[ Част 1 | Част 2 | Част 3 ]
Наскоро някой на работа поиска повече място, за да побере бързо растяща маса. По това време той имаше 3,75 милиарда реда, представени на 143 милиона страници и заемащи ~1,14TB. Разбира се, винаги можем да хвърлим повече диск на маса, но исках да видя дали можем да мащабираме това по-ефективно от текущата линейна тенденция. Звучи като страхотна работа за компресия, нали? Но също така исках да изпробвам някои други решения, включително columnstore – което хората изненадващо не са склонни да опитат. Аз не съм Нико, но исках да положа усилия да видя какво може да направи за нас тук.
Обърнете внимание, че в момента не се фокусирам върху отчитането на работното натоварване или друга производителност на заявки за четене – просто искам да видя какво въздействие мога да имам върху съхранението (и паметта) на тези данни.
Ето оригиналната таблица. Промених имената на таблици и колони, за да защитя невинните, но всичко останало е относително точно.
CREATE TABLE dbo.tblOriginal
(
OID bigint IDENTITY(1,1) NOT NULL PRIMARY KEY, -- there are gaps!
IN1 int NOT NULL,
IN2 int NOT NULL,
VC1 varchar(3) NULL,
BI1 bigint NULL,
IN3 int NULL,
VC2 varchar(128) NOT NULL,
VC3 varchar(128) NOT NULL,
VC4 varchar(128) NULL,
NM1 numeric(24,12) NULL,
NM2 numeric(24,12) NULL,
NM3 numeric(24,12) NULL,
BI2 bigint NULL,
IN4 int NULL,
BI3 bigint NULL,
NM4 numeric(24,12) NULL,
IN5 int NULL,
NM5 numeric(24,12) NULL,
DT1 date NULL,
VC5 varchar(128) NULL,
BI4 bigint NULL,
BI5 bigint NULL,
BI6 bigint NULL,
BT1 bit NOT NULL,
NV1 nvarchar(512) NULL,
VB1 AS (HASHBYTES('MD5',VC2+VC3)),
IN6 int NULL,
IN7 int NULL,
IN8 int NULL
);
Има някои други малки неща, които са по-широки, отколкото трябва да бъдат и/или компресирането на редове може да почисти, като тези numeric(24,12) и bigint колони, които може да са преждевременно огромни, но няма да се връщам към екипа на приложенията и да разбера дали има малка ефективност там, и ще пропусна компресирането на редове за това упражнение и ще се съсредоточа върху компресирането на страници и колони.
Това е копие на данните на неактивен сървър (8 ядра, 64GB RAM), с много дисково пространство (много над 6TB). Така че първо, нека добавим няколко файлови групи, една за стандартно клъстерирано хранилище за колони и една за разделена версия на таблицата (където всички освен най-новия дял ще бъдат компресирани с COLUMNSTORE_ARCHIVE , тъй като всички тези по-стари данни вече са „само за четене и рядко“):
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_PARTITIONED;
И след това някои файлове за тези файлови групи (по един файл на ядро, хубав и еднакъв размер от 256 GB):
ALTER DATABASE OCopy ADD FILE (name = N'CCI_1', size = 250000, filename = 'K:\Data\o_cci_1.mdf') TO FILEGROUP FG_CCI; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_8', size = 250000, filename = 'K:\Data\o_cci_8.mdf') TO FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_1', size = 250000, filename = 'K:\Data\o_p_1.mdf') TO FILEGROUP FG_CCI_PARTITIONED; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_8', size = 250000, filename = 'K:\Data\o_p_8.mdf') TO FILEGROUP FG_CCI_PARTITIONED;
На този конкретен хардуер (YMMV!), това отне около 10 секунди на файл и даде следното:
За да генерирам дяловете, наивно разделих данните "равномерно" - или поне така си мислех. Току-що взех 3,75 милиарда реда и разделих на нещо, което смятах, че ще бъде управляемо:38 дяла със 100 милиона реда в първите 37 дяла, а останалите в последния. (Запомнете, това е само част 1! Тук има присъщо предположение за равномерно разпределение на стойностите в изходната таблица, а също и около това, което е оптимално за популацията на редовите групи в таблицата местоназначение.) Създаването на схемата и функцията на дяловете за това е както следва:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES (100000000, 200000000, /* ... 33 more ... */ , 3600000000, 3700000000); CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID ALL TO (FG_CCI_PARTITIONED);
Използвам RANGE LEFT защото, както Катрин Вилхелмсен продължава да ми помага да ми напомня, това означава, че граничната стойност е част от дяла отляво. С други думи, стойностите, които посочвам, са максималните стойности във всеки дял (с дати обикновено искате RANGE RIGHT ).
След това създадох две копия на таблицата, по едно за всяка файлова група. Първият имаше стандартен клъстериран индекс на columnstore, като единствените разлики са OID колоната не е IDENTITY и изчислената колона е просто varbinary(8000) :
CREATE TABLE dbo.tblCCI ( OID bigint NOT NULL, -- ... other columns ... ) ON FG_CCI; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_IX ON dbo.tblCCI;
Вторият беше изграден върху схемата за дялове, така че първо се нуждаеше от именуван PK, който след това трябваше да бъде заменен с клъстериран индекс на columnstore (въпреки че Брент Озар показва в тази кратка публикация, че има някакъв неинтуитивен синтаксис, който ще постигне това с по-малко стъпки ):
CREATE TABLE dbo.tblCCI_Partitioned ( OID bigint NOT NULL, -- ... other columns ..., CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID (OID) ); GO ALTER TABLE dbo.tblCCI_Partitioned DROP CONSTRAINT PK_CCI_Part; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblCCI_Partitioned ON PS_OID (OID);
След това, за да поставя архивна компресия на всички, освен на последния дял, изпълних следното:
ALTER TABLE dbo.tblCCI_Part
REBUILD PARTITION = ALL WITH
(
DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (38),
DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 37)
); Сега бях готов да попълня тези таблици с данни, да измеря необходимото време и получения размер и да сравня. Модифицирах полезен скрипт за пакетиране от Анди Малън и вмъкнах редовете в двете таблици последователно, с размер на партидата от 10 милиона реда. Има много повече от това в реалния скрипт (включително актуализиране на таблица на опашката с напредък), но основно:
DECLARE @BatchSize int = 10000000, @MaxID bigint, @LastID bigint = 0;
SELECT @MaxID = MAX(OID) FROM dbo.tblOriginal;
WHILE @LastID < @MaxID
BEGIN
INSERT dbo.tblCCI
(
-- all columns except the computed column
)
SELECT -- all columns except the computed column
FROM dbo.tblOriginal AS o
WHERE o.CostID >= @LastID
AND o.CostID < @LastID + @BatchSize;
SET @LastID += @BatchSize;
END След като попълних и двете таблици на columnstore от оригиналния (некомпресиран) източник, възстанових тези дялове отново, за да изчистя всяка бъркотия в групата на редовете и речника. Накрая приложих компресиране на страницата на място към таблицата с източник. Ето времената и резултатите от компресията за всеки тип:
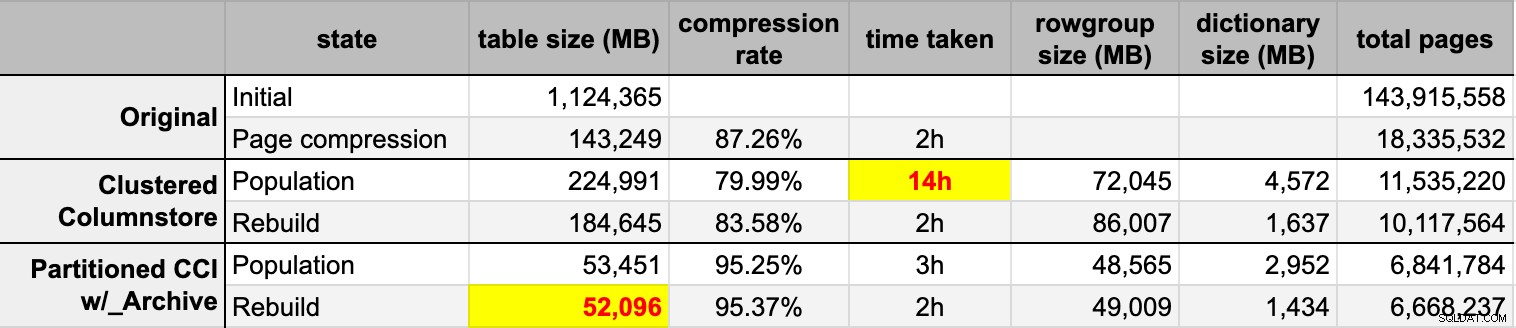
Аз съм едновременно впечатлен и разочарован. Впечатлен, защото тези данни се компресират наистина добре – намаляването на обема на съхранение до 5% от оригиналния 1TB е нещо невероятно. Разочарован, защото:
- Направих тези файлове с данни начин твърде голям.
- Не разбирам какво се случи с 14-часовата първоначална компресия на columnstore:
- Не забелязах натиск в паметта или журнала.
- Нямаше събития за растеж на файлове.
- За съжаление, не се сетих да проследя чаканията. Не, няма да го пробвам отново. :-)
- Компресията на страница превъзхожда обикновената компресия на columnstore – може би поради данните.
- Преизграждането на архивните дялове на columnstore изразходва много процесорно време за почти нулева печалба.
В предстоящи публикации и след като прегледах бележките си от невероятна презентация в магазина за колони от Джо Оббиш на PASS Summit (към който бих дал връзка директно, ако само PASS знаеше как да използва потребителския интерфейс), ще говоря малко за промените, които ще направя направете конфигурацията на сървъра и моя скрипт за населението, за да видя дали мога да получа по-добра производителност от популацията на columnstore.
[ Част 1 | Част 2 | Част 3 ]