Когато разглеждате производителността на заявките, има много страхотни източници на информация в SQL Server и един от любимите ми е самият план за заявка. В последните няколко издания, особено като се започне с SQL Server 2012, всяка нова версия включва повече подробности в плановете за изпълнение. Докато списъкът с подобрения продължава да нараства, ето няколко атрибута, които имам, които намирам за ценни:
- NonParallelPlanReason (SQL Server 2012)
- Диагностика на натискане на остатъчни предикати (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016 SP1)
- диагностика на разливане на tempdb (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016)
- Флаговете за проследяване са активирани (SQL Server 2012 SP4, SQL Server 2014 SP2, SQL Server 2016 SP1)
- Статистика за изпълнение на заявка на оператор (SQL Server 2014 SP2, SQL Server 2016)
- Максимално активирана памет за една заявка (SQL Server 2014 SP2, SQL Server 2016 SP1)
За да видите какво съществува за всяка версия на SQL Server, посетете страницата Showplan Schema, където можете да намерите схемата за всяка версия след SQL Server 2005.
Колкото и да обичам всички тези допълнителни данни, важно е да се отбележи, че част от информацията е по-подходяща за действителен план за изпълнение, в сравнение с прогнозен (например информация за tempdb spill). Някои дни можем да уловим и използваме действителния план за отстраняване на неизправности, друг път трябва да използваме прогнозния план. Много често получаваме този прогнозен план – планът, който е бил използван за потенциално проблемни изпълнения – от кеша на плановете на SQL Server. И изтеглянето на индивидуални планове е подходящо при настройка на конкретна заявка или набор или заявки. Но какво да кажем, когато искате идеи къде да съсредоточите усилията си за настройка по отношение на модели?
Кешът на плана на SQL Server е невероятен източник на информация, когато става въпрос за настройка на производителността и нямам предвид просто отстраняване на неизправности и опит да се разбере какво се изпълнява в системата. В този случай говоря за копаене на информация от самите планове, които се намират в sys.dm_exec_query_plan, съхранявани като XML в колоната query_plan.
Когато комбинирате тези данни с информация от sys.dm_exec_sql_text (за да можете лесно да видите текста на заявката) и sys.dm_exec_query_stats (статистически данни за изпълнението), можете внезапно да започнете да търсите не само тези заявки, които са най-силните или изпълнявани най-често, но тези планове, които съдържат определен тип присъединяване или сканиране на индекс, или тези, които имат най-висока цена. Това обикновено се нарича копаене на кеша на плана и има няколко публикации в блога, които говорят за това как да направите това. Моят колега Джонатан Кехайяс казва, че мрази да пише XML, но има няколко публикации със заявки за копаене на кеша на плана:
- Настройка на „прага на разходите за паралелизъм“ от кеша на плана
- Намиране на неявни преобразувания на колони в кеша на плана
- Намиране кои заявки в кеша на плана използват конкретен индекс
- Копаене в кеша на SQL план:намиране на липсващи индекси
- Намиране на ключови справки в кеша на плана
Ако никога не сте проучвали какво има в кеша на вашия план, запитванията в тези публикации са добро начало. Въпреки това, кешът на плана има своите ограничения. Например, възможно е да се изпълни заявка и планът да не влиза в кеша. Ако имате активирана опция за оптимизиране за adhoc работни натоварвания например, тогава при първото изпълнение компилираният план се съхранява в кеша на плана, а не в пълния компилиран план. Но най-голямото предизвикателство е, че кешът на плана е временен. Има много събития в SQL Server, които могат да изчистят кеша на плана изцяло или да го изчистят за база данни, а плановете могат да бъдат остарели извън кеша, ако не се използват, или премахнати след повторно компилиране. За да се борите с това, обикновено трябва или да заявявате редовно кеша на плана, или да правите моментни снимки на съдържанието в таблица по график.
Това се променя в SQL Server 2016 с Query Store.
Когато в дадена потребителска база данни е активирано хранилището на заявки, текстът и плановете за заявки, изпълнявани спрямо тази база данни, се улавят и запазват във вътрешни таблици. Вместо временен изглед на това, което се изпълнява в момента, имаме дългосрочна картина на това, което се е изпълнявало преди. Количеството запазени данни се определя от настройката CLEANUP_POLICY, която по подразбиране е 30 дни. В сравнение с планов кеш, който може да представлява само няколко часа изпълнение на заявка, данните от магазина на заявки променят играта.
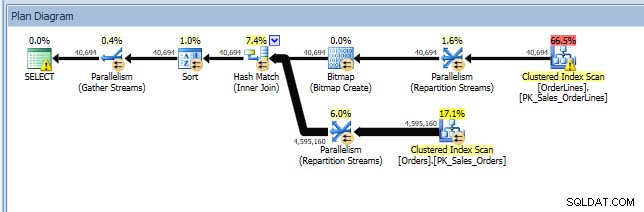
Помислете за сценарий, при който правите някакъв анализ на индекси – някои индекси не се използват и имате някои препоръки от липсващите индексни DMV. Липсващият индекс DMV не предоставя никакви подробности за това каква заявка е генерирала препоръката за липсващ индекс. Можете да направите заявка за кеша на плана, като използвате заявката от публикацията на Джонатан за намиране на липсващи индекси. Ако изпълня това срещу моя локален екземпляр на SQL Server, получавам няколко реда изход, свързани с някои заявки, които изпълнявах по-рано.

Мога да отворя плана в Plan Explorer и виждам, че има предупреждение в оператора SELECT, което е за липсващия индекс:
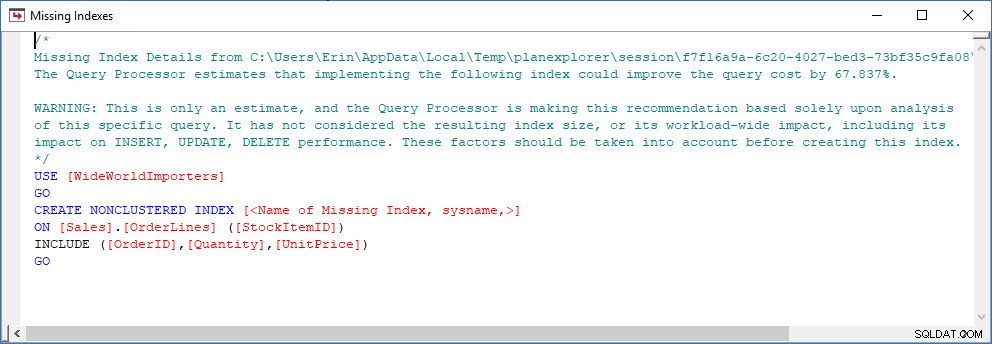
Това е страхотно начало, но отново, моята продукция зависи от това, което има в кеша. Мога да взема заявката на Джонатан и да променя за Query Store, след което да я стартирам в моята демонстрационна база данни WideWorldImporters:
USE WideWorldImporters;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT TRY_CONVERT(XML, [qsp].[query_plan]) AS [query_plan]
FROM sys.query_store_plan [qsp]) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1;
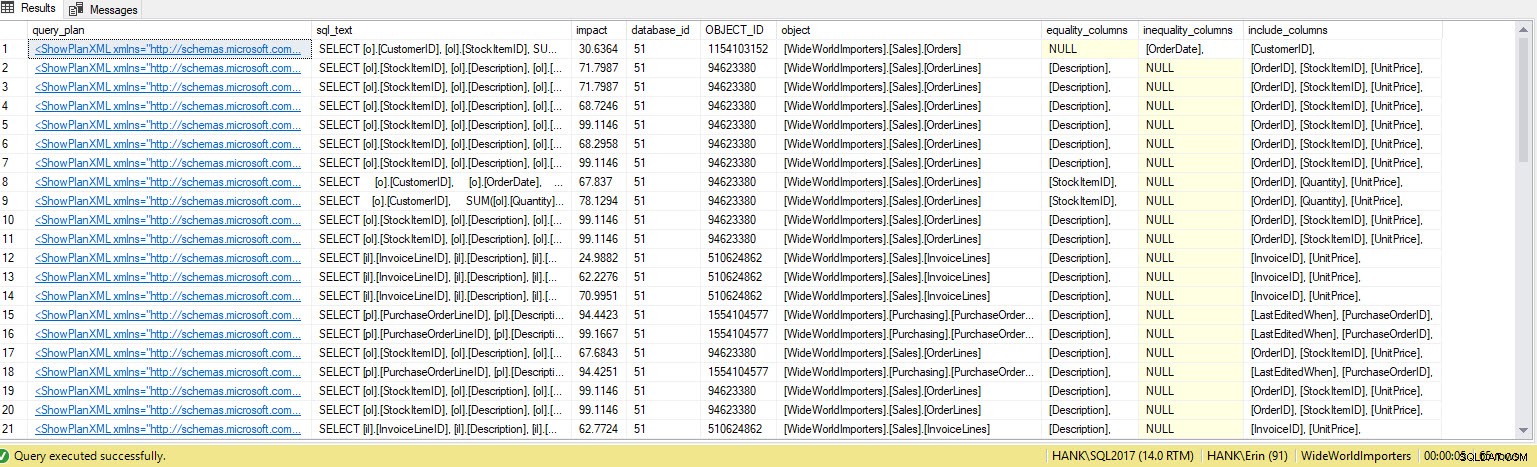
Получавам много повече редове в изхода. Отново данните от хранилището на заявки представляват по-голям изглед на заявките, изпълнявани срещу системата, и използването на тези данни ни дава изчерпателен метод да определим не само кои индекси липсват, но и какви заявки биха поддържали тези индекси. От тук можем да копаем по-дълбоко в магазина на заявки и да разгледаме показателите за производителност и честотата на изпълнение, за да разберем въздействието от създаването на индекса и да решим дали заявката се изпълнява достатъчно често, за да гарантира индекса.
Ако не използвате Query Store, но използвате SentryOne, можете да копаете същата информация от базата данни SentryOne. Планът на заявката се съхранява в таблицата dbo.PerformanceAnalysisPlan в компресиран формат, така че заявката, която използваме, е подобна вариация на горната, но ще забележите, че се използва и функцията DECOMPRESS:
USE SentryOne;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT -- need to decompress the gzipped xml here:
CONVERT(xml, CONVERT(nvarchar(max), CONVERT(varchar(max), DECOMPRESS(PlanTextGZ)))) AS [query_plan]
FROM dbo.PerformanceAnalysisPlan) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1; На една система SentryOne имах следния изход (и разбира се щракването върху някоя от стойностите на query_plan ще отвори графичния план):

Няколко предимства, които SentryOne предлага пред Query Store, са, че не е нужно да активирате този тип колекция за база данни и наблюдаваната база данни не трябва да поддържа изискванията за съхранение, тъй като всички данни се съхраняват в хранилището. Можете също да уловите тази информация във всички поддържани версии на SQL Server, а не само в тези, които поддържат Query Store. Имайте предвид обаче, че SentryOne събира само заявки, които надхвърлят прагове, като продължителност и четения. Можете да настроите тези прагове по подразбиране, но това е един елемент, който трябва да имате предвид, когато копаете базата данни SentryOne:не всички заявки може да бъдат събрани. В допълнение, функцията DECOMPRESS не е налична до SQL Server 2016; за по-стари версии на SQL Server, ще искате да:
- Архивирайте базата данни SentryOne и я възстановете на SQL Server 2016 или по-нова версия, за да изпълните заявките;
- bcp данните от таблицата dbo.PerformanceAnalysisPlan и ги импортирайте в нова таблица на екземпляр на SQL Server 2016;
- запитване на базата данни SentryOne чрез свързан сървър от екземпляр на SQL Server 2016; или,
- запитване на базата данни от кода на приложението, който може да анализира за конкретни неща след декомпресиране.
Със SentryOne имате възможността да копаете не само кеша на плана, но и данните, запазени в хранилището на SentryOne. Ако използвате SQL Server 2016 или по-нова версия и имате активиран магазин за заявки, можете също да намерите тази информация в sys.query_store_plan . Не сте ограничени само до този пример за намиране на липсващи индекси; всички заявки от другите публикации в кеша на плана на Джонатан могат да бъдат модифицирани, за да се използват за копаене на данни от SentryOne или от Query Store. Освен това, ако сте достатъчно запознати с XQuery (или желаете да научите), можете да използвате схемата на Showplan, за да разберете как да анализирате плана, за да намерите информацията, която искате. Това ви дава възможност да намирате модели и анти-модели във вашите планове за заявка, които вашият екип може да коригира, преди да се превърнат в проблем.