Когато планът за изпълнение включва сканиране на индексна структура на b-дърво, механизмът за съхранение може да можете да избирате между две стратегии за физически достъп, когато планът се изпълнява:
- Следвайте индексната b-дървова структура; или
- намерете страници, като използвате информация за вътрешно разпределение на страници.
Когато е наличен избор, механизмът за съхранение взема решението по време на изпълнение при всяко изпълнение. Прекомпилирането на план ене необходимо, за да промени решението си.
Стратегията b-дърво започва от корена на дървото, слиза до краен ръб на нивото на листа (в зависимост от това дали сканирането е напред или назад), след което следва връзките на страницата на ниво лист, докато се достигне до другия край на индекса . Стратегията за разпределение използва структури на карта за разпределение на индекса (IAM), за да намери страници от база данни, разпределени към индекса. Всяка IAM страница съпоставя разпределения в интервал от 4 GB в един файл с физическа база данни, така че сканирането на IAM веригите, свързани с индекс, има тенденция за достъп до индексни страници във физически файлов ред (поне доколкото SQL Server може да каже).
Основните разлики между двете стратегии са:
- Сканирането на b-дърво може да доставя редове на процесора на заявки в ред на индексни ключове; IAM-управлявано сканиране не може;
- сканирането на b-дърво може да не е в състояние да издаде големи заявки за I/O за четене напред, ако логически съседните индексни страници не са и физически съседни (напр. в резултат на разделяне на страницата в индекса).
Сканиране на b-дърво винаги е налично за индекс. Условията, които често се цитират, за да бъдат налични сканирания на поръчката за разпределение, са:
- Планът на заявката трябва да позволява неподредено сканиране на индекса;
- индексът трябва да е с размер най-малко 64 страници; и,
- или
TABLOCKилиNOLOCKнамек трябва да бъде посочен.
Първото условие просто означава, че оптимизаторът на заявки трябва да е маркирал сканирането с Ordered:False Имот. Маркиране на сканирането Ordered:False означава, че правилните резултати от плана за изпълнение не изискват сканирането за връщане на редове в реда на индексни ключове (въпреки че може да го направи, ако е удобно или по друг начин необходимо).
Второто условие (размер) важи само за SQL Server 2005 и по-нови версии. Той отразява факта, че има определени начални разходи за извършване на сканиране, управлявано от IAM, така че трябва да има минимален брой страници, за да могат потенциалните спестявания да изплатят първоначалната инвестиция. „64 страници“ се отнася до стойността на data_pages за IN_ROW_DATA само единица за разпределение, както е отчетено в sys.allocation_units.
Разбира се, може да има изплащане от сканиране на поръчка за разпределение само ако евентуално по-големите съображения за предсрочно четене действително влизат в игра, но SQL Server в момента не отчита този фактор. По-специално, той не отчита каква част от индекса е в момента в паметта, нито го интересува колко фрагментиран е индексът.
Третото условие е може би най-малко пълното описание в списъка. Подсказките всъщност не са задължителни , въпреки че могат да се използват, за да отговарят на реалните изисквания:Данните трябва да са гарантирано, че няма да се променят по време на сканирането или (по-противоречиво) трябва да посочим, че не ни пука относно потенциално неточни резултати, чрез извършване на сканирането на ниво на изолация на прочетеното незаето.
Дори и с тези разяснения, списъкът с условия за сканиране, наредено за разпределение, все още не е пълен. Има редица важни предупреждения и изключения, до които ще стигнем скоро.
Демо
Следната заявка използва примерната база данни на AdventureWorks:
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P; Имайте предвид, че таблицата с лицата съдържа 3869 страници. Планът след изпълнение (действителният) е както следва (показан в SQL Sentry Plan Explorer):
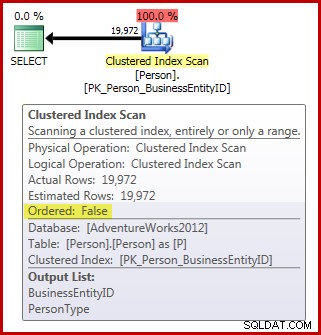
По отношение на изискванията за сканиране на поръчката за разпределение, които имаме досега:
- Планът има задължителния
Ordered:FalseИмот; и, - таблицата има повече от 64 страници; но,
- не направихме нищо, за да гарантираме, че данните не могат да се променят по време на сканирането. Ако приемем, че нашата сесия използва прочетеното по подразбиране ниво на изолация, сканирането не се извършва при прочетено без ангажимент ниво на изолация също.
В резултат на това бихме очаквали това сканиране да се извърши чрез сканиране на b-дървото, а не да се управлява от IAM. Резултатите от заявката показват, че това вероятно е вярно:
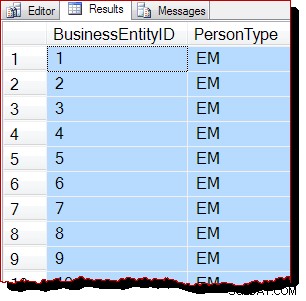
Редовете се връщат в ключов ред на клъстериран индекс (по BusinessEntityID ). Трябва ясно да заявя, че това подреждане на резултата не е гарантирано , и не трябва да се разчита. Поръчаните резултати се гарантират само от подходящ ORDER BY от най-високо ниво клауза.
Независимо от това, наблюдаваният изходен ред е косвено доказателство, че сканирането е извършено този път чрез следване на клъстерираната индексна b-дървова структура. Ако са необходими повече доказателства, можем да прикачим дебъгер и да разгледаме пътя на кода, който SQL Server изпълнява по време на сканирането:

Стекът от повиквания ясно показва сканирането след b-дървото.
Добавяне на подсказка за заключване на таблица
Сега модифицираме заявката, за да включва подсказка за заключване на таблица:
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (TABLOCK); При ниво на изолация на ангажимент за четене за заключване, споделеното заключване на ниво таблица предотвратява всякакви възможни едновременни модификации на данните. При изпълнени и трите предварителни условия за сканиране, управлявано от IAM, сега бихме очаквали SQL Server да използва сканиране по ред за разпределение. Планът за изпълнение е същият като преди, така че няма да го повтарям, но резултатите от заявката със сигурност изглеждат различно:
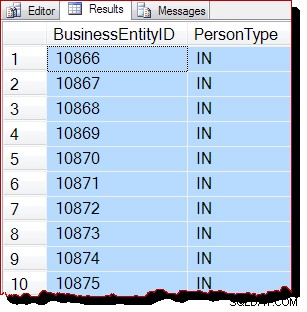
Резултатите очевидно все още са подредени по BusinessEntityID , но отправната точка (10866) е различна. Всъщност, ако превъртим надолу резултатите, скоро ще се натъкнем на секции, които по-очевидно са извън ключовия ред:
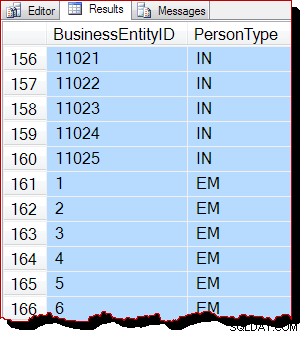
Частичното подреждане се дължи на сканирането на реда за разпределение, което обработва цяла индексна страница наведнъж. Резултатите в рамките на страница случайно се връща подредено от индексния ключ, но редът на сканираните страници вече е различен. Отново трябва да подчертая, че резултатите може да изглеждат различно за вас:няма гаранция за изходен ред, дори в рамките на една страница, без ORDER BY от най-високо ниво на оригиналната заявка.
За сравнение със стека от повиквания, показан по-рано, това е проследяване на стека, получено, докато SQL Server обработваше заявката с TABLOCK намек:
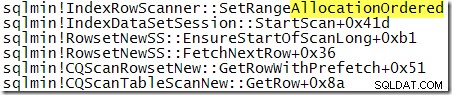
Пристъпваме малко по-напред през изпълнението:

Ясно е, че SQL Server извършва подредено по разпределение сканиране, когато е посочено заключване на таблицата. Жалко е, че в плана след изпълнение няма индикация кой тип сканиране е използван по време на изпълнение. Като напомняне, типът на сканиране се избира от механизма за съхранение и може да се променя между изпълненията без прекомпилиране на план.
Други начини за изпълнение на третото условие
По-рано казах, че за да получим управлявано от IAM сканиране, трябва да гарантираме, че данните не могат да се променят под сканирането, докато то е в ход, или трябва да изпълним заявката на ниво на изолация за четене без ангажимент. Видяхме, че подсказката за заключване на таблицата за заключване на изолацията при четене е достатъчна, за да отговори на първото от тези изисквания и е лесно да се покаже, че с помощта на NOLOCK/READUNCOMMITTED hint също така позволява сканиране на реда за разпределение с демонстрационната заявка.
Всъщност има много начини да се изпълни третото условие, включително:
- Промяна на индекса за разрешаване само на заключвания на таблица;
- правяне на базата данни само за четене (така че данните са гарантирани, че няма да се променят); или,
- промяна на сесията ниво на изолация до
READ UNCOMMITTED.
Има обаче много по-интересни вариации на тази тема, което означава, че трябва да променим трите условия, посочени по-рано...
Нива на изолация на версии на ред
Активирайте изолацията на моментни снимки за четене (RCSI) в базата данни на AdventureWorks и стартирайте теста с TABLOCK намек отново (при четене на извършена изолация):
ALTER DATABASE AdventureWorks2012
SET READ_COMMITTED_SNAPSHOT ON
WITH ROLLBACK IMMEDIATE;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
GO
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (TABLOCK);
GO
ALTER DATABASE AdventureWorks2012
SET READ_COMMITTED_SNAPSHOT OFF
WITH ROLLBACK IMMEDIATE;
С активен RCSI, индексно подреден сканирането се използва с TABLOCK , а не сканирането на реда за разпределение, което видяхме точно преди. Причината е TABLOCK hint определя споделено заключване на ниво таблица, но с активиран RCSI, без споделени заключвания са взети. Без заключването на споделената таблица не сме изпълнили изискването за предотвратяване на едновременни модификации на данните, докато сканирането е в ход, така че не може да се използва сканиране, подредено за разпределение.
Постигането на подредено по разпределение сканиране, когато RCSI е активиран, обаче е възможно. Един от начините е да използвате TABLOCKX намек (за изключително ниво на таблица заключване) вместо TABLOCK . Бихме могли също да запазим TABLOCK намекнете и добавете още един като READCOMMITTEDLOCK , или REPEATABLE READ или SERIALIZABLE … и така нататък. Всички те работят, като предотвратяват възможността от едновременни модификации чрез заключване на споделена таблица, с цената на загуба на предимствата на RCSI . Можем също така да постигнем сканиране на реда за разпределение с помощта на NOLOCK или READUNCOMMITTED намек, разбира се.
Ситуацията при изолация на моментни снимки (SI) е много подобна на RCSI и не е проучена подробно поради космически причини.
TABLESAMPLE винаги* извършва сканиране по реда на разпределение
TABLESAMPLE клаузата е интересно изключение от много от нещата, които обсъждахме досега.
Посочване на TABLESAMPLE клаузата винаги* води до сканиране на реда за разпределение, дори под RCSI или SI, и дори без намеци. За да е ясно, сканирането на реда за разпределение, което е резултат от използването на TABLESAMPLE запазва RCSI/SI семантиката – сканирането използва версии на редове и четенето не блокира писането (и обратно).
Втора изненада е, че TABLESAMPLE винаги* извършва управлявано от IAM сканиране дори ако таблицата има по-малко от 64 страници . Това има някакъв смисъл, тъй като документацията поне намеква, че SYSTEM методът за вземане на проби използва структурата на IAM (така че няма друг избор, освен да се направи сканиране на реда за разпределение):
СИСТЕМА е зависим от изпълнението метод за вземане на проби, определен от стандартите на ISO. В SQL Server това е единственият наличен метод за вземане на проби и се прилага по подразбиране. SYSTEM прилага метод за извадка, базиран на страници, при който произволен набор от страници от таблицата се избира за извадката и всички редове на тези страници се връщат като подмножество на извадката.
* Изключение възниква, ако ROWS или PERCENT спецификация в TABLESAMPLE клаузата означава 100% от таблицата. Посочване на още ROWS отколкото метаданните показват, че в момента са в таблицата, също няма да работи. Използване на TABLESAMPLE SYSTEM (100 PERCENT) или еквивалент не принудително сканиране на поръчката за разпределение.
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
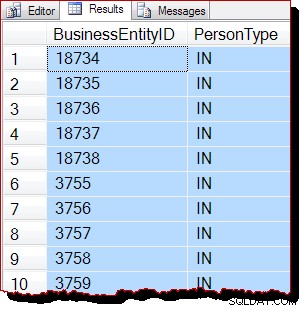
TABLESAMPLE SYSTEM (50 ROWS)
REPEATABLE (12345678)
--WITH (TABLOCK); Резултати:
Ефектът на TOP и SET ROWCOUNT
Накратко, нито едно от тях няма никакъв ефект върху решението да се използва сканиране на поръчка за разпределение или не. Това може да изглежда изненадващо в случаите, когато е „очевидно“, че ще бъдат сканирани по-малко от 64 страници.
Например и двете заявки използват управлявано от IAM сканиране, за да върнат 5 реда от сканиране:
SELECT TOP (5)
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P WITH (TABLOCK)
SET ROWCOUNT 5;
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P WITH (TABLOCK)
SET ROWCOUNT 0; Резултатите са еднакви и за двете:
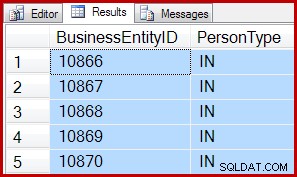
Това означава, че TOP и SET ROWCOUNT заявки може да поемат режийни разходи за настройване на сканиране на поръчка за разпределение, дори ако са сканирани по-малко от 64 страници. Като смекчаване, по-сложните TOP заявки със селективни предикати, избутани в сканирането, все още могат да се възползват от сканиране на реда за разпределение. Ако сканирането трябва да обработи 10 000 страници, за да намери първите 5 реда, които съвпадат, сканирането по реда на разпределение все още може да бъде печелившо.
Предотвратяване на всички* сканирания по ред за разпределение в целия екземпляр
Това не е нещо, което вероятно някога бихте направили умишлено, но има настройка на сървъра, която ще предотврати сканиране по реда на разпределение за всички* потребителски заявки във всички бази данни.
Колкото и малко вероятно да изглежда, въпросната настройка е опцията за конфигурация на сървъра за праг на курсора, която има следното описание в Books Online:
Опцията за праг на курсора определя броя на редовете в набора от курсори, при които наборите от курсорни клавиши се генерират асинхронно. Когато курсорите генерират набор от ключове за набор от резултати, оптимизаторът на заявки изчислява броя на редовете, които ще бъдат върнати за този набор от резултати. Ако оптимизаторът на заявки прецени, че броят на върнатите редове е по-голям от този праг, курсорът се генерира асинхронно, което позволява на потребителя да извлича редове от курсора, докато курсорът продължава да се попълва. В противен случай курсорът се генерира синхронно и заявката изчаква, докато се върнат всички редове.
Ако cursor threshold опцията е зададена на всичко различно от –1 (по подразбиране), няма да се извършват сканирания по реда на разпределение за потребителски заявки в която и да е база данни на екземпляра на SQL Server.
С други думи, ако асинхронната популация на курсора е активирана, няма сканиране, управлявано от IAM.
* Изключението е (не-100%) TABLESAMPLE запитвания. Вътрешните заявки, генерирани от системата за създаване на статистически данни и актуализации на статистически данни, също продължават да използват подредени по разпределение сканирания.
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
-- WARNING! Disables allocation-order scans instance-wide
EXECUTE sys.sp_configure
@configname = 'cursor threshold',
@configvalue = 5000;
RECONFIGURE WITH OVERRIDE;
GO
-- Would normally result in an allocation-order scan
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (READUNCOMMITTED);
GO
-- Reset to default allocation-order scans
EXECUTE sys.sp_configure
@configname = 'cursor threshold',
@configvalue = -1;
RECONFIGURE WITH OVERRIDE; Резултати (без сканиране на реда за разпределение):
Може само да се гадае, че асинхронната популация на курсора не работи добре със сканиране на реда за разпределение по някаква причина. Напълно неочаквано е това ограничение да засегне всички потребителски заявки без курсор както и все пак. Може би е твърде трудно за SQL Server да открие дали заявка се изпълнява като част от външно издаден курсор на API? Кой знае.
Би било хубаво този страничен ефект да бъде официално документиран някъде, въпреки че е трудно да се знае точно къде трябва да отиде в Books Online. Чудя се колко производствени системи не използват сканиране на поръчката за разпределение поради това? Може би не са много, но никога не се знае.
За да приключим нещата, ето едно резюме. Сканиране, подредено за разпределение, е налично, ако:
- Сървърната опция
cursor thresholdе настроен на –1 (по подразбиране); и, - операторът за сканиране на плана на заявката има
Ordered:FalseИмот; и, - общия брой страници с_данни от
IN_ROW_DATAединици за разпределение е най-малко 64; и, - или:
- SQL Server има приемлива гаранция, че едновременните модификации са невъзможни; или,
- сканирането се изпълнява на ниво на изолация на незаетото четене.
Независимо от всичко по-горе, сканиране с TABLESAMPLE Клаузата винаги използва подредени по разпределение сканирания (с едното техническо изключение, отбелязано в основния текст).