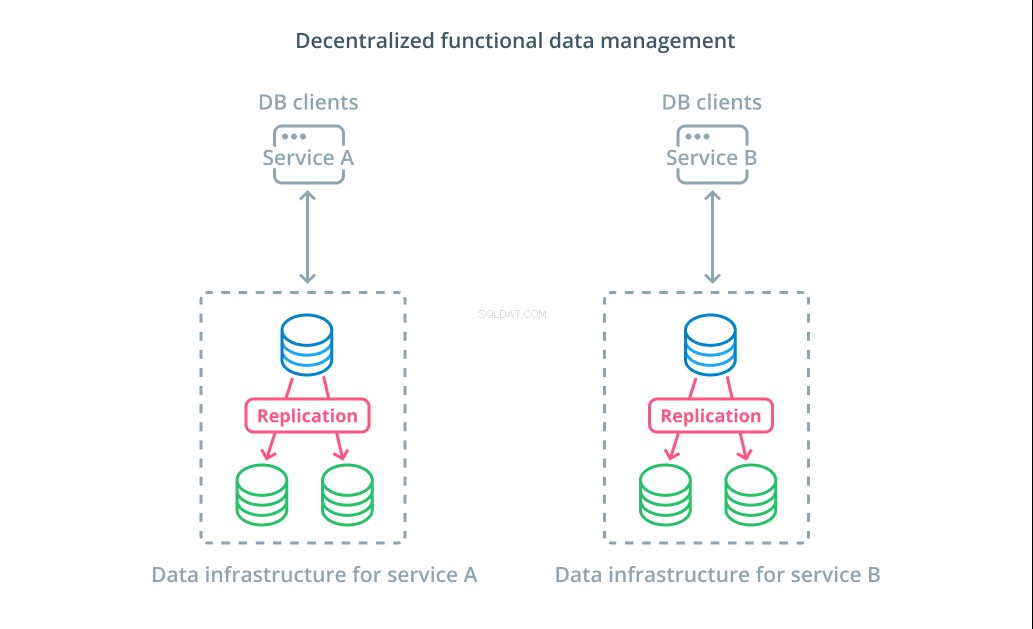
Функционалното управление на данни ви позволява да разбиете инфраструктурата на вашата база данни и да управлявате всяка част според нуждите на нейните клиенти. Всяка функционална част може да бъде мащабирана с помощта на всяка стратегия, която има най-голям смисъл. Позволява ви да проектирате схемата на базата данни и да я разположите на място, което най-добре съответства на моделите на конкретен случай на използване, вместо да изисква тя да обслужва цялата организация.
За много организации тази стратегия има важни предимства, които надхвърлят свойствата на действителните системи. Децентрализирането на управлението на данни може да позволи на по-малки екипи да притежават свои собствени данни, без да координират промените с други страни. Той се съчетава добре с целенасоченото разделяне на проблемите, насърчавано от архитектурите на приложения, ориентирани към микросервизи.
Безсървърни бази данни
Различните компромиси, които трябва да оцените, и количеството инфраструктура, която може да се очаква да управлявате за правилното мащабиране, могат да бъдат огромни за много хора. Една от възможностите за разтоварване на тази сложност е да се възползвате от услугите за бази данни, които управляват инфраструктура и мащабират вместо вас.
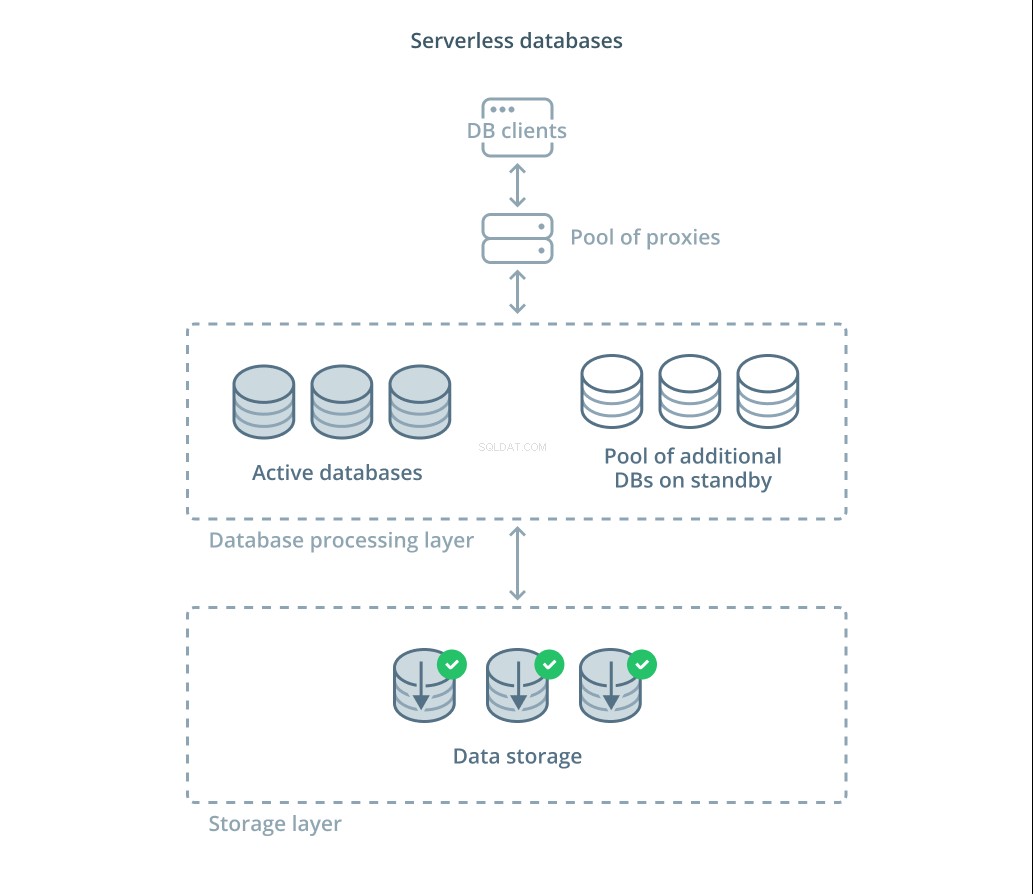
Безсървърни бази данни са категория услуги, които отделят съхранението на данни от обработката на данни за лесно мащабиране на ресурсите в отговор на промените в търсенето.
Слоят за съхранение на данни е отговорен за поддържането на действителните данни, управлявани от системата. В предната част на този слой е разположено ниво от мащабируеми блокове за обработка на база данни, за да обработват действителната обработка на заявки спрямо наборите от данни. Броят на активните модули във всеки даден момент е обвързан директно с текущото използване, така че повече ресурси се разпределят при пикове на търсенето и процесорните модули се връщат в режим на готовност, ако нещата затихнат.
Заявките се препращат към процесорите на базата данни чрез прокси за маршрутизиране, което знае как да препраща заявки към активните възли и кога да изисква допълнителни ресурси.
Базите данни без сървър имат много от същите свойства като традиционните услуги за бази данни, които прилагат функции за автоматично мащабиране. И двете могат да разпределят капацитет въз основа на търсенето. Базите данни без сървър обаче ви позволяват да отделите разходите за съхранение от разходите за обработка и могат да намалят обработката до нула, когато не е необходима. Освен това решенията без сървър обикновено могат да се разширят много по-бързо, за да отговорят на търсенето в сравнение с автоматичното мащабиране, предлагано от традиционните предложения.
Въпреки че бази данни без сървър може да са подходящи за някои, те не са сребърен куршум. В случаите, когато процесорите на базата данни бяха намалено до нула, може да има закъснения при обработката отново поради студени стартирания. Освен това, прехвърлянето на връзки между различните компоненти в стека на база данни без сървър може да доведе до допълнителна латентност.
Безсървърните платформи за бази данни също могат да бъдат трудни от гледна точка на операциите. Внедряването и промените в базата данни могат да бъдат по-трудни за разсъждение и наблюдение. Локалната среда за разработка също може да се различава значително от производствената среда поради динамичното състояние на системата за бази данни. И накрая, както при всяка друга облачна услуга, използването на бази данни без сървър може потенциално да ви изложи на опасност от блокиране на доставчика. Важно е да запомните тези компромиси, когато проектирате около платформа без сървър.
Заключение
Има много начини за проектиране, внедряване и управление на вашата инфраструктура на базата данни, тъй като изискванията на приложението ви стават по-сериозни. Всяко решение има своите силни страни и ограничения, които е важно да разберете, когато се опитвате да намерите подходящо за вашата среда.
Научаването за това как инфраструктурата на базата данни влияе върху наличността, производителността и целостта на вашите данни ви позволява да избягвате скъпи грешки и реализации, които не предоставят гаранциите, от които се нуждаете. Ако един от горните дизайни не покрива вашите изисквания, може да успеете да комбинирате някои от елементите на различни подходи, за да получите допълнителни предимства.
Ако искате да научите повече за общите модели, разгледани по-горе, ето някои допълнителни ресурси, които може да искате да разгледате:
- Увеличаване срещу мащабиране
- Разделяне на отговорността за командна заявка
- Много първична репликация
- Кеширане на заявки за четене
- Споделяне на данни
- Децентрализирано управление на данни
- Безсървърни бази данни