Забележка:Тази публикация първоначално е публикувана само в нашата електронна книга, Високопроизводителни техники за SQL Server, том 2. Можете да научите за нашите електронни книги тук.
Резюме:Тази статия разглежда изненадващо поведение на задействанията INSTEAD OF и разкрива сериозна грешка при оценката на кардиналността в SQL Server 2014.
Задействания и версия на редове
Само тригерите DML AFTER използват версия на редове (в SQL Server 2005 нататък), за да предоставят вмъкнатите и изтрити псевдо-таблици в тригерна процедура. Тази точка не е ясно изразена в голяма част от официалната документация. На повечето места документацията просто казва, че версията на реда се използва за изграждане на вмъкнатите и изтрити таблици в тригери без квалификация (примери по-долу):
Използване на ресурси за версии на ред
Разбиране на нивата на изолация, базирани на версии на ред
Контролиране на изпълнението на тригери при групово импортиране на данни
Предполага се, че оригиналните версии на тези записи са написани преди ВМЕСТО тригерите да бъдат добавени към продукта и никога не са актуализирани. Или това, или това е прост (но повтарящ се) пропуск.
Както и да е, начинът, по който версията на реда работи с тригери AFTER е доста интуитивен. Тези тригери се задействат след въпросните модификации са извършени, така че е лесно да се види как поддържането на версии на модифицираните редове позволява на машината на базата данни да предостави вмъкнатите и изтрити псевдо-таблици. Изтритият псевдотаблицата е изградена от версии на засегнатите редове преди модификациите да са извършени; вмъкнато Псевдотаблицата се формира от версиите на засегнатите редове към момента на стартиране на процедурата за задействане.
Вместо тригери
INSTEAD OF тригери са различни, защото този тип DML тригери напълно заменя задействаното действие. Вмъкнато и изтрити псевдотаблиците вече представляват промени, които ще има е направено, ако задействащият оператор действително е изпълнен. Версионирането на реда не може да се използва за тези тригери, тъй като по дефиниция не са настъпили модификации. И така, ако не използвате версии на редове, как SQL Server го прави?
Отговорът е, че SQL Server променя плана за изпълнение на задействащия DML израз, когато съществува тригер INSTEAD OF. Вместо да променя директно засегнатите таблици, планът за изпълнение записва информация за промените в скрита работна таблица. Тази работна таблица съдържа всички данни, необходими за извършване на оригиналните промени, типа модификация, която да се извърши на всеки ред (изтриване или вмъкване), както и всякаква информация, необходима в тригера за клауза OUTPUT.
План за изпълнение без тригер
За да видим всичко това в действие, първо ще изпълним прост тест без присъстващ тригер ВМЕСТО:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Планът за изпълнение на изтриването е много ясен:
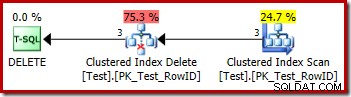
Всеки ред, който отговаря на изискванията, се предава директно на оператор за изтриване на клъстериран индекс, който го изтрива. Лесно.
План за изпълнение със задействане ВМЕСТО
Сега нека модифицираме теста, за да включим тригер ВМЕСТО ИЗТРИВАНЕ (това, което просто изпълнява същото действие за изтриване за простота):
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Планът за изпълнение на DELETE вече е доста различен:
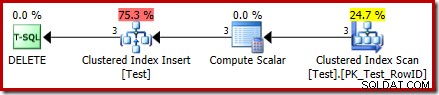
Операторът Clustered Index Delete е заменен от Clustered Index Insert . Това е вмъкването към скритата работна таблица, която се преименува (в публичното представяне на план за изпълнение) на името на основната таблица, засегната от изтриването. Преименуването се случва, когато планът за показване на XML се генерира от вътрешното представяне на плана за изпълнение, така че няма документиран начин да видите скритата работна маса.
В резултат на тази промяна изглежда, че планът изпълнява вмъкване към основната таблица, за да изтриете редове от него. Това е объркващо, но най-малкото разкрива наличието на спусък ВМЕСТО. Замяната на оператора Insert с Delete може да бъде още по-объркваща. Може би идеалът би бил нова графична икона за работна маса ВМЕСТО задействане? Както и да е, това е.
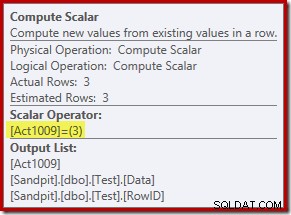
Новият оператор Compute Scalar дефинира вида на действието, извършвано на всеки ред. Този код за действие е цяло число със следните значения:
- 3 =ИЗТРИВАНЕ
- 4 =INSERT
- 259 =ИЗТРИВАНЕ в план за СЛИВАНЕ
- 260 =ВМЪКВАНЕ в план MERGE
За тази заявка действието е константа 3, което означава, че всеки ред трябва да бъде изтрит :
Действия за актуализиране
Като настрана, планът за изпълнение ВМЕСТО АКТУАЛИЗИРА заменя един оператор Update с два Клъстериран индекс Вмъква в същата скрита работна маса – една за вмъкнатите редове на псевдотаблица и един за изтритите редове на псевдотаблици. Примерен план за изпълнение:

MERGE, който извършва UPDATE, също така произвежда план за изпълнение с две вмъквания към една и съща базова таблица по подобни причини:

Планът за изпълнение на тригера
Планът за изпълнение на спусъка също има някои интересни функции:
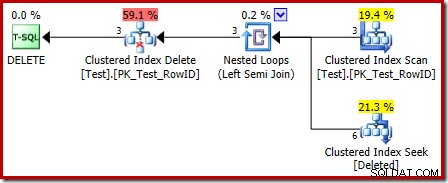
Първото нещо, което трябва да забележите, е, че графичната икона, използвана за изтритата таблица, не е същата като иконата, използвана в плановете за задействане AFTER:
Представянето в плана за задействане INSTEAD OF е групирано търсене на индекс. Основният обект е същата вътрешна работна таблица, която видяхме по-рано, въпреки че тук е наречен deleted вместо да получи името на основната таблица, вероятно за някакъв вид съгласуваност с тригерите AFTER.
Операцията за търсене на изтрито таблицата може да не е това, което очаквахте (ако сте очаквали търсене на RowID):
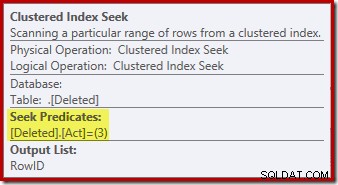
Това „търсене“ връща всички редове от работната таблица, които имат код за действие 3 (изтриване), което го прави точно еквивалентен на Изтрито сканиране оператор, видян в плановете за задействане AFTER. Една и съща вътрешна работна маса се използва за задържане на редове и за двата вмъкнати и изтрити псевдо-таблици в тригери ВМЕСТО. Еквивалентът на вмъкнато сканиране е търсене на код за действие 4 (което е възможно при изтриване тригер, но резултатът винаги ще бъде празен). Във вътрешната работна маса няма индекси освен неуникалния клъстериран индекс на действие колона сама. Освен това няма статистически данни, свързани с този вътрешен индекс.
Анализът досега може да ви накара да се чудите къде се извършва свързването между колоните RowID. Това сравнение се извършва при оператора Nested Loops Left Semi Join като остатъчен предикат:
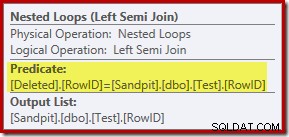
Сега, когато знаем, че „търсене“ е на практика пълно сканиране на изтритите таблица, планът за изпълнение, избран от оптимизатора на заявки, изглежда доста неефективен. Общият поток на плана за изпълнение е, че всеки ред от тестовата таблица потенциално се сравнява с целия набор от изтрити редове, което звучи много като декартов продукт.
Спестяването е, че присъединяването е полусъединяване, което означава, че процесът на сравнение спира за даден тестов ред веднага след като първият изтрит ред удовлетворява остатъчния предикат. Въпреки това стратегията изглежда любопитна. Може би планът за изпълнение би бил по-добър, ако тестовата таблица съдържаше повече редове?
Тест на задействане с 1000 реда
Следният скрипт може да се използва за тестване на тригера с по-голям брой редове. Ще започнем с 1000:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 1000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Планът за изпълнение на задействащото тяло сега е:
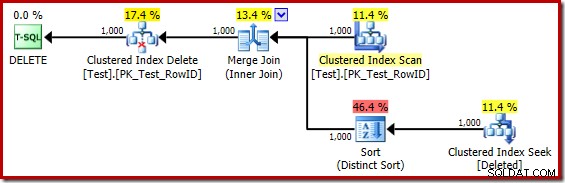
Мислено заменяйки (подвеждащото) търсене на клъстериран индекс с изтрито сканиране, планът като цяло изглежда доста добър. Оптимизаторът е избрал едно към много Merge Join вместо Semi Join с вложени цикли, което изглежда разумно. Различният сорт обаче е любопитно допълнение:
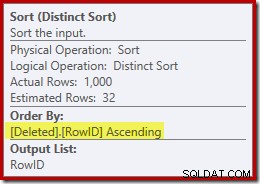
Този сорт изпълнява две функции. Първо, той предоставя обединението за сливане с сортирания вход, от който се нуждае, което е достатъчно справедливо, защото няма индекс във вътрешната работна маса, който да осигури необходимия ред. Второто нещо, което сортът прави, е да се разграничи по RowID. Това може да изглежда странно, защото RowID е първичният ключ на основната таблица.
Проблемът е, че редовете в изтрити таблицата са просто кандидат редове, идентифицирани от оригиналната заявка DELETE. За разлика от тригера AFTER, тези редове все още не са проверени за ограничения или ключови нарушения, така че процесорът на заявки няма гаранция, че всъщност са уникални.
Като цяло, това е много важен момент, който трябва да се има предвид при задействанията INSTEAD OF:няма гаранция, че предоставените редове отговарят на някое от ограниченията на основната таблица (включително NOT NULL). Това е важно не само за автора на тригера да запомни; също така ограничава опростяванията и трансформациите, които оптимизаторът на заявки може да извърши.
Втори проблем, показан в свойствата за сортиране по-горе, но не подчертан, е, че изходната оценка е само 32 реда. Вътрешната работна таблица няма статистически данни, свързани с нея, така че оптимизаторът предполага при ефекта на отделната операция. Знаем, че стойностите на RowID са уникални, но без никаква твърда информация за продължаване, оптимизаторът прави лошо предположение. Този проблем ще ни преследва отново при следващия тест.
Тест на задействане с 5000 реда
Сега променете тестовия скрипт, за да генерирате 5000 реда:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 5000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Планът за изпълнение на тригера е:
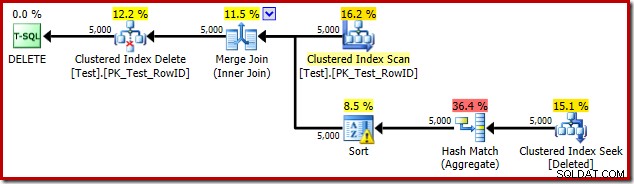
Този път оптимизаторът е решил да раздели отделните и сортиращи операции. Разграничаването на RowID се извършва от оператора Hash Match (Aggregate):
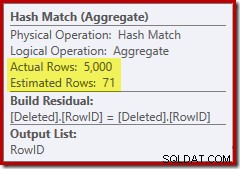
Забележете, че оценката на оптимизатора за изхода е 71 реда. Всъщност всичките 5000 реда оцеляват в отделните, защото RowID е уникален. Неточната оценка означава, че неадекватна част от предоставената памет за заявка се разпределя на сортирането, което в крайна сметка се разлива в tempdb :
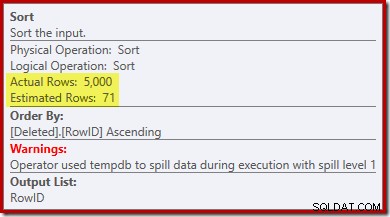
Този тест трябва да се извърши на SQL Server 2012 или по-нова версия, за да се види предупреждението за сортиране в плана за изпълнение. В предишните версии планът не съдържа информация за разливи – ще е необходима проследяване на Profiler за събитието Sort Warnings, за да го разкрие (и ще трябва по някакъв начин да го свържете с изходната заявка).
Тест на задействане с 5000 реда на SQL Server 2014
Ако предишният тест се повтори на SQL Server 2014, в база данни, зададена на ниво на съвместимост 120, така че се използва новият оценител на мощността (CE), планът за изпълнение на тригера отново е различен:
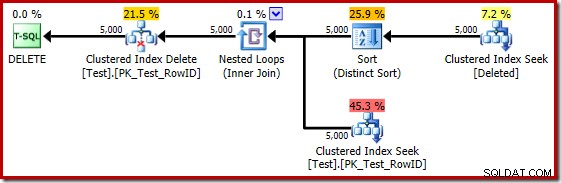
В известен смисъл този план за изпълнение изглежда като подобрение. (Ненужният) Distinct Sort все още е налице, но цялостната стратегия изглежда по-естествена:за всеки отделен кандидат RowID в изтрития таблица, присъединете се към основната таблица (така че да проверите дали редът кандидат действително съществува) и след това го изтрийте.
За съжаление, планът за 2014 г. се основава на по-лоши оценки на кардиналността, отколкото видяхме в SQL Server 2012. Превключване на SQL Sentry Plan Explorer за показване на приблизителната броят на редовете показва ясно проблема:
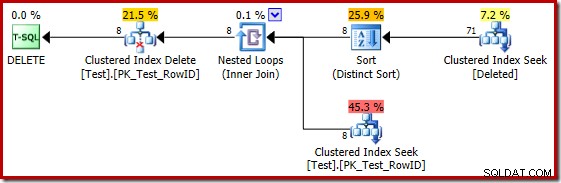
Оптимизаторът избра стратегия за вложени цикли за присъединяването, защото очакваше много малък брой редове на горния вход. Първият проблем възниква при търсенето на клъстериран индекс. Оптимизаторът знае, че изтритата таблица съдържа 5000 реда в този момент, както можем да видим, като преминем към изглед на дървото на плановете и добавим незадължителната колона Кардиналност на таблицата (която искам да бъде включена по подразбиране):
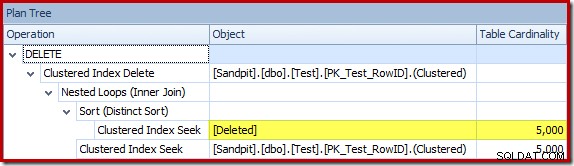
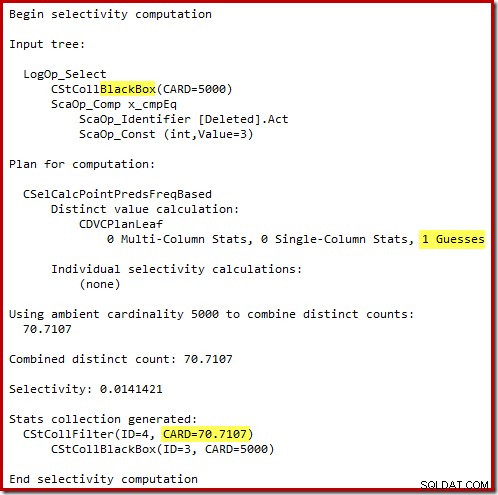
„Старият“ оценител на мощността в SQL Server 2012 и по-ранни версии е достатъчно интелигентен, за да знае, че „търсене“ на вътрешната работна таблица ще върне всичките 5000 реда (така че избра обединяване за сливане). Новият CE не е толкова умен. Той вижда работната маса като „черна кутия“ и предполага ефекта от търсенето върху кода на действие =3:
Предположението за 71 реда (закръглено нагоре) е доста мизерен резултат, но грешката се усложнява, когато новият CE оценява редовете за отделната операция на тези 71 реда:
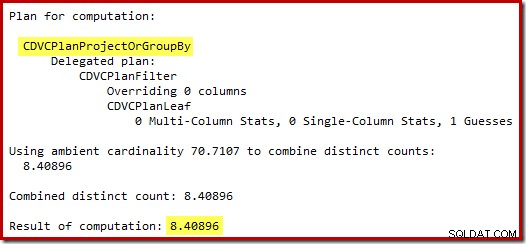
Въз основа на очакваните 8 реда, оптимизаторът избира стратегията за вложени цикли. Друг начин да видите тези грешки при оценката е да добавите следното изявление към тялото на тригера (само за тестови цели):
SELECT COUNT_BIG(DISTINCT RowID) FROM Deleted;
Прогнозният план показва ясно грешките при оценката:
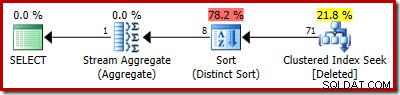
Действителният план все още показва 5000 реда, разбира се:
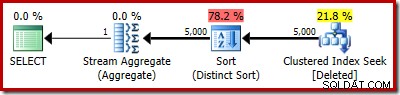
Или можете да сравните прогнозата с действителната по едно и също време в изглед на дървото на плановете:
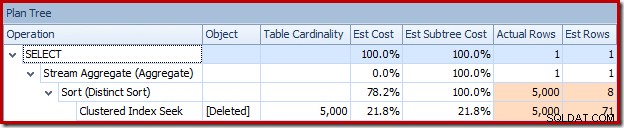
Милион реда...
Лошите предположения при използване на оценителя на мощността за 2014 карат оптимизатора да избере стратегия за вложени цикли, дори когато тестовата таблица съдържа милион реда. Новият CE от 2014 г. оценен планът за този тест е:
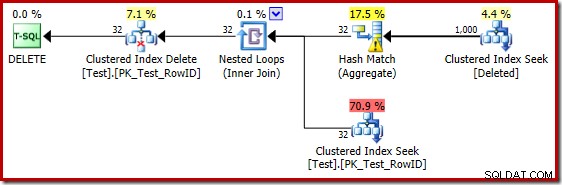
„Търсене“ оценява 1 000 реда от известната мощност от 1 000 000, а отделната оценка е 32 реда. Планът след изпълнение разкрива ефекта върху паметта, запазена за Hash Match:
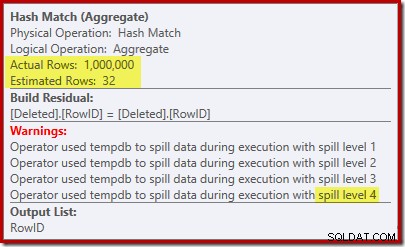
Очаквайки само 32 реда, Hash Match изпада в реални проблеми, като рекурсивно разлива своята хеш таблица, преди евентуално да завърши.
Последни мисли
Въпреки че е вярно, че задействането никога не трябва да се пише, за да направи нещо, което може да бъде постигнато с декларативна референтна цялост, също така е вярно, че добре написаното тригер, който използва ефективен планът за изпълнение може да бъде сравним по производителност с разходите за поддържане на допълнителен неклъстериран индекс.
Има два практически проблема с горното твърдение. Първо (и с най-добрата воля в света) хората не винаги пишат добър код за задействане. Второ, получаването на добър план за изпълнение от оптимизатора на заявки при всякакви обстоятелства може да бъде трудно. Естеството на тригерите е, че те се извикват с широк спектър от входни мощности и разпределения на данни.
Дори за тригери AFTER, липсата на индекси и статистика за изтритите и вмъкнати псевдо-таблици означава, че изборът на план често се основава на предположения или дезинформация. Дори когато първоначално е избран добър план, по-късните изпълнения може да използват повторно същия план, когато прекомпилирането би било по-добър избор. Има начини за заобикаляне на ограниченията, главно чрез използване на временни таблици и изрични индекси/статистически данни, но дори и там се изисква голямо внимание (тъй като тригерите са форма на съхранена процедура).
С тригери INSTEAD OF рисковете могат да бъдат дори по-големи, тъй като съдържанието на вмъкнатите и изтрити таблиците са непроверени кандидати – оптимизаторът на заявки не може да използва ограничения върху основната таблица, за да опрости и прецизира своя план за изпълнение. Новият оценител на мощността в SQL Server 2014 също представлява реална стъпка назад, когато става въпрос за планове ВМЕСТО за задействане. Отгатването за ефекта от операцията за търсене, която двигателят въведе, е изненадващ и нежелан пропуск.