SQL DISTINCT е добър (или лош), когато трябва да премахнете дубликати в резултатите?
Някои казват, че е добре и добавят DISTINCT, когато се появят дубликати. Някои казват, че е лошо и предлагат да се използва GROUP BY без агрегатна функция. Други казват, че DISTINCT и GROUP BY са еднакви, когато трябва да премахнете дубликати.
Тази публикация ще се потопите в подробностите, за да получите правилни отговори. Така че в крайна сметка ще използвате най-добрата ключова дума въз основа на необходимостта. Да започнем.
Кратко напомняне за основите на оператора SQL SELECT DISTINCT
Преди да се потопим по-дълбоко, нека си припомним какво представлява операторът SQL SELECT DISTINCT. Таблицата на база данни може да включва дублиращи се стойности по много причини, но може да искаме да получим само уникалните стойности. В този случай SELECT DISTINCT е удобен. Тази клауза DISTINCT кара оператора SELECT да извлича само уникални записи.
Синтаксисът на изявлението е прост:
SELECT DISTINCT column
FROM table_name
WHERE [condition];Тук условието WHERE е по избор.
Изявлението се отнася както за една колона, така и за множество колони. Синтаксисът на този израз, приложен към множество колони, е както следва:
SELECT DISTINCT
column_name1,
column_name2,
column_nameN.
FROM
table_name;Имайте предвид, че сценарият на заявка за няколко колони ще предложи да се използва комбинацията от стойности във всички колони, дефинирани от израза, за да се определи уникалността.
И сега, нека проучим практическата употреба и уловките на прилагането на израза SELECT DISTINCT.
Как работи SQL DISTINCT за премахване на дубликати
Получаването на отговори не е толкова трудно за намиране. SQL Server ни предостави планове за изпълнение, за да видим как една заявка ще бъде обработена, за да ни даде необходимите резултати.
Следващият раздел се фокусира върху плана за изпълнение при използване на DISTINCT. Трябва да натиснете Ctrl-M в SQL Server Management Studio, преди да изпълните заявките по-долу. Или кликнете върху Включване на действителен план за изпълнение от лентата с инструменти.
Планове за заявки в SQL DISTINCT
Нека започнем със сравняване на 2 заявки. Първата няма да използва DISTINCT, а втората заявка ще използва.
USE AdventureWorks
GO
-- Without DISTINCT. Duplicates included
SELECT Lastname FROM Person.Person;
-- With DISTINCT. Duplicates removed
SELECT DISTINCT Lastname FROM Person.Person;
Ето плана за изпълнение:
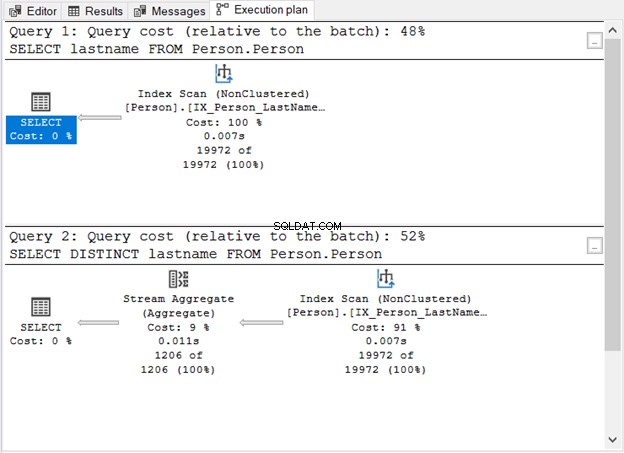
Какво ни показа Фигура 1?
- Без ключовата дума DISTINCT заявката е проста.
- Появява се допълнителна стъпка след добавяне на DISTINCT.
- Цената на заявката при използване на DISTINCT е по-висока, отколкото без нея.
- И двете имат оператори за индексно сканиране. Това е разбираемо, защото в нашите заявки няма конкретна клауза WHERE.
- Допълнителната стъпка, операторът Stream Aggregate, се използва за премахване на дубликатите.
Броят на логическите четения е същият (107), ако проверите STATISTICS IO. Въпреки това броят на записите е много различен. 19 972 реда се връщат от първата заявка. Междувременно 1206 реда се връщат от втората заявка.
Следователно не можете да добавяте DISTINCT по всяко време, когато пожелаете. Но ако имате нужда от уникални стойности, това е необходим режий.
Има оператори, използвани за извеждане на уникални стойности. Нека разгледаме някои от тях.
АГРЕГАТИРАНЕ НА ПОТОК
Това е операторът, който видяхте на фигура 1. Той приема единичен вход и извежда обобщен резултат. На фигура 1 входът идва от оператора Index Scan. Въпреки това Stream Aggregate се нуждае от сортиран вход.
Както можете да видите на фигура 1, той използва IX_Person_LastName_FirstName_MiddleName , неуникален индекс на имената. Тъй като индексът вече сортира записите по име, Stream Aggregate приема входа. Без индекса оптимизаторът на заявки може да избере да използва допълнителен оператор за сортиране в плана. И това ще бъде по-скъпо. Или може да използва съвпадение на хеш.
ХЕШ СЪВЪВСТЪПВАНЕ (АГРЕГАТ)
Друг оператор, използван от DISTINCT, е Hash Match. Този оператор се използва за обединения и агрегации.
Когато използвате DISTINCT, Hash Match обобщава резултатите, за да произведе уникални стойности. Ето един пример.
USE AdventureWorks
GO
-- Get unique first names
SELECT DISTINCT Firstname FROM Person.Person;
А ето и плана за изпълнение:
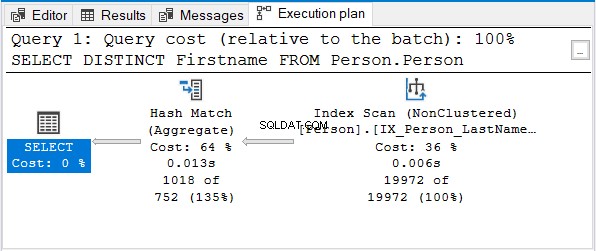
Но защо не и Stream Aggregate?
Забележете, че се използва индекс със същото име. Този индекс се сортира с Фамилия първо. И така, Име само заявката ще стане несортирана.
Hash Match (Aggregate) е следващият логичен избор за премахване на дубликатите.
ХЕШ СЪВЪВСТАВЯНЕ (FLOW DISTINCT)
Hash Match (Aggregate) е блокиращ оператор. По този начин той няма да произведе изхода, който е обработил целия входен поток. Ако ограничим броя на редовете (като използване на TOP с DISTINCT), той ще произведе уникален изход веднага щом тези редове са налични. Това е съвпадението на хеш (Flow Distinct).
USE AdventureWorks
GO
SELECT DISTINCT TOP 100
sod.ProductID
,soh.OrderDate
,soh.ShipDate
FROM Sales.SalesOrderDetail sod
INNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID = soh.SalesOrderID;
Заявката използва TOP 100 заедно с DISTINCT. Ето плана за изпълнение:
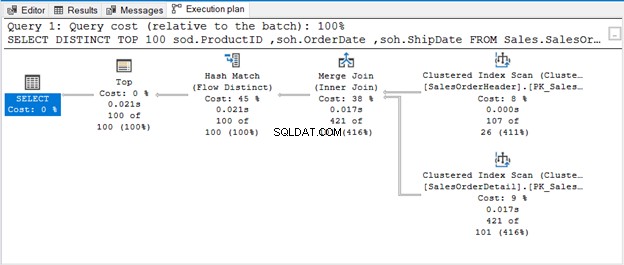
КОГАТО НЯМА ОПЕРАТОР ЗА ПРЕМАХВАНЕ НА ДУПЛИКАТИ
Мда. Това може да се случи. Помислете за примера по-долу.
USE AdventureWorks
GO
SELECT DISTINCT
BusinessEntityID
FROM Person.Person;
След това проверете плана за изпълнение:
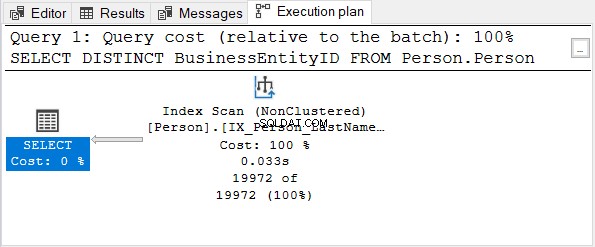
BusinessEntityID колоната е първичният ключ. Тъй като тази колона вече е уникална, няма полза от прилагането на DISTINCT. Опитайте да премахнете DISTINCT от израза SELECT – планът за изпълнение е същият като на фигура 4.
Същото важи и при използване на DISTINCT върху колони с уникален индекс.
SQL DISTINCT работи върху ВСИЧКИ колони в списъка SELECT
Досега използвахме само 1 колона в нашите примери. Въпреки това, DISTINCT работи върху ВСИЧКИ колони, които посочите в списъка SELECT.
Ето един пример. Тази заявка ще гарантира, че стойностите на всичките 3 колони ще бъдат уникални.
USE AdventureWorks
GO
SELECT DISTINCT
Lastname
,FirstName
,MiddleName
FROM Person.Person;
Обърнете внимание на първите няколко реда в набора от резултати на фигура 5.
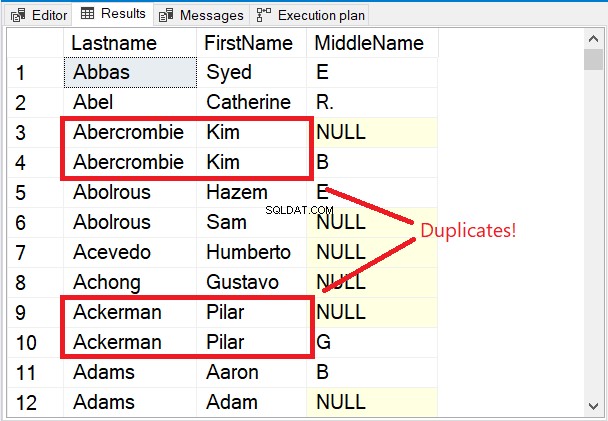
Всички първите няколко реда са уникални. Ключовата дума DISTINCT гарантира, че Middlename колоната също се разглежда. Забележете 2-те имена, поставени в червено. Като се има предвид Фамилията и Име само ще ги направи дубликати. Но добавяне на Middlename към микса промени всичко.
Ами ако искате да получите уникални собствени и фамилни имена, но да включите средното име в резултата?
Имате 2 опции:
- Добавете клауза WHERE, за да премахнете NULL бащини имена. Това ще премахне всички имена с NULL средно име.
- Или добавете клауза GROUP BY към Фамилия и Име колони. След това използвайте обобщената функция MIN на Middlename колона. Това ще получи 1 второ име със същите фамилия и собствено име.
SQL DISTINCT спрямо GROUP BY
Когато използвате GROUP BY без агрегатна функция, тя действа като DISTINCT. откъде знаем? Един от начините да разберете е да използвате пример.
USE AdventureWorks
GO
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID;
-- using GROUP BY
SELECT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID
GROUP BY
soh.TerritoryID
,st.Name;
Стартирайте ги и проверете плана за изпълнение. Дали е като на екранната снимка по-долу?
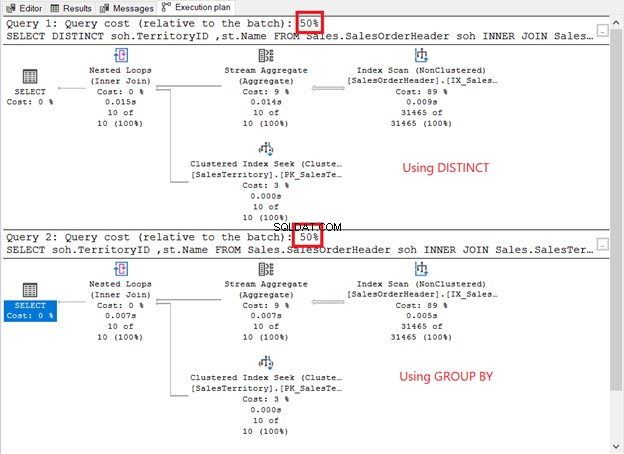
Как се сравняват?
- Те имат еднакви планови оператори и последователност.
- Операторската цена за всеки и разходите за заявка са еднакви.
Ако поставите отметка в QueryPlanHash свойства на 2-те оператора SELECT, те са еднакви. Следователно оптимизаторът на заявки използва същия процес, за да върне същите резултати.
В крайна сметка не можем да кажем, че използването на GROUP BY е по-добро от DISTINCT при връщането на уникални стойности. Можете да докажете това, като използвате горните примери, за да замените DISTINCT с GROUP BY.
Вече е въпрос на предпочитание кое ще използвате. Предпочитам РАЗЛИЧЕН. Той изрично казва намерението в заявката – да се произведат уникални резултати. И за мен GROUP BY е за групиране на резултати с помощта на агрегатна функция. Това намерение също е ясно и в съответствие със самата ключова дума. Не знам дали някой друг ще поддържа въпросите ми един ден. Така че кодът трябва да е ясен.
Но това не е краят на историята.
Когато SQL DISTINCT не е същото като GROUP BY
Просто изразих мнението си и след това това?
Вярно е. Те няма да са едни и същи през цялото време. Помислете за този пример.
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh;
-- using GROUP BY
SELECT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh
GROUP BY
soh.TerritoryID;
Въпреки че резултатният набор не е сортиран, редовете са същите като в предишния пример. Единствената разлика е използването на подзаявка:
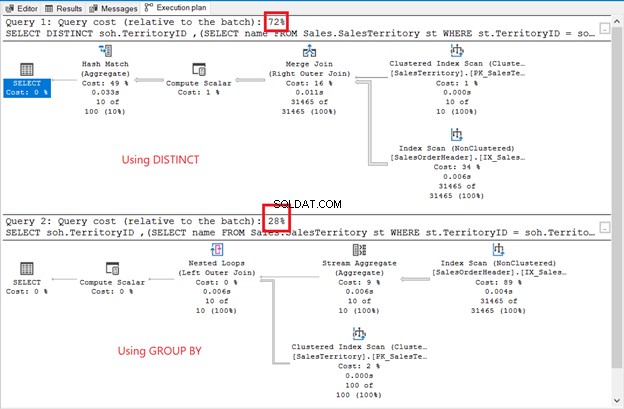
Разликите са очевидни:оператори, цена на заявка, общ план. Този път GROUP BY печели само с 28% цена на заявката. Но ето какво е.
Целта е да ви покажем, че те могат да бъдат различни. Това е всичко. Това в никакъв случай не е препоръка. Използването на присъединяване има по-добър план за изпълнение (вижте отново фигура 6).
Дъното
Ето какво научихме досега:
- DISTINCT добавя оператор на план за премахване на дубликати.
- DISTINCT и GROUP BY без агрегатна функция водят до един и същ план. Накратко, те са едни и същи през повечето време.
- Понякога DISTINCT и GROUP BY могат да имат различни планове, когато подзаявка е включена в списъка SELECT.
И така, SQL DISTINCT е добър или лош при премахването на дубликати в резултатите?
Резултатите казват, че е добре. Не е по-добре или по-лошо от GROUP BY, защото плановете са едни и същи. Но е добър навик да проверите плана за изпълнение. Помислете за оптимизация от самото начало. По този начин, ако срещнете някакви разлики в DISTINCT и GROUP BY, ще ги забележите.
Освен това съвременните инструменти правят тази задача много по-лесна. Например, популярен продукт dbForge SQL Complete от Devart има специфична функция, която изчислява стойности в агрегатните функции в готовия набор от резултати на SSMS резултатната мрежа. Стойностите DISTINCT също присъстват там.
Харесвате ли публикацията? След това, моля, разпространете думата, като я споделите в любимите си социални медийни платформи.
Свързани статии за повече информация
- SQL GROUP BY:3 лесни съвета за групиране на резултати като професионалист
- SQL INSERT INTO SELECT:5 лесни начина за справяне с дубликати
- Какво представляват SQL агрегатните функции? (Лесни съвети за начинаещи)
- Оптимизация на SQL заявки:5 основни факта за повишаване на заявките