Преди няколко дни беше пускането на нова версия на ClusterControl, 1.7.1, където можем да видим няколко нови функции, една от основните е поддръжката на PostgreSQL 11.
За да инсталираме PostgreSQL 11 ръчно, първо трябва да добавим хранилищата или да изтеглим необходимите пакети за инсталацията, да ги инсталираме и да ги конфигурираме правилно, в зависимост от нашата инфраструктура. Всички тези стъпки отнемат време, така че нека видим как бихме могли да избегнем това.
В този блог ще видим как да разположим тази нова версия на PostgreSQL с няколко щраквания с помощта на ClusterControl и как да я управляваме. Като предварително условие, моля, инсталирайте версията 1.7.1 на ClusterControl на специален хост или виртуална машина.
Внедряване на PostgreSQL 11
За да извършите нова инсталация от ClusterControl, просто изберете опцията „Разгръщане“ и следвайте инструкциите, които се появяват. Имайте предвид, че ако вече имате работещ екземпляр на PostgreSQL 11, тогава трябва да изберете „Импортиране на съществуващ сървър/база данни“.
 Опция за внедряване на ClusterControl
Опция за внедряване на ClusterControl Когато избираме PostgreSQL, трябва да посочим потребител, ключ или парола и порт за свързване чрез SSH към нашите PostgreSQL хостове. Нуждаем се и от името на нашия нов клъстер и ако искаме ClusterControl да инсталира съответния софтуер и конфигурации вместо нас.
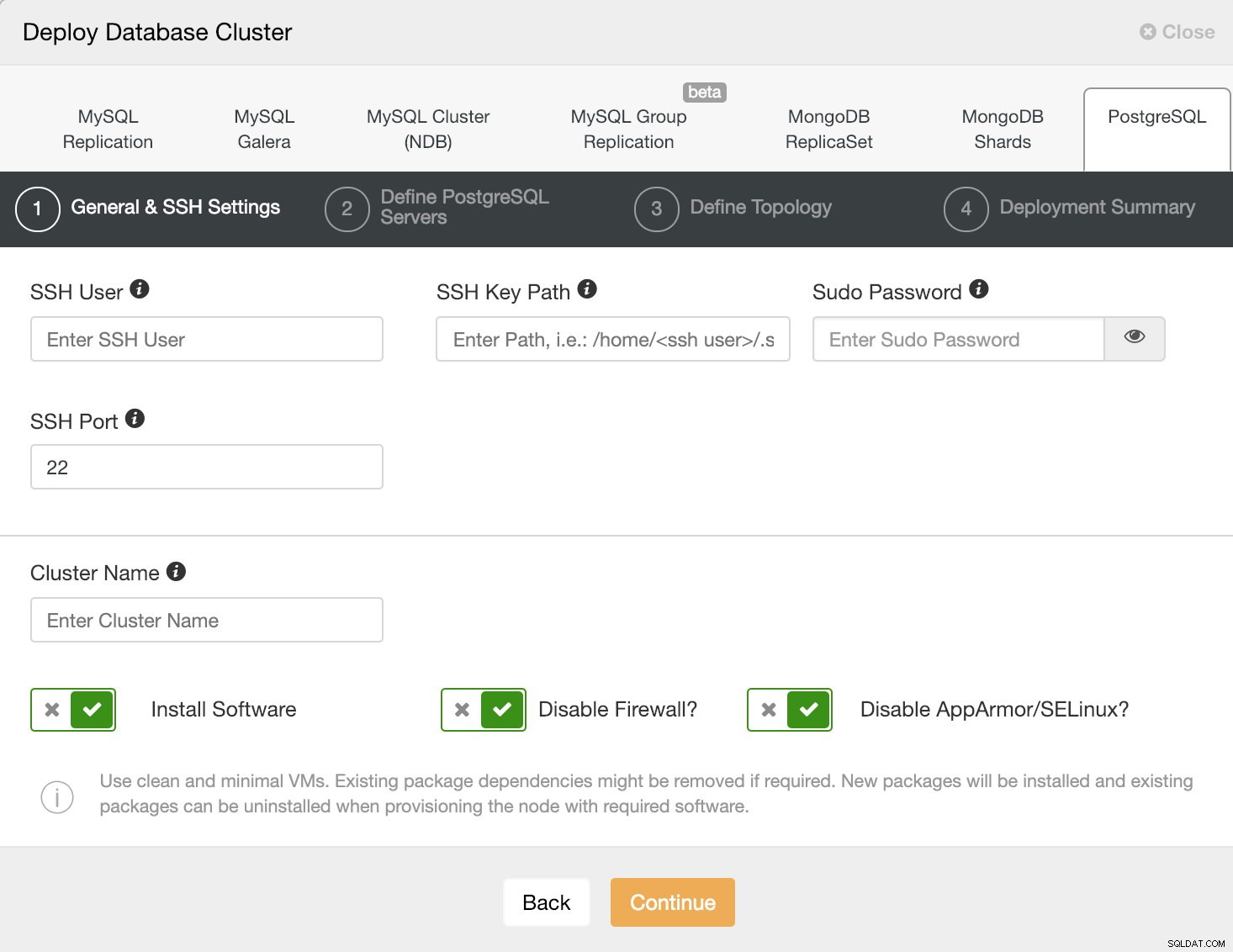 Информация за внедряване на ClusterControl 1
Информация за внедряване на ClusterControl 1 Моля, проверете потребителското изискване на ClusterControl за тази задача тук.
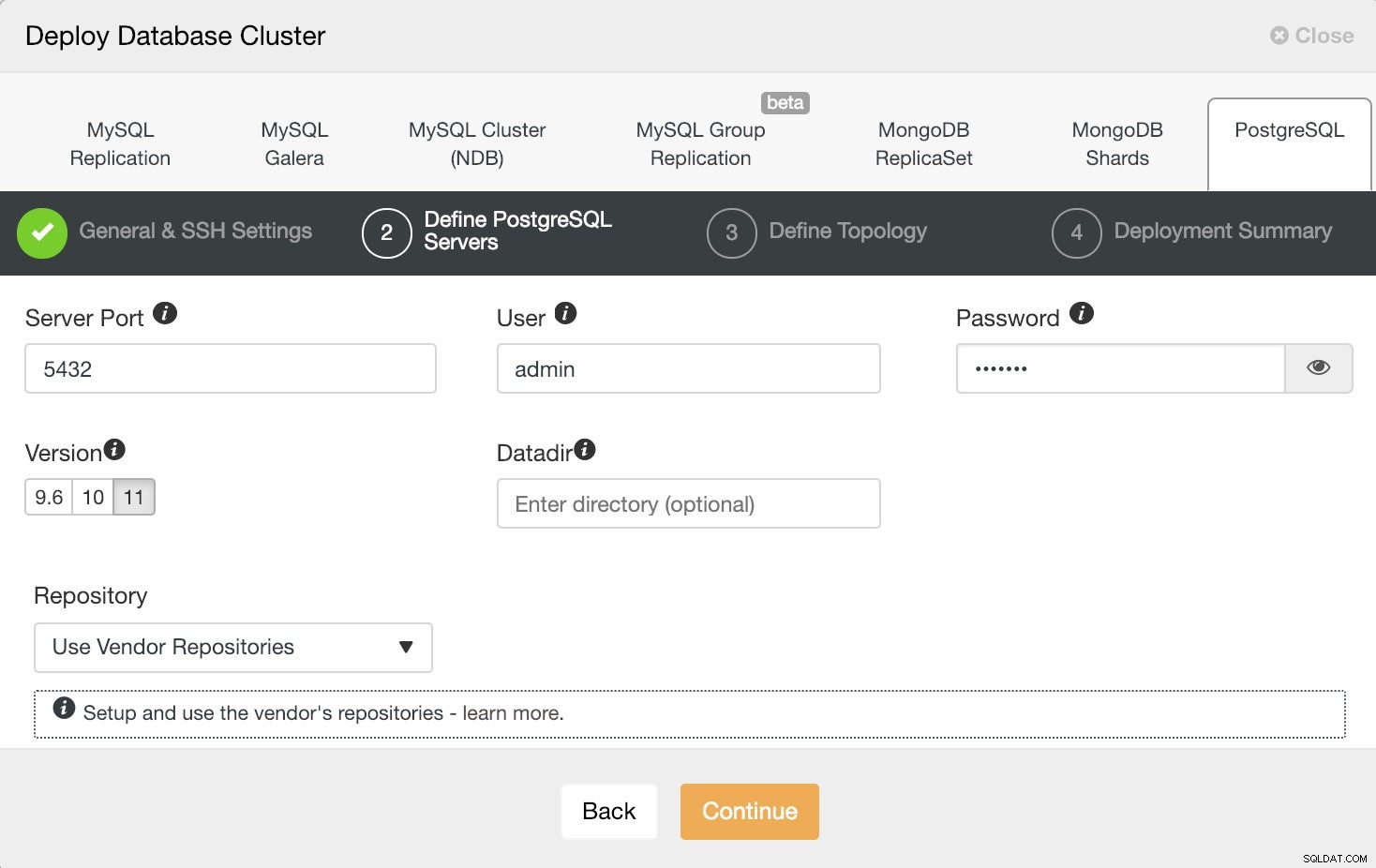 Информация за внедряване на ClusterControl 2
Информация за внедряване на ClusterControl 2 След като настроим информацията за SSH достъп, трябва да дефинираме потребителя на базата данни, версията и datadir (по избор). Можем също да посочим кое хранилище да използваме. В този случай искаме да внедрим PostgreSQL 11, така че просто го изберете и продължете.
В следващата стъпка трябва да добавим нашите сървъри към клъстера, който ще създадем.
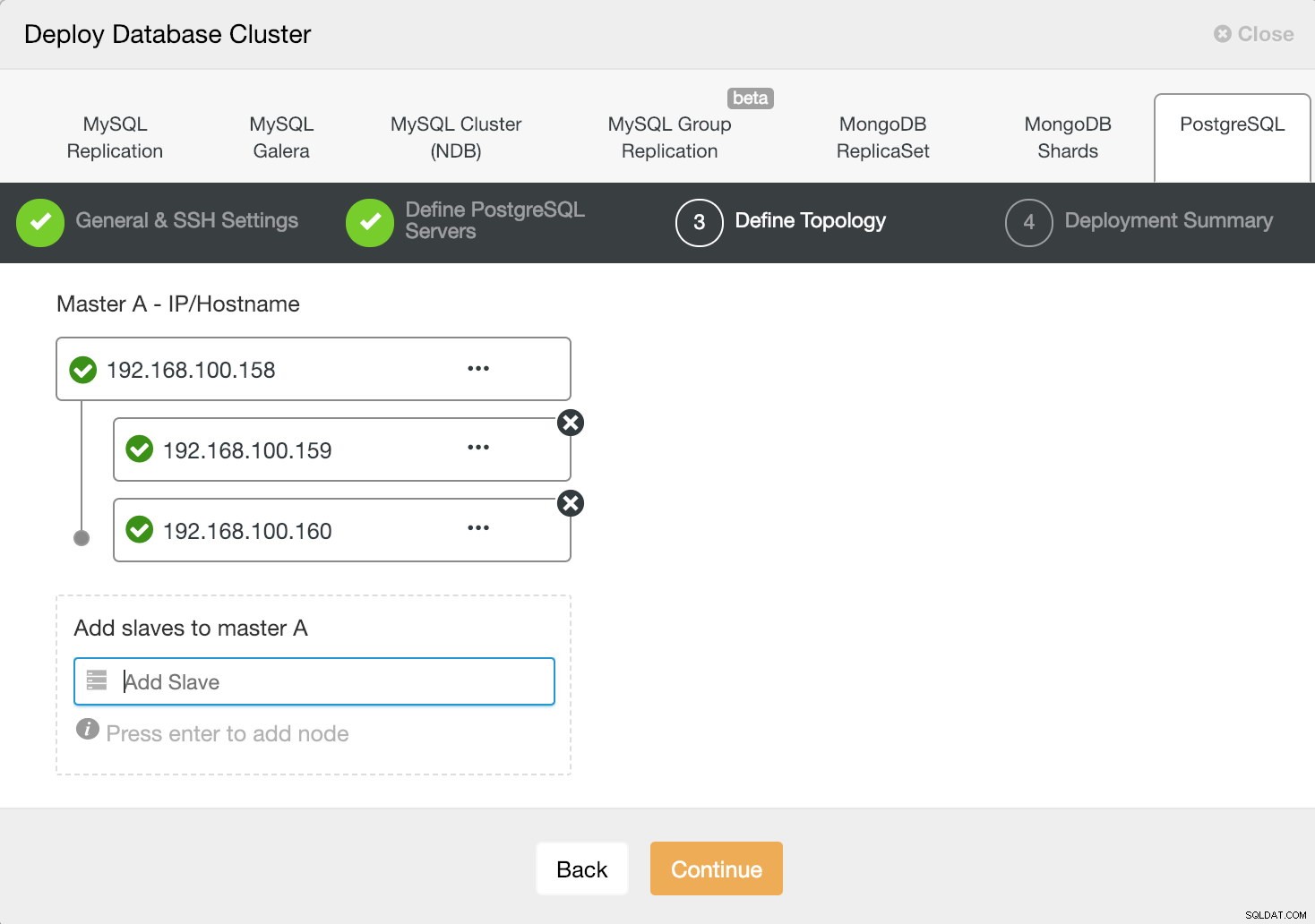 Информация за внедряване на ClusterControl 3
Информация за внедряване на ClusterControl 3 Когато добавяме нашите сървъри, можем да въведем IP или име на хост.
В последната стъпка можем да изберем дали нашата репликация ще бъде синхронна или асинхронна.
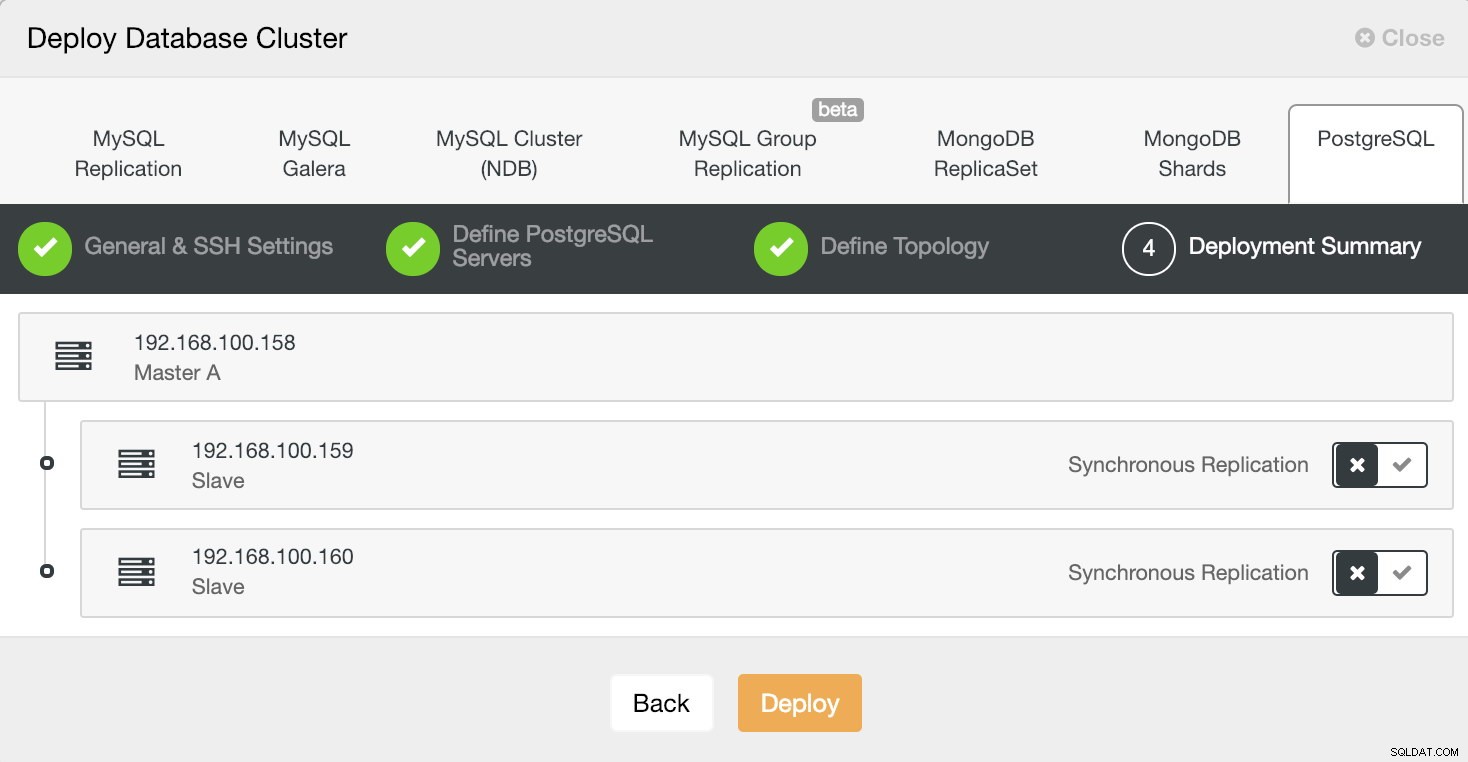 Информация за внедряване на ClusterControl 4
Информация за внедряване на ClusterControl 4 Можем да наблюдаваме състоянието на създаването на нашия нов клъстер от монитора на активността на ClusterControl.
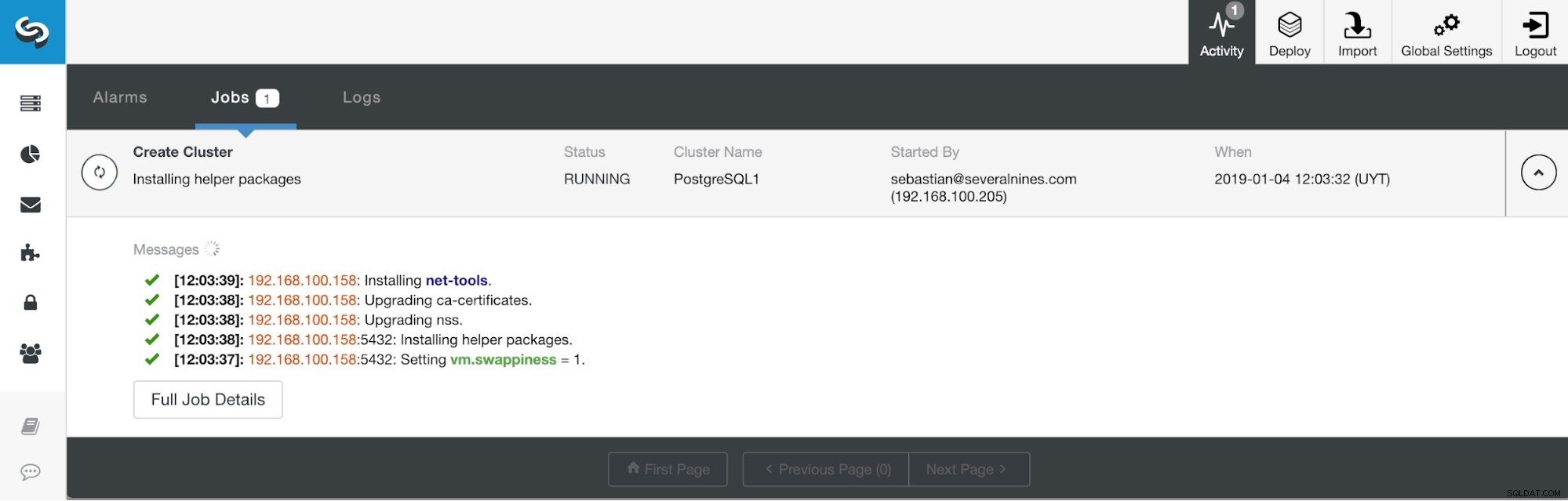 Раздел за активност на ClusterControl
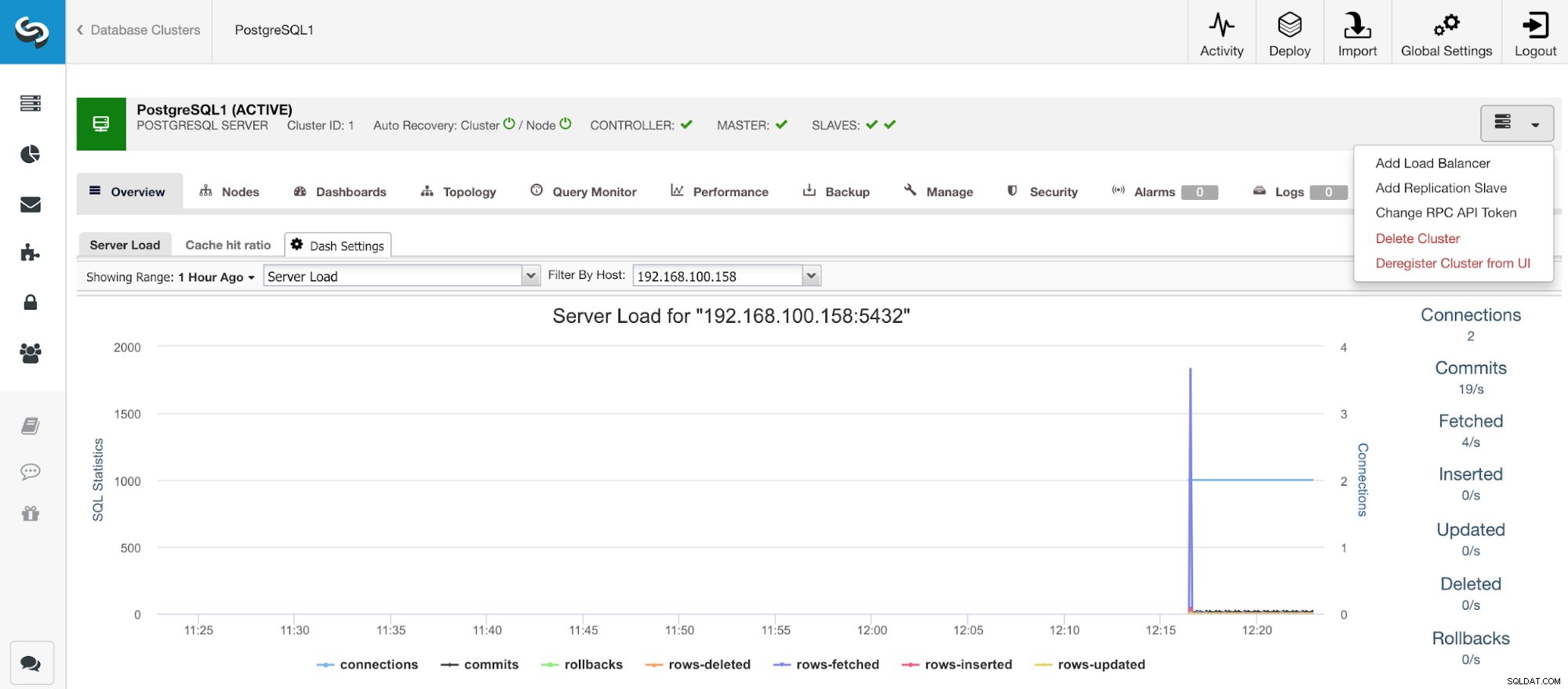
Раздел за активност на ClusterControl След като задачата приключи, можем да видим нашия нов PostgreSQL 11 клъстер в главния екран на ClusterControl.
 Главен екран на ClusterControl
Главен екран на ClusterControl След като създадем нашия клъстер, можем да изпълним няколко задачи върху него, като добавяне на балансьор на натоварване (HAProxy) или нова реплика.
 ClusterControl Cluster Section
ClusterControl Cluster Section Мащабиране на PostgreSQL 11
Ако отидем в действията на клъстера и изберем „Добавяне на подчинен за репликация“, можем или да създадем нова реплика от нулата, или да добавим съществуваща PostgreSQL база данни като реплика.
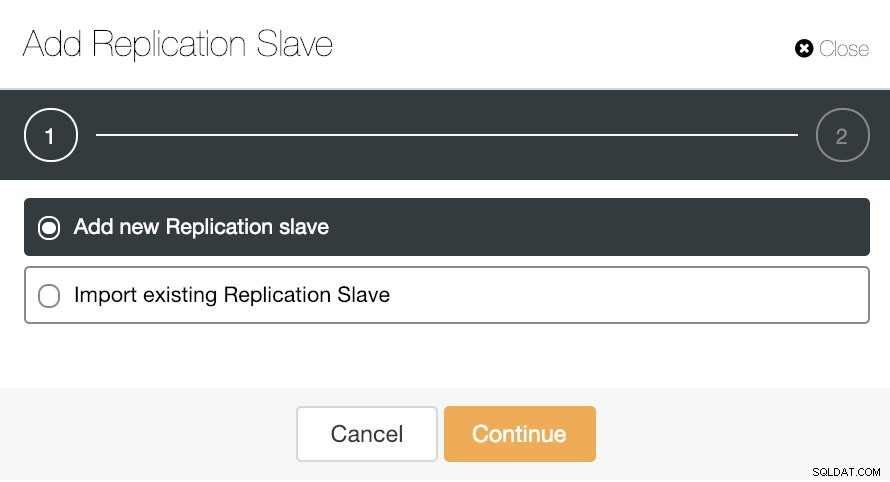 ClusterControl Добавяне на опция за подчинена репликация
ClusterControl Добавяне на опция за подчинена репликация Нека видим как добавянето на нов подчинен репликация може да бъде наистина лесна задача.
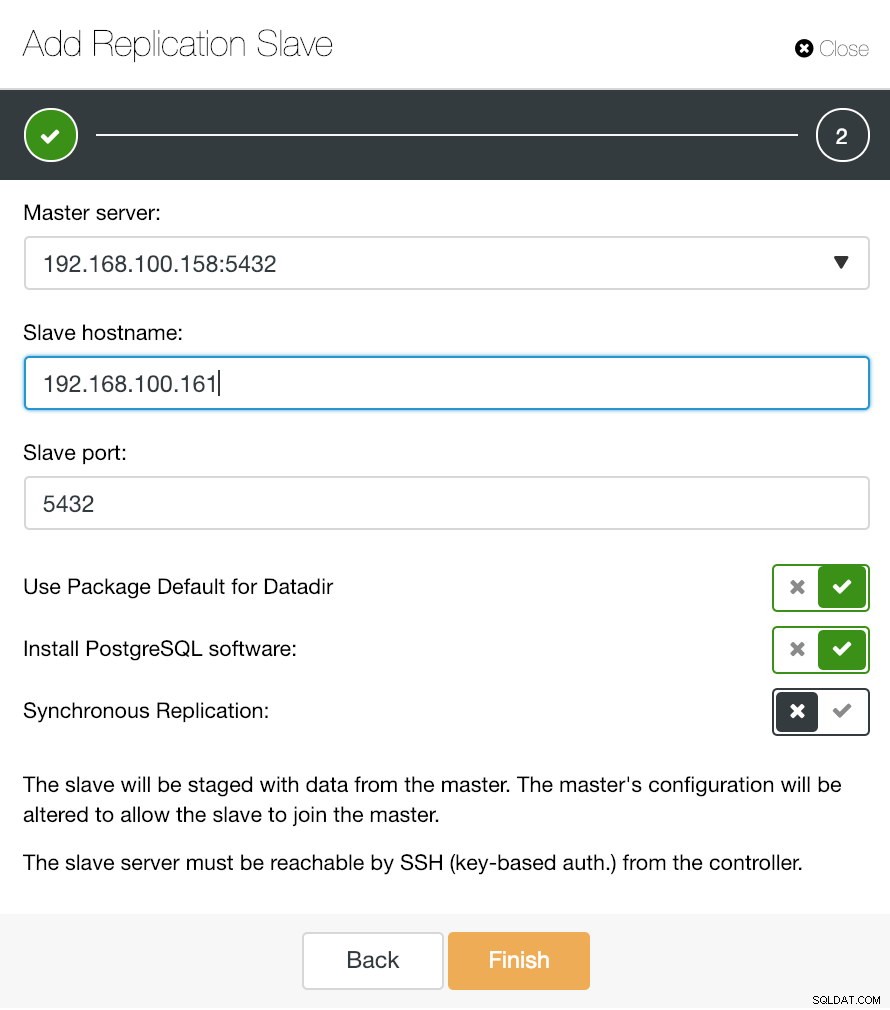 ClusterControl Добавяне на подчинена информация за репликация
ClusterControl Добавяне на подчинена информация за репликация Както можете да видите на изображението, трябва само да изберем нашия главен сървър, да въведете IP адреса за нашия нов подчинен сървър и порта на базата данни. След това можем да изберем дали искаме ClusterControl да инсталира софтуера вместо нас и дали подчинението за репликация да бъде синхронно или асинхронно.
По този начин можем да добавим толкова копия, колкото искаме, и да разпределим трафика за четене между тях с помощта на балансьор на натоварване, който също можем да приложим с ClusterControl.
Можем да видим повече информация за HA за PostgreSQL в свързан блог.
От ClusterControl можете също да изпълнявате различни задачи за управление, като рестартиране на хост, повторно изграждане на подчинено устройство за репликация или популяризиране на подчинено с едно щракване.
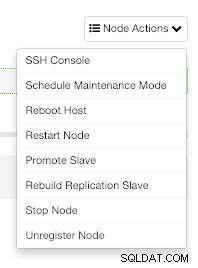 Действия на възел ClusterControl
Действия на възел ClusterControl Резервни копия
В предишни блогове разгледахме функциите за архивиране и PITR ClusterControl за PostgreSQL. Сега, в последната версия на ClusterControl, имаме функциите „проверка/възстановяване на резервно копие на самостоятелен хост“ и „създаване на клъстер от съществуващ архив“.
В ClusterControl изберете своя клъстер и отидете в секцията „Резервно копие“, за да видите текущите си архиви.
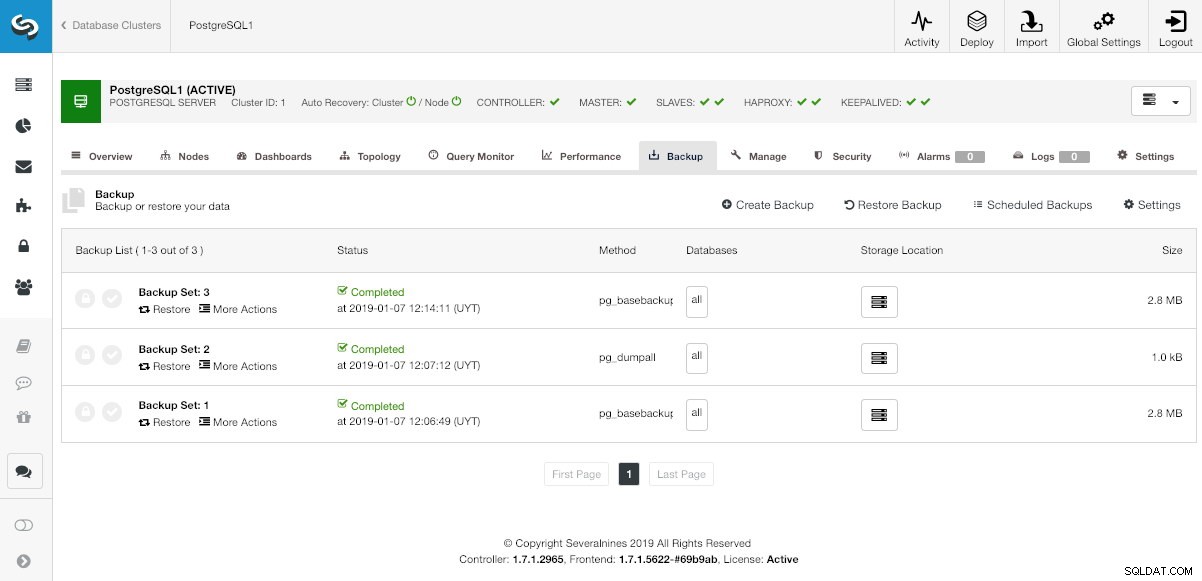 Раздел за архивиране на ClusterControl
Раздел за архивиране на ClusterControl В опцията „Възстановяване“ първо можете да изберете кое резервно копие ще бъде възстановено.
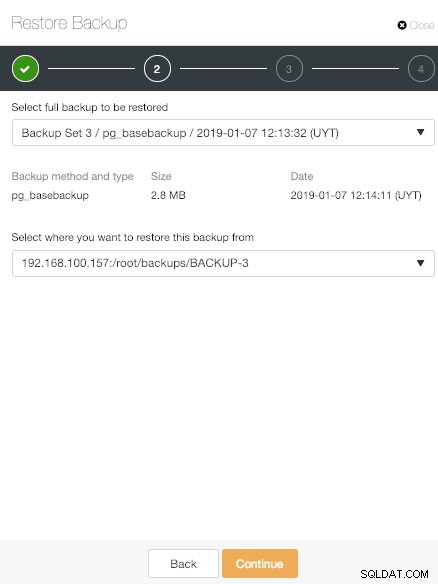 Опция за възстановяване на ClusterControl
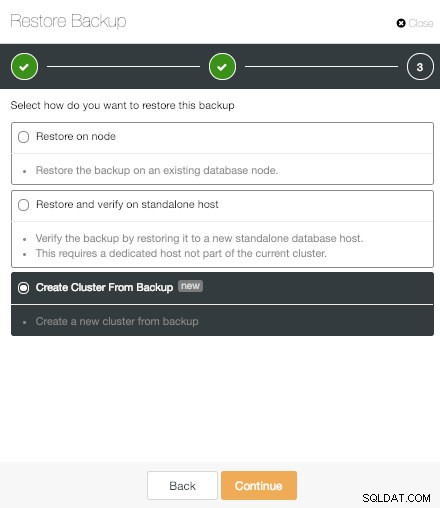
Опция за възстановяване на ClusterControl Имаме три опции.
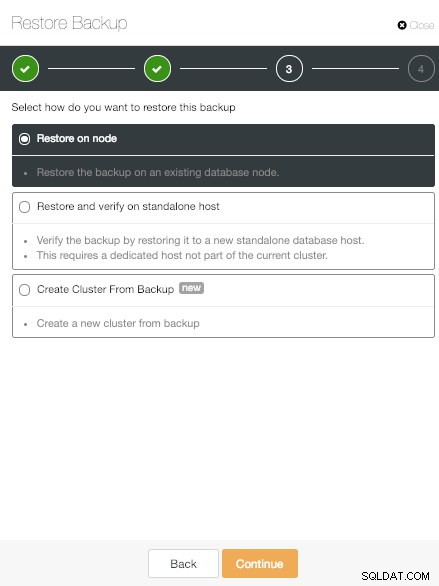 Опция за възстановяване на ClusterControl на възел
Опция за възстановяване на ClusterControl на възел Първата е класическата опция "Възстановяване на възел". Това просто възстановява избраното архивно копие на конкретен възел.
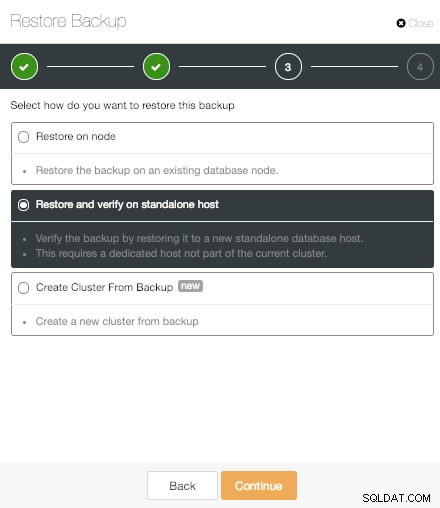 ClusterControl Възстановяване и проверка на опция за самостоятелен хост
ClusterControl Възстановяване и проверка на опция за самостоятелен хост Опцията „Възстановяване и проверка на самостоятелен хост“ е нова функция на ClusterControl PostgreSQL. Това ни позволява да тестваме генерирания архив, като го възстановим на самостоятелен хост. Това е наистина полезно, за да избегнете изненади при сценарий за възстановяване при бедствие.
За да използваме тази функция, се нуждаем от специален хост (или VM), който не е част от клъстера.
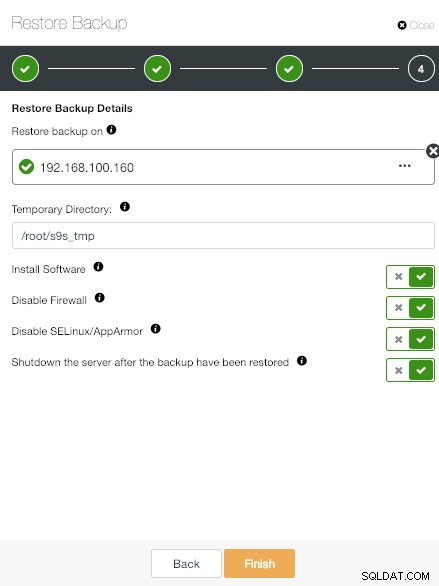 ClusterControl Възстановяване и проверка на информация за самостоятелен хост
ClusterControl Възстановяване и проверка на информация за самостоятелен хост Добавете специалния IP адрес на хоста и изберете желаните опции.
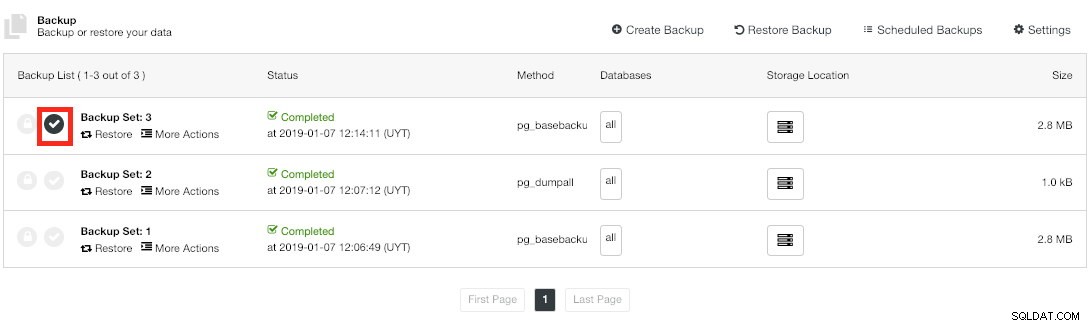 Проверено архивиране с ClusterControl
Проверено архивиране с ClusterControl Когато резервното копие бъде потвърдено, можете да видите иконата „Проверено“ в списъка с архиви.
 ClusterControl Създаване на клъстер от опция за архивиране
ClusterControl Създаване на клъстер от опция за архивиране „Създаване на клъстер от архивиране“ е друга важна нова функция на ClusterControl PostgreSQL.
Както подсказва името, тази функция ни позволява да създадем нов PostgreSQL клъстер с данните от генерирания архив.
След като изберем тази опция, трябва да изпълним същите стъпки, които видяхме в секцията за разполагане.
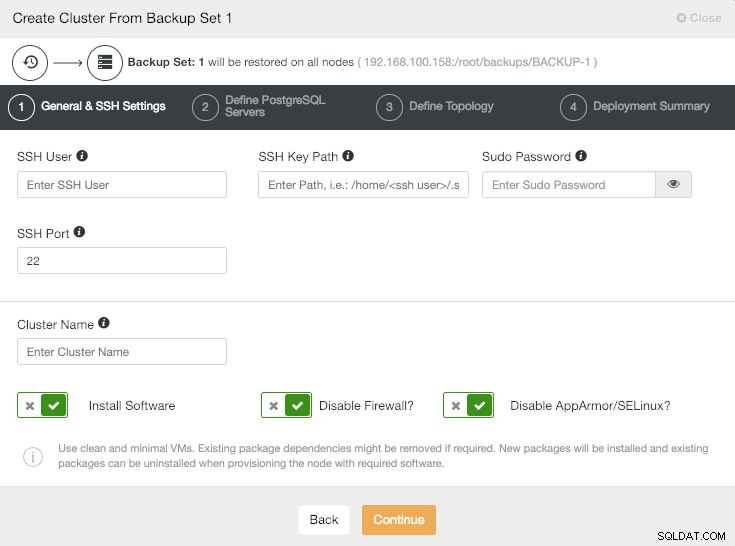 ClusterControl Създаване на клъстер от информация за архивиране
ClusterControl Създаване на клъстер от информация за архивиране
Цялата конфигурация като потребител, брой възли или тип репликация може да бъде различна в този нов клъстер.
Когато новият клъстер е създаден, можете да видите и стария, и новия в главния екран на ClusterControl.
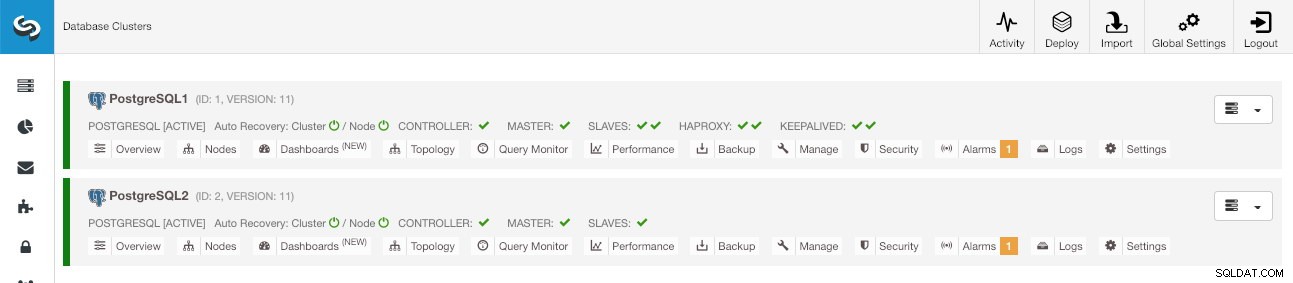 Главен екран на ClusterControl
Главен екран на ClusterControl Заключение
Както видяхме по-горе, вече можете да внедрите най-новата версия на PostgreSQL, версия 11, като използвате ClusterControl. Веднъж разгърнат, ClusterControl предоставя цял набор от функции, от наблюдение, предупреждение, автоматично преминаване при отказ, архивиране, възстановяване в момента, проверка на архивиране до мащабиране на прочетени реплики. Това може да ви помогне да управлявате Postgres по приятелски и интуитивен начин. Опитайте!