Прокси слоят може да бъде доста полезен за увеличаване на наличността на нивото на вашата база данни. Това може да намали количеството код от страната на приложението за справяне с неуспехи в базата данни и промени в топологията на репликация. В тази публикация в блога ще обсъдим как да настроим HAProxy да работи върху PostgreSQL.
На първо място - HAProxy работи с бази данни като прокси на мрежовия слой. Няма разбиране на основната, понякога сложна топология. Всичко, което HAProxy прави, е да изпраща пакети по кръгова система до дефинирани бекендове. Той не проверява пакети, нито разбира протокола, в който приложенията говорят с PostgreSQL. В резултат на това няма начин HAProxy да приложи разделяне на четене/запис на един порт - това ще изисква синтактичен анализ на заявките. Докато приложението ви може да разделя прочитания от записите и да ги изпраща до различни IP адреси или портове, можете да приложите R/W разделяне, като използвате два бекенда. Нека да разгледаме как може да се направи.
Конфигурация на HAProxy
По-долу можете да намерите пример за два PostgreSQL бекенда, конфигурирани в HAProxy.
listen haproxy_10.0.0.101_3307_rw
bind *:3307
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string master\ is\ running
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 check
listen haproxy_10.0.0.101_3308_ro
bind *:3308
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running.
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 checkКакто виждаме, те използват портове 3307 за запис и 3308 за четене. В тази настройка има три сървъра - един активен и две резервни реплики. Важното е, че tcp-check се използва за проследяване на здравето на възлите. HAProxy ще се свърже с порт 9201 и очаква да види върнат низ. Здравите членове на бекенда ще върнат очакваното съдържание, тези, които не върнат низа, ще бъдат маркирани като недостъпни.
Настройка на Xinetd
Тъй като HAProxy проверява порт 9201, нещо трябва да го слуша. Можем да използваме xinetd, за да слушаме там и да изпълняваме някои скриптове вместо нас. Примерна конфигурация на такава услуга може да изглежда така:
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITED
}Трябва да сте сигурни, че сте добавили реда:
postgreschk 9201/tcpкъм /etc/services.
Xinetd стартира postgreschk скрипт, който има съдържание като по-долу:
#!/bin/bash
#
# This script checks if a PostgreSQL server is healthy running on localhost. It will
# return:
# "HTTP/1.x 200 OK\r" (if postgres is running smoothly)
# - OR -
# "HTTP/1.x 500 Internal Server Error\r" (else)
#
# The purpose of this script is make haproxy capable of monitoring PostgreSQL properly
#
export PGHOST='10.0.0.101'
export PGUSER='someuser'
export PGPASSWORD='somepassword'
export PGPORT='5432'
export PGDATABASE='postgres'
export PGCONNECT_TIMEOUT=10
FORCE_FAIL="/dev/shm/proxyoff"
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"
return_ok()
{
echo -e "HTTP/1.1 200 OK\r\n"
echo -e "Content-Type: text/html\r\n"
if [ "$1x" == "masterx" ]; then
echo -e "Content-Length: 56\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL master is running.</body></html>\r\n"
elif [ "$1x" == "slavex" ]; then
echo -e "Content-Length: 55\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL slave is running.</body></html>\r\n"
else
echo -e "Content-Length: 49\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is running.</body></html>\r\n"
fi
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 0
}
return_fail()
{
echo -e "HTTP/1.1 503 Service Unavailable\r\n"
echo -e "Content-Type: text/html\r\n"
echo -e "Content-Length: 48\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is *down*.</body></html>\r\n"
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 1
}
if [ -f "$FORCE_FAIL" ]; then
return_fail;
fi
# check if in recovery mode (that means it is a 'slave')
SLAVE=$(psql -qt -c "$SLAVE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $SLAVE | egrep -i "(t|true|on|1)" 2>/dev/null >/dev/null; then
return_ok "slave"
fi
# check if writable (then we consider it as a 'master')
READONLY=$(psql -qt -c "$WRITABLE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $READONLY | egrep -i "(f|false|off|0)" 2>/dev/null >/dev/null; then
return_ok "master"
fi
return_ok "none";Логиката на скрипта е следната. Има две заявки, които се използват за откриване на състоянието на възела.
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"Първият проверява дали PostgreSQL се възстановява - ще бъде „false“ за активния сървър и „true“ за сървърите в режим на готовност. Вторият проверява дали PostgreSQL е в режим само за четене. Активният сървър ще се върне „изключен“, докато сървърите в режим на готовност ще се върнат „включени“. Въз основа на резултатите скриптът извиква функцията return_ok() с правилен параметър („главен“ или „подчинен“, в зависимост от това какво е открито). Ако заявките са неуспешни, ще се изпълни функция „return_fail“.
Функцията Return_ok връща низ въз основа на аргумента, който й е бил предаден. Ако хостът е активен сървър, скриптът ще върне „PostgreSQL master is running“. Ако е в режим на готовност, върнатият низ ще бъде:„PostgreSQL slave работи“. Ако състоянието не е ясно, то ще върне:„PostgreSQL работи“. Това е мястото, където цикълът свършва. HAProxy проверява състоянието, като се свързва с xinetd. Последният стартира скрипт, който след това връща низ, който HAProxy анализира.
Както може би си спомняте, HAProxy очаква следните низове:
tcp-check expect string master\ is\ runningза бекенда за запис и
tcp-check expect string is\ running.за бекенда само за четене. Това прави активния сървър единственият достъпен хост в бекенда за запис, докато в бекенда за четене могат да се използват както активни, така и резервни сървъри.
PostgreSQL и HAProxy в ClusterControl
Настройката по-горе не е сложна, но отнема известно време, за да я настроите. ClusterControl може да се използва, за да настроите всичко това вместо вас.
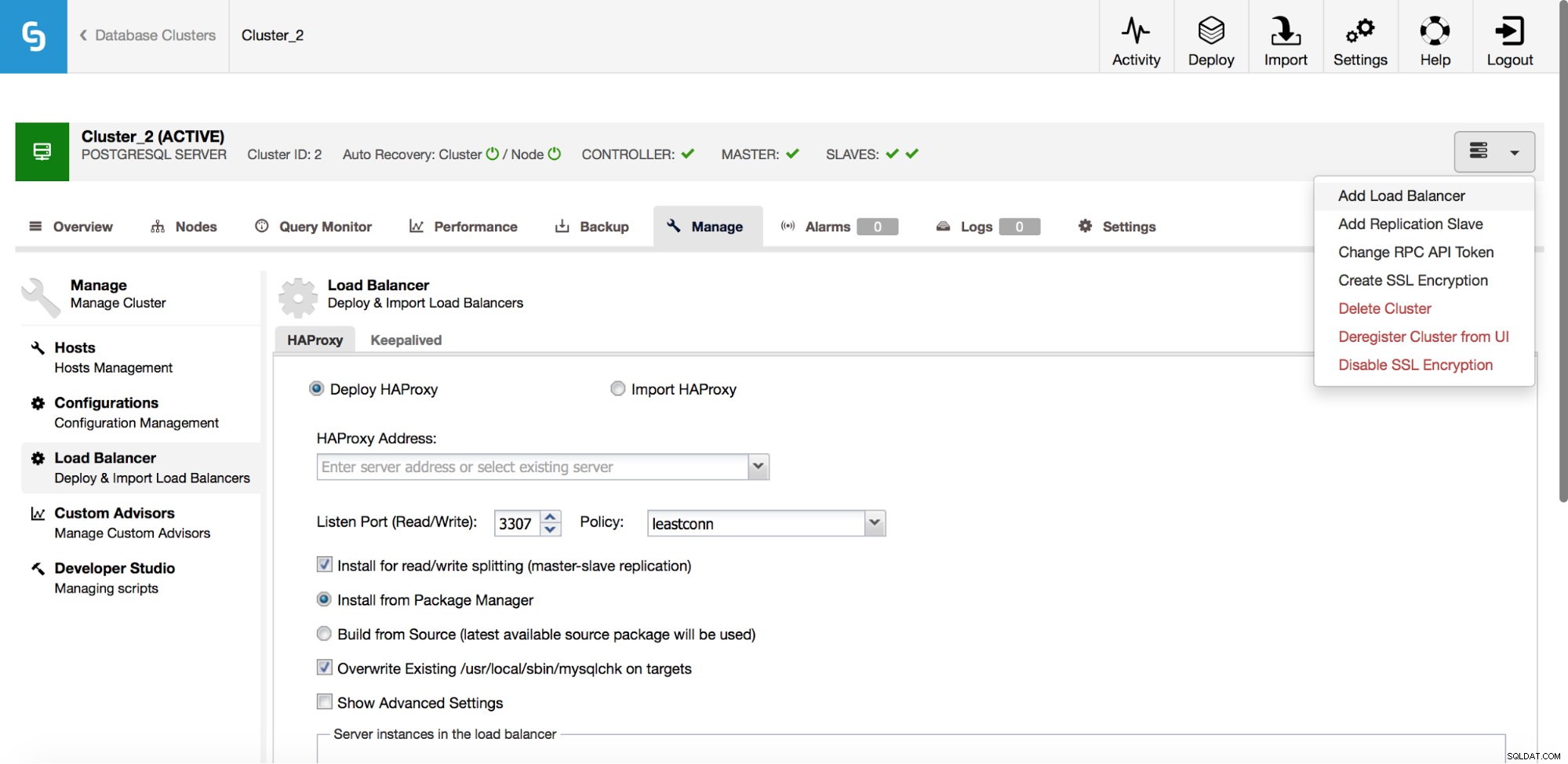
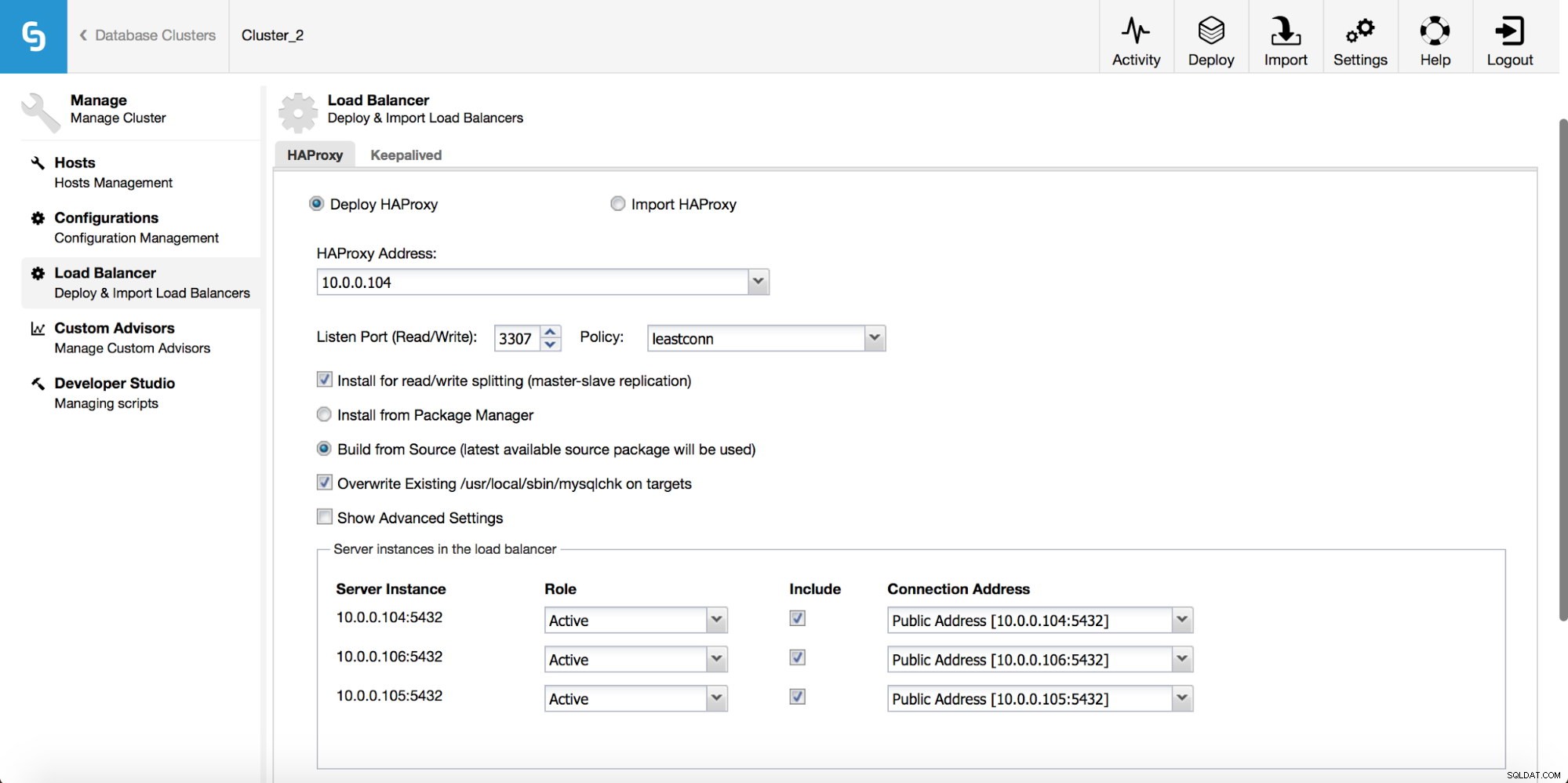
В падащото меню за задания на клъстер имате опция да добавите балансьор на натоварване. След това се показва опция за разгръщане на HAProxy. Трябва да попълните мястото, където искате да го инсталирате, и да вземете някои решения:от хранилищата, които сте конфигурирали на хоста или най-новата версия, компилирана от изходния код. Ще трябва също да конфигурирате кои възли в клъстера искате да добавите към HAProxy.
След като HAProxy екземплярът бъде разгърнат, можете да получите достъп до някои статистически данни в раздела „Възли“:
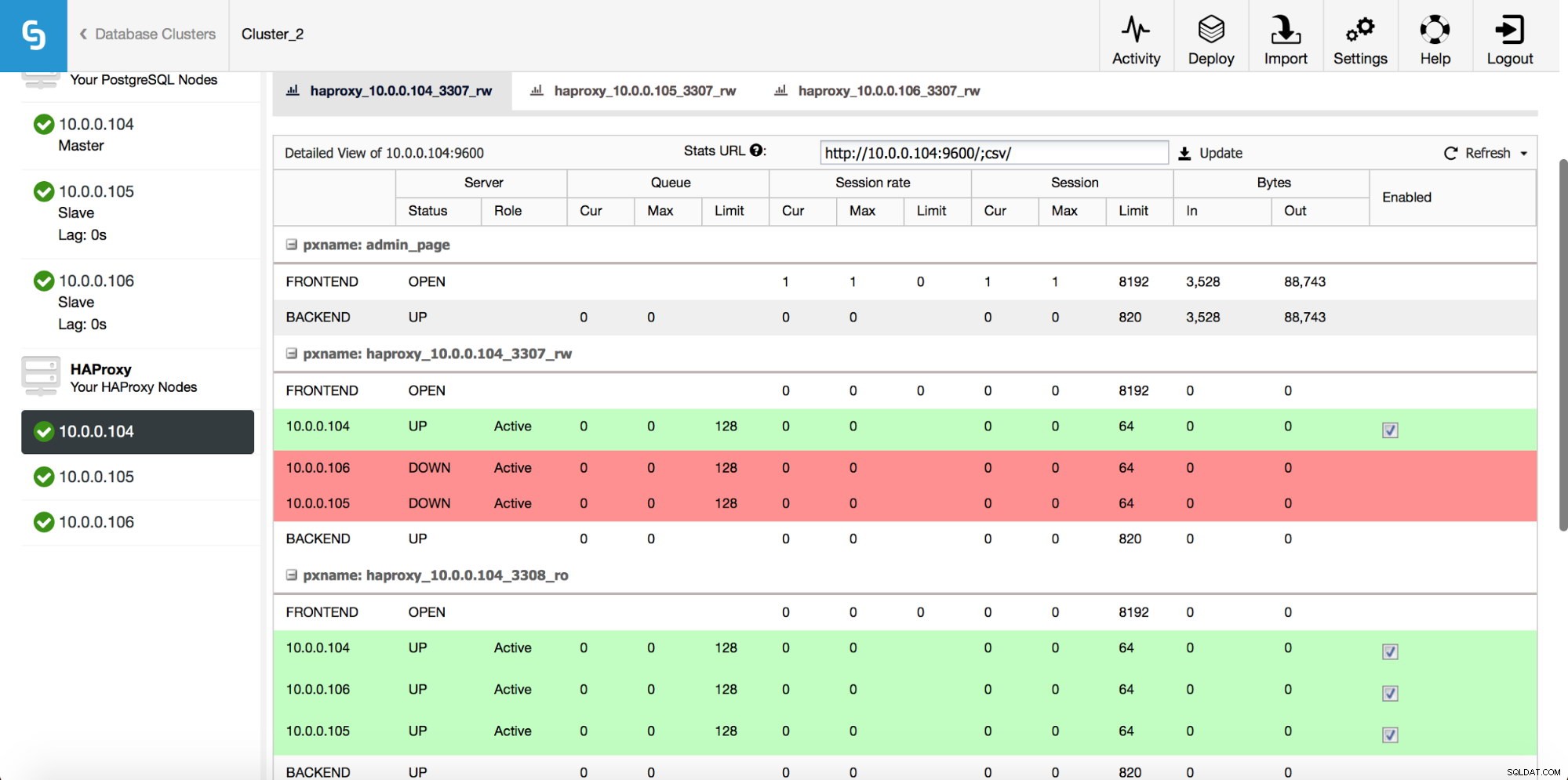
Както виждаме, за R/W бекенда, само един хост (активен сървър) е маркиран като up. За бекенда само за четене всички възли са нагоре.
Изтеглете Бялата книга днес Управление и автоматизация на PostgreSQL с ClusterControl Научете какво трябва да знаете, за да внедрите, наблюдавате, управлявате и мащабирате PostgreSQLD Изтеглете Бялата книгаKeepalived
HAProxy ще седи между вашите приложения и екземпляри на база данни, така че ще играе централна роля. За съжаление може да се превърне и в единична точка на отказ, ако се провали, няма да има маршрут към базите данни. За да избегнете подобна ситуация, можете да разположите множество екземпляри на HAProxy. Но тогава въпросът е - как да решим към кой прокси хост да се свържем. Ако сте разположили HAProxy от ClusterControl, това е толкова просто, колкото да стартирате друго задание „Добавяне на Load Balancer“, като този път разгръщате Keepalived.
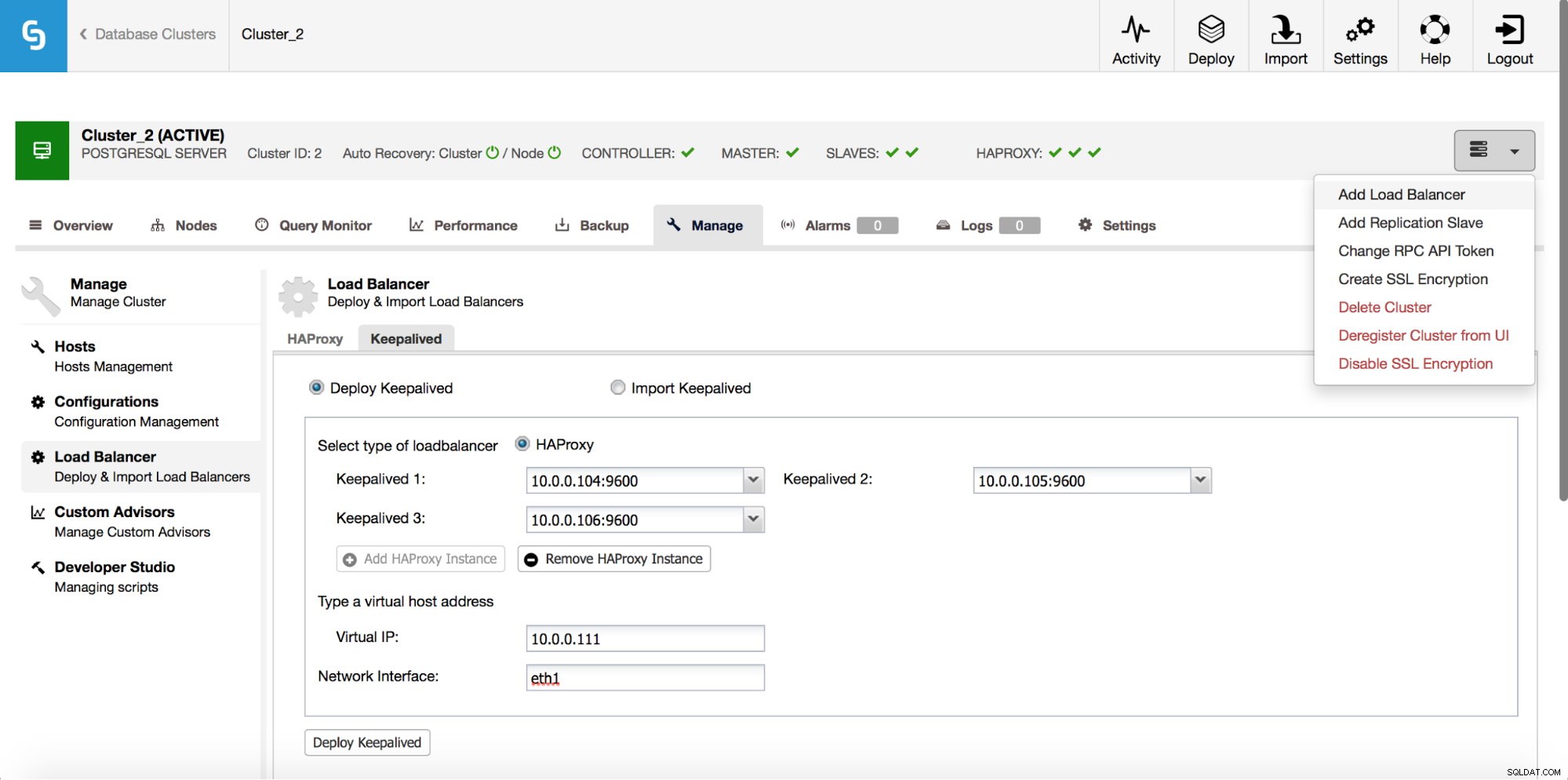
Както можем да видим на екранната снимка по-горе, можете да изберете до три HAProxy хоста и Keepalived ще бъде разположен върху тях, като следи състоянието им. На един от тях ще бъде присвоен виртуален IP (VIP). Вашето приложение трябва да използва този VIP за свързване с базата данни. Ако „активният“ HAProxy стане недостъпен, VIP ще бъде преместен на друг хост.
Както видяхме, е доста лесно да се разгърне пълен стек с висока наличност за PostgreSQL. Опитайте и ни уведомете, ако имате обратна връзка.