Обработката с NULL е един от най-трудните аспекти на моделирането на данни и манипулирането на данни с SQL. Нека започнем с факта, че опитът да се обясни точно какво е NULL не е тривиално само по себе си. Дори сред хора, които имат добро разбиране на релационната теория и SQL, ще чуете много силни мнения както за, така и против използването на NULL във вашата база данни. Харесвате или не, като практикуващ база данни често трябва да се справяте с тях и като се има предвид, че NULL добавят сложност към писането на вашия SQL код, добра идея е да направите приоритет да ги разберете добре. По този начин можете да избегнете ненужни грешки и клопки.
Тази статия е първата от поредицата за NULL сложности. Започвам с отразяване на това какво представляват NULL и как се държат при сравнения. След това обхващам несъответствията на третирането с NULL в различни езикови елементи. И накрая, разглеждам липсващите стандартни функции, свързани с обработката на NULL в T-SQL, и предлагам алтернативи, които са налични в T-SQL.
По-голямата част от покритието е от значение за всяка платформа, която прилага диалект на SQL, но в някои случаи споменавам аспекти, които са специфични за T-SQL.
В моите примери ще използвам примерна база данни, наречена TSQLV5. Тук можете да намерите скрипта, който създава и попълва тази база данни, както и нейната диаграма за ER тук.
NULL като маркер за липсваща стойност
Нека започнем с разбирането какво са NULL. В SQL NULL е маркер или заместител за липсваща стойност. Това е опит на SQL да представи във вашата база данни реалност, където определена стойност на атрибута понякога присъства, а понякога липсва. Например, да предположим, че трябва да съхранявате данни за служителите в таблица на служителите. Имате атрибути за име, бащино и фамилно име. Атрибутите firstname и lastname са задължителни и затова ги дефинирате като непозволяващи NULL. Атрибутът средно име не е задължителен и затова го дефинирате като разрешаващ NULL.
Ако се чудите какво има да каже релационният модел за липсващите стойности, създателят на модела Едгар Ф. Код наистина вярваше в тях. Всъщност той дори направи разлика между два вида липсващи стойности:липсващи, но приложими (маркер A-стойности) и липсващи, но неприложими (маркер I-стойности). Ако вземем атрибута средно име като пример, в случай, когато служител има второ име, но от съображения за поверителност избере да не споделя информацията, ще използвате маркера A-стойности. В случай, когато служител изобщо няма второ име, бихте използвали маркера I-Values. Тук същият атрибут понякога може да бъде уместен и присъстващ, понякога липсва, но е приложим, а понякога липсва, но е неприложим. Други случаи биха могли да бъдат по-ясни, като поддържат само един вид липсващи стойности. Например, да предположим, че имате таблица за поръчки с атрибут, наречен shippeddate, съдържащ датата на доставка на поръчката. Поръчка, която е изпратена, винаги ще има настояща и подходяща дата на доставка. Единственият случай за липса на известна дата на доставка би бил за поръчки, които все още не са били изпратени. Така че тук трябва да присъства или съответна стойност на датата на доставка, или трябва да се използва маркерът I-values.
Дизайнерите на SQL избраха да не навлизат в разграничението между приложими и неприложими липсващи стойности и ни предоставиха NULL като маркер за всякакъв вид липсваща стойност. В по-голямата си част SQL е проектиран да приеме, че NULL представляват липсващи, но приложими видове липсваща стойност. Следователно, особено когато използването на NULL е като заместител за неприложима стойност, обработката на SQL NULL по подразбиране може да не е тази, която възприемате като правилна. Понякога ще трябва да добавите изрична логика за обработка NULL, за да получите лечението, което смятате за правилно за вас.
Като най-добра практика, ако знаете, че даден атрибут не трябва да позволява NULL, уверете се, че сте го наложили с ограничение NOT NULL като част от дефиницията на колоната. Има няколко важни причини за това. Една от причините е, че ако не наложите това, в един или друг момент ще стигнат NULL. Това може да е резултат от грешка в приложението или импортиране на лоши данни. Използвайки ограничение, вие знаете, че NULL никога няма да стигнат до таблицата. Друга причина е, че оптимизаторът оценява ограничения като NOT NULL за по-добра оптимизация, избягване на ненужна работа при търсене на NULL и разрешаване на определени правила за трансформация.
Сравнения, включващи NULL числа
Има известна сложност в оценката на предикатите от SQL, когато са включени NULL. Първо ще разгледам сравненията, включващи константи. По-късно ще разгледам сравненията, включващи променливи, параметри и колони.
Когато използвате предикати, които сравняват операндите в елементи на заявка като WHERE, ON и HAVING, възможните резултати от сравнението зависят от това дали някой от операндите може да бъде NULL. Ако знаете със сигурност, че нито един от операндите не може да бъде NULL, резултатът от предиката винаги ще бъде TRUE или FALSE. Това е известно като двузначна предикатна логика или накратко, просто двузначна логика. Такъв е случаят, например, когато сравнявате колона, която е дефинирана като не позволяваща NULL, с друг операнд, различен от NULL.
Ако някой от операндите в сравнението може да е NULL, да речем, колона, която позволява NULL, като се използват както оператори за равенство (=), така и за неравенство (<>,>, <,>=, <=и т.н.), вие сте сега на милостта на тризначната предикатна логика. Ако в дадено сравнение двата операнда са стойности, различни от NULL, все пак получавате TRUE или FALSE като резултат. Въпреки това, ако някой от операндите е NULL, получавате трета логическа стойност, наречена UNKNOWN. Имайте предвид, че това е така, дори когато сравнявате две NULL. Третирането на TRUE и FALSE от повечето елементи на SQL е доста интуитивно. Лечението на НЕИЗВЕСТНО не винаги е толкова интуитивно. Освен това различните елементи на SQL обработват по различен начин случая НЕИЗВЕСТНО, както ще обясня подробно по-късно в статията под „Несъответствия при третиране с NULL“.
Като пример, да предположим, че трябва да направите заявка за таблицата Sales.Orders в примерната база данни TSQLV5 и да върнете поръчки, които са били изпратени на 2 януари 2019 г. Използвате следната заявка:
ИЗПОЛЗВАЙТЕ TSQLV5; SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate ='20190102';
Ясно е, че предикатът на филтъра се оценява на TRUE за редове, където датата на доставка е 2 януари 2019 г., и че тези редове трябва да бъдат върнати. Също така е ясно, че предикатът се оценява на FALSE за редове, където е представена датата на доставка, но не е 2 януари 2019 г., и че тези редове трябва да бъдат отхвърлени. Но какво да кажем за редове с NULL дата на доставка? Не забравяйте, че предикати, базирани на равенство, и предикати, базирани на неравенство, връщат UNKNOWN, ако някой от операндите е NULL. Филтърът WHERE е предназначен да отхвърля такива редове. Трябва да запомните, че филтърът WHERE връща редове, за които предикатът на филтъра се оценява на TRUE, и отхвърля редове, за които предикатът се оценява на FALSE или UNKNOWN.
Тази заявка генерира следния изход:
дата на доставка на поръчката----------- -----------10771 2019-01-0210794 2019-01-0210802 2019-01-02
Да предположим, че трябва да върнете поръчки, които не са били изпратени на 2 януари 2019 г. Що се отнася до вас, поръчките, които все още не са били изпратени, трябва да бъдат включени в изхода. Използвате заявка, подобна на последната, като само отричате предиката, както следва:
ИЗБЕРЕТЕ идентификатор на поръчката, shippeddateFROM Sales.OrdersWHERE NOT (shippeddate ='20190102');
Тази заявка връща следния изход:
<предварителна>дата на доставка----------- -----------10249 2017-07-1010252 2017-07-1110250 2017-07-12...11050 2019-05 -0511055 2019-05-0511063 2019-05-0611067 2019-05-0611069 2019-05-06 (засегнати 806 реда)Резултатът естествено изключва редовете с дата на доставка 2 януари 2019 г., но също така изключва редовете с NULL дата на доставка. Това, което може да бъде противоинтуитивно тук, е какво се случва, когато използвате оператора NOT, за да отричате предикат, който се оценява на UNKNOWN. Очевидно е, че НЕ ВЯРНО е FALSE и НЕ НЕВЯРНО е ВЯРНО. Въпреки това, НЕ НЕИЗВЕСТНО си остава НЕИЗВЕСТНО. Логиката на SQL зад този дизайн е, че ако не знаете дали едно предложение е вярно, вие също не знаете дали предложението не е вярно. Това означава, че когато се използват оператори за равенство и неравенство в предиката на филтъра, нито положителните, нито отрицателните форми на предиката връщат редовете с NULL.
Този пример е доста прост. Има по-трудни случаи, включващи подзаявки. Има често срещана грешка, когато използвате предиката NOT IN с подзаявка, когато подзаявката връща NULL сред върнатите стойности. Заявката винаги връща празен резултат. Причината е, че положителната форма на предиката (частта IN) връща TRUE, когато е намерена външната стойност, и UNKNOWN, когато не е намерена поради сравнението с NULL. Тогава отрицанието на предиката с оператора NOT винаги връща FALSE или UNKNOWN, съответно – никога TRUE. Разкривам подробно тази грешка в T-SQL грешки, клопки и най-добри практики – подзаявки, включително предложени решения, съображения за оптимизация и най-добри практики. Ако все още не сте запознати с тази класическа грешка, не забравяйте да проверите тази статия, тъй като грешката е доста често срещана и има прости мерки, които можете да предприемете, за да я избегнете.
Обратно към нашите нужди, какво да кажем за опит за връщане на поръчки с дата на доставка, която е различна от 2 януари 2019 г., използвайки оператора, различен от (<>):
ИЗБЕРЕТЕ идентификатор на поръчката, shippeddateFROM Sales.OrdersWHERE shippeddate <> '20190102';
За съжаление, операторите за равенство и неравенство дават UNKNOWN, когато някой от операндите е NULL, така че тази заявка генерира следния изход като предишната заявка, с изключение на NULL:
<предварителна>дата на доставка----------- -----------10249 2017-07-1010252 2017-07-1110250 2017-07-12...11050 2019-05 -0511055 2019-05-0511063 2019-05-0611067 2019-05-0611069 2019-05-06 (засегнати 806 реда)За да се изолира проблемът със сравненията с NULL, които дават UNKNOWN с помощта на равенство, неравенство и отрицание на двата вида оператори, всички от следните заявки връщат празен набор от резултати:
SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate =NULL; SELECT orderid, shippeddateFROM Sales.OrdersWHERE NOT (дата на доставка =NULL); SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate <> NULL; SELECT orderid, shippeddateFROM Sales.OrdersWHERE NOT (дата на доставка <> NULL);
Според SQL не трябва да проверявате дали нещо е равно на NULL или различно от NULL, а дали нещо е NULL или не е NULL, като използвате специалните оператори IS NULL и IS NOT NULL, съответно. Тези оператори използват логика с две стойности, като винаги връщат TRUE или FALSE. Например, използвайте оператора IS NULL, за да върнете неизпратени поръчки, както следва:
ИЗБЕРЕТЕ идентификатор на поръчката, shippeddateFROM Sales.OrdersWHERE shippeddate IS NULL;
Тази заявка генерира следния изход:
поръчка дата на доставка----------- -----------11008 NULL11019 NULL11039 NULL...(21 реда засегнати)
Използвайте оператора IS NOT NULL, за да върнете изпратените поръчки, както следва:
ИЗБЕРЕТЕ идентификатор на поръчката, shippeddateFROM Sales.OrdersWHERE shippeddate НЕ Е NULL;
Тази заявка генерира следния изход:
<предварителна>дата на доставка----------- -----------10249 2017-07-1010252 2017-07-1110250 2017-07-12...11050 2019-05 -0511055 2019-05-0511063 2019-05-0611067 2019-05-0611069 2019-05-06 (засегнати са 809 реда)Използвайте следния код, за да върнете поръчки, които са били изпратени на дата, различна от 2 януари 2019 г., както и неизпратени поръчки:
ИЗБЕРЕТЕ идентификатор на поръчката, shippeddateFROM Sales.OrdersWHERE shippeddate <> '20190102' ИЛИ shippeddate IS NULL;
Тази заявка генерира следния изход:
<предварителна>дата на доставка----------- -----------11008 NULL11019 NULL11039 NULL...10249 2017-07-1010252 2017-07-1110250 2017-07-12 ...11050 2019-05-0511055 2019-05-0511063 2019-05-0611067 2019-05-0611069 2019-05-06 (засегнати 827 реда)В по-късна част от поредицата разглеждам стандартните функции за третиране с NULL, които в момента липсват в T-SQL, включително предиката DISTINCT , които имат потенциала да опростят много обработката на NULL.
Сравнения с променливи, параметри и колони
Предишният раздел се фокусира върху предикатите, които сравняват колона с константа. В действителност обаче най-вече ще сравнявате колона с променливи/параметри или с други колони. Такива сравнения включват допълнителни сложности.
От гледна точка на обработка на NULL, променливите и параметрите се третират еднакво. Ще използвам променливи в моите примери, но точките, които отбелязвам относно тяхната обработка, са също толкова релевантни за параметрите.
Помислете за следната основна заявка (ще я нарека Заявка 1), която филтрира поръчки, които са били изпратени на дадена дата:
ДЕКЛАРИРАНЕ @dt КАТО ДАТА ='20190212'; SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate =@dt;
Използвам променлива в този пример и я инициализирам с някаква примерна дата, но това също може да е параметризирана заявка в съхранена процедура или дефинирана от потребителя функция.
Това изпълнение на заявка генерира следния изход:
<предварителна>дата на доставка----------- -----------10865 2019-02-1210866 2019-02-1210876 2019-02-1210878 2019-02-1210879 2019- 02-12Планът за заявка 1 е показан на фигура 1.
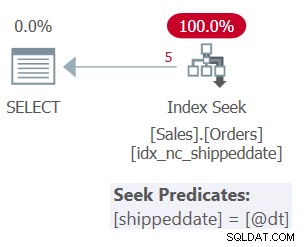 Фигура 1:План за заявка 1
Фигура 1:План за заявка 1
Таблицата има покриващ индекс, който поддържа тази заявка. Индексът се нарича idx_nc_shippeddate и се дефинира със списъка с ключове (shippeddate, orderid). Предикатът на филтъра на заявката се изразява като аргумент за търсене (SARG) , което означава, че позволява на оптимизатора да обмисли прилагането на операция за търсене в поддържащия индекс, преминавайки направо към диапазона от квалифициращи редове. Това, което прави предиката на филтъра SARGable, е, че той използва оператор, който представлява последователен диапазон от квалифицирани редове в индекса и че не прилага манипулация към филтрираната колона. Планът, който получавате, е оптималният план за тази заявка.
Но какво ще стане, ако искате да позволите на потребителите да искат неизпратени поръчки? Такива поръчки имат NULL дата на доставка. Ето опит да се предаде NULL като входна дата:
ДЕКЛАРИРАНЕ @dt КАТО ДАТА =NULL; SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate =@dt;
Както вече знаете, предикат, използващ оператор за равенство, произвежда UNKNOWN, когато някой от операндите е NULL. Следователно тази заявка връща празен резултат:
поръчка дата на доставка----------- -----------(0 засегнати реда)
Въпреки че T-SQL поддържа оператор IS NULL, той не поддържа изричен IS <израз> оператор. Така че не можете да използвате предикат на филтър като WHERE shippeddate IS @dt. Отново ще говоря за неподдържаната стандартна алтернатива в бъдеща статия. Това, което много хора правят, за да решат тази нужда в T-SQL, е да използват функциите ISNULL или COALESCE, за да заменят NULL със стойност, която обикновено не може да се появи в данните от двете страни, така (ще нарека тази заявка 2):
ДЕКЛАРИРАНЕ @dt КАТО ДАТА =NULL; SELECT orderid, shippeddateFROM Sales.OrdersWHERE ISNULL(shippeddate, '99991231') =ISNULL(@dt, '99991231');
Тази заявка генерира правилния изход:
поръчка дата на доставка----------- -----------11008 NULL11019 NULL11039 NULL...11075 NULL11076 NULL11077 NULL (засегнати 21 реда)
Но планът за тази заявка, както е показано на фигура 2, не е оптимален.
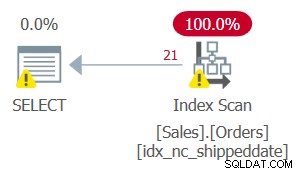 Фигура 2:План за заявка 2
Фигура 2:План за заявка 2
Тъй като сте приложили манипулация към филтрираната колона, предикатът на филтъра вече не се счита за SARG. Индексът все още обхваща, така че може да се използва; но вместо да се прилага търсене в индекса, което отива направо към диапазона от квалифицирани редове, целият лист на индекса се сканира. Да предположим, че масата има 50 000 000 поръчки, като само 1000 са неизпратени поръчки. Този план ще сканира всички 50 000 000 реда, вместо да извършва търсене, което отива направо към отговарящите на условията 1 000 реда.
Една форма на предикат на филтъра, която има правилното значение, която търсим и се счита за аргумент за търсене, е (shippeddate =@dt ИЛИ (shippeddate Е NULL И @dt IS NULL)). Ето заявка, използваща този предикат SARGable (ще го наречем заявка 3):
ДЕКЛАРИРАНЕ @dt КАТО ДАТА =NULL; ИЗБЕРЕТЕ идентификатор на поръчката, shippeddateFROM Sales.OrdersWHERE (дата на доставка =@dt ИЛИ (датата на доставка Е НУЛИНА И @dt Е NULL));
Планът за тази заявка е показан на Фигура 3.
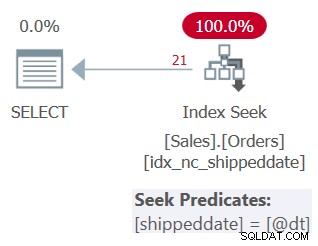 Фигура 3:План за заявка 3
Фигура 3:План за заявка 3
Както можете да видите, планът прилага търсене в поддържащия индекс. Предикатът за търсене казва shippeddate =@dt, но е вътрешно проектиран да обработва NULL точно както стойностите, различни от NULL, за целта на сравнението.
Това решение обикновено се счита за разумно. Той е стандартен, оптимален и правилен. Основният му недостатък е, че е многословен. Ами ако сте имали множество предикати за филтриране на базата на NULL колони? Бързо ще се окажете с дълга и тромава клауза WHERE. И става много по-лошо, когато трябва да напишете предикат на филтър, включващ колона с NULL, която търси редове, където колоната е различна от входния параметър. Предикатът тогава става:(shippeddate <> @dt AND ((shippeddate Е NULL И @dt НЕ Е NULL) ИЛИ (shippeddate НЕ Е NULL и @dt IS NULL))).
Виждате ясно необходимостта от по-елегантно решение, което е едновременно кратко и оптимално. За съжаление някои прибягват до нестандартно решение, при което изключвате опцията за сесия ANSI_NULLS. Тази опция кара SQL Server да използва нестандартна обработка на операторите за равенство (=) и различни от (<>) с двузначна логика вместо с тризначна логика, като третира NULL точно като стойности, различни от NULL за целите на сравнението. Поне така е, стига един от операндите да е параметър/променлива или литерал.
Изпълнете следния код, за да изключите опцията ANSI_NULLS в сесията:
ИЗКЛЮЧИ ANSI_NULLS;
Изпълнете следната заявка, като използвате прост предикат, базиран на равенство:
ДЕКЛАРИРАНЕ @dt КАТО ДАТА =NULL; SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate =@dt;
Тази заявка връща 21 неизпратени поръчки. Получавате същия план, показан по-рано на фигура 3, показващ търсене в индекса.
Изпълнете следния код, за да превключите обратно към стандартно поведение, където ANSI_NULLS е включен:
ЗАДАДЕТЕ ANSI_NULLS ON;
Разчитането на такова нестандартно поведение е силно обезкуражено. Документацията също така посочва, че поддръжката за тази опция ще бъде премахната в някои бъдещи версии на SQL Server. Освен това мнозина не осъзнават, че тази опция е приложима само когато поне един от операндите е параметър/променлива или константа, въпреки че документацията е доста ясна за това. Не се прилага при сравняване на две колони, като например при обединяване.
И така, как се справяте с обединения, включващи NULL колони за присъединяване, ако искате да получите съвпадение, когато двете страни са NULL? Като пример използвайте следния код, за да създадете и попълните таблиците T1 и T2:
ПРОСТЪПНЕТЕ ТАБЛИЦА, АКО СЪЩЕСТВУВА dbo.T1, dbo.T2;СЪЗДАДЕТЕ ТАБЛИЦА dbo.T1(k1 INT NULL, k2 INT NULL, k3 INT NULL, val1 VARCHAR(10) NOT NULL, ОГРАНИЧЕНИЕ UNQ_T1 UNIQUE CLUSTERED(k1,k2 , k3)); СЪЗДАВАНЕ НА ТАБЛИЦА dbo.T2(k1 INT NULL, k2 INT NULL, k3 INT NULL, val2 VARCHAR(10) НЕ NULL, ОГРАНИЧЕНИЕ UNQ_T2 UNIQUE CLUSTERED(k1, k2, k3)); INSERT INTO dbo.T1(k1, k2, k3, val1) СТОИ (1, NULL, 0, 'A'), (NULL, NULL, 1, 'B'), (0, NULL, NULL, 'C') ,(1, 1, 0, 'D'), (0, NULL, 1, 'F'); ВМЕСТЕ В dbo.T2(k1, k2, k3, val2) СТОЙНОСТИ (0, 0, 0, 'G'), (1, 1, 1, 'H'), (0, NULL, NULL, 'I') ,(NULL, NULL, NULL, 'J'),(0, NULL, 1, 'K');
Кодът създава покриващи индекси на двете таблици, за да поддържа обединяване въз основа на ключовете за свързване (k1, k2, k3) от двете страни.
Използвайте следния код, за да актуализирате статистиката за мощността, като надуете числата, така че оптимизаторът да мисли, че имате работа с по-големи таблици:
АКТУАЛИЗИРАНЕ НА СТАТИСТИКАТА dbo.T1(UNQ_T1) С БРОЙ НА РЕДОВЕ =1000000; АКТУАЛИЗИРАНЕ НА СТАТИСТИКАТА dbo.T2(UNQ_T2) СЪС ROWCOUNT =1000000;
Използвайте следния код в опит да свържете двете таблици, като използвате прости предикати, базирани на равенство:
ИЗБЕРЕТЕ T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1 INNER JOIN dbo.T2 НА T1.k1 =T2.k1 И T1.k2 =T2.k2 И T1. k3 =T2.k3;
Точно както при предишните примери за филтриране, и тук сравненията между NULL, използващи оператор за равенство, дават НЕИЗВЕСТНО, което води до несъвпадения. Тази заявка генерира празен изход:
k1 K2 K3 val1 val2 ----------- ----------- --------- - ----------(0 засегнати реда)
Използването на ISNULL или COALESCE, както в по-ранен пример за филтриране, замяната на NULL със стойност, която обикновено не може да се появи в данните от двете страни, води до правилна заявка (ще наричам тази заявка заявка 4):
ИЗБЕРЕТЕ T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1 INNER JOIN dbo.T2 ПРИ ISNULL(T1.k1, -2147483648) =ISNULL(T2.k1, -214748364 ) И ISNULL(T1.k2, -2147483648) =ISNULL(T2.k2, -2147483648) И ISNULL(T1.k3, -2147483648) =ISNULL(T2.k3, -2147483);
Тази заявка генерира следния изход:
k1 K2 K3 val1 val2 ----------- ----------- --------- ----------0 NULL NULL C I0 NULL 1 F K
Въпреки това, точно както манипулирането на филтрирана колона нарушава SARG-способността на филтърния предикат, манипулирането на колона за присъединяване предотвратява възможността да се разчита на реда на индекса. Това може да се види в плана за тази заявка, както е показано на Фигура 4.
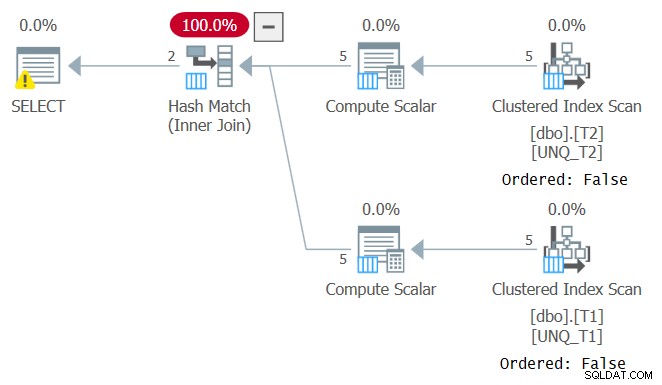 Фигура 4:План за заявка 4
Фигура 4:План за заявка 4
Оптималният план за тази заявка е този, който прилага подредени сканирания на двата покриващи индекса, последвани от алгоритъм на Merge Join, без изрично сортиране. Оптимизаторът избра различен план, тъй като не може да разчита на реда на индексите. Ако се опитате да принудите алгоритъм за свързване на сливане с помощта на INNER MERGE JOIN, планът все още ще разчита на неподредени сканирания на индексите, последвано от изрично сортиране. Опитайте!
Разбира се, можете да използвате дългите предикати, подобни на предикатите SARGable, показани по-рано, за задачи за филтриране:
ИЗБЕРЕТЕ T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1 INNER JOIN dbo.T2 ON (T1.k1 =T2.k1 ИЛИ (T1.k1 Е NULL И T2. K1 Е NULL)) И (T1.k2 =T2.k2 ИЛИ (T1.k2 Е NULL И T2.K2 Е NULL)) И (T1.k3 =T2.k3 ИЛИ (T1.k3 Е NULL И T2.K3 Е NULL));
Тази заявка наистина дава желания резултат и позволява на оптимизатора да разчита на реда на индексите. Въпреки това, нашата надежда е да намерим решение, което е едновременно оптимално и сбито.
Има малко позната елегантна и сбита техника, която можете да използвате както при свързвания, така и при филтри, както за идентифициране на съвпадения, така и за идентифициране на несъответствия. Тази техника беше открита и документирана преди години, като например в отличната статия на Пол Уайт „Недокументирани планове за запитване:Сравнения на равенство“ от 2011 г. Но по някаква причина изглежда, че все още много хора не са наясно с нея и за съжаление в крайна сметка използват неоптимални, продължителни и нестандартни решения. Със сигурност заслужава повече излагане и любов.
Техниката разчита на факта, че операторите на множество като INTERSECT и EXCEPT използват подход за сравнение, базиран на отличителността, когато сравняват стойности, а не подход за сравнение, базиран на равенство или неравенство.
Разгледайте нашата задача за присъединяване като пример. Ако не трябваше да връщаме колони, различни от ключовете за присъединяване, щяхме да използваме проста заявка (ще я наричам Заявка 5) с оператор INTERSECT, както следва:
ИЗБЕРЕТЕ k1, k2, k3 ОТ dbo.T1INTERSECTSELECT k1, k2, k3 ОТ dbo.T2;
Тази заявка генерира следния изход:
k1 k2 k3 ----------- -----------0 NULL NULL0 NULL 1
Планът за тази заявка е показан на Фигура 5, потвърждавайки, че оптимизаторът е могъл да разчита на реда на индексите и да използва алгоритъм на Merge Join.
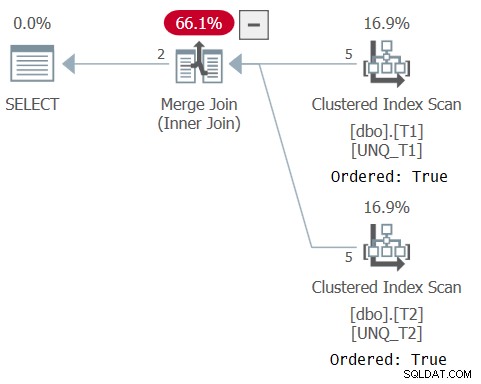 Фигура 5:План за заявка 5
Фигура 5:План за заявка 5
Както отбелязва Пол в статията си, XML планът за оператора set използва имплицитен оператор за сравнение на IS (CompareOp="IS" ) за разлика от оператора за сравнение на EQ, използван при нормално присъединяване (CompareOp="EQ" ). Проблемът с решение, което разчита единствено на оператор за набор, е, че то ви ограничава до връщане само на колоните, които сравнявате. Това, от което наистина се нуждаем, е нещо като хибрид между оператор за свързване и набор, който ви позволява да сравнявате подмножество от елементи, като същевременно връщате допълнителни, както прави присъединяването, и използвайки сравнение, базирано на отличителност (IS), както прави операторът за набор. Това е постижимо чрез използване на присъединяване като външна конструкция и предикат EXISTS в клаузата ON на съединението въз основа на заявка с оператор INTERSECT, сравняващ ключовете за свързване от двете страни, като така (ще наричам това решение Query 6):
ИЗБЕРЕТЕ T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2. k1, T2.k2, T2.k3);
Операторът INTERSECT работи с две заявки, всяка от които образува набор от един ред на базата на свързващите ключове от двете страни. Когато двата реда са еднакви, заявката INTERSECT връща един ред; предикатът EXISTS връща TRUE, което води до съвпадение. Когато двата реда не са еднакви, заявката INTERSECT връща празен набор; предикатът EXISTS връща FALSE, което води до несъвпадение.
Това решение генерира желания изход:
k1 K2 K3 val1 val2 ----------- ----------- --------- ----------0 NULL NULL C I0 NULL 1 F K
Планът за тази заявка е показан на фигура 6, потвърждавайки, че оптимизаторът е могъл да разчита на реда на индексите.
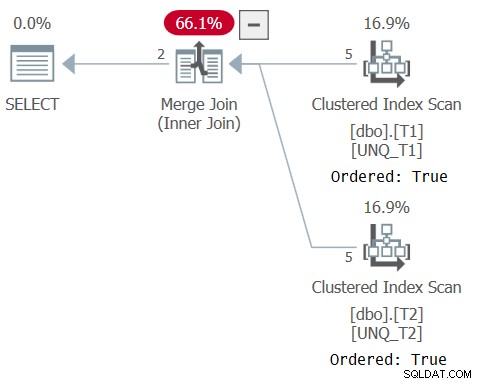 Фигура 6:План за заявка 6
Фигура 6:План за заявка 6
Можете да използвате подобна конструкция като предикат на филтър, включващ колона и параметър/променлива, за да търсите съвпадения въз основа на отличителността, като така:
ДЕКЛАРИРАНЕ @dt КАТО ДАТА =NULL; ИЗБЕРЕТЕ идентификатор на поръчката, shippeddateFROM Sales.OrdersWHERE EXISTS(ИЗБЕРЕТЕ shippeddate INTERSECT SELECT @dt);
Планът е същият като този, показан по-рано на Фигура 3.
Можете също да отречете предиката, за да търсите несъответствия, като така:
ДЕКЛАРИРАНЕ @dt КАТО ДАТА ='20190212'; SELECT orderid, shippeddateFROM Sales.OrdersWHERE NOT EXISTS(ИЗБЕРЕТЕ shippeddate INTERSECT SELECT @dt);
Тази заявка генерира следния изход:
<предварителна>дата на доставка----------- -----------11008 NULL11019 NULL11039 NULL...10847 2019-02-1010856 2019-02-1010871 2019-02-1010867 2019-02-1110874 2019-02-1110870 2019-02-1310884 2019-02-1310840 2019-02-1610887 2019-02-16...(825)Като алтернатива можете да използвате положителен предикат, но да замените INTERSECT с EXCEPT, както следва:
ДЕКЛАРИРАНЕ @dt КАТО ДАТА ='20190212'; ИЗБЕРЕТЕ идентификатор на поръчката, shippeddateFROM Sales.OrdersWHERE EXISTS(ИЗБЕРЕТЕ shippeddate EXCEPT SELECT @dt);
Имайте предвид, че плановете в двата случая може да са различни, така че не забравяйте да експериментирате и в двата начина с големи количества данни.
Заключение
NULL добавят своя дял от сложността към писането на вашия SQL код. Винаги искате да мислите за потенциала за присъствие на NULL в данните и да се уверите, че използвате правилните конструкции на заявка и да добавите съответната логика към вашите решения, за да боравите правилно с NULL. Игнорирането им е сигурен начин да завършите с грешки в кода си. Този месец се съсредоточих върху това какво представляват NULL и как се обработват при сравнения, включващи константи, променливи, параметри и колони. Следващия месец ще продължа отразяването, като обсъждам несъответствията на третирането с NULL в различни езикови елементи и липсващите стандартни функции за обработка на NULL.