Това е онзи вторник от месеца – знаете, този, когато се случва блоковото парти на блогъри, известно като T-SQL вторник. Този месец домакинът е Ръс Томас (@SQLJudo), а темата е „Обаждане на всички тунери и глави на съоръжения“. Тук ще разгледам проблем, свързан с производителността, въпреки че се извинявам, че може да не е напълно в съответствие с насоките, изложени от Ръс в поканата си (няма да използвам намеци, флагове за проследяване или ръководства за планове) .
Миналата седмица на SQLBits направих презентация за тригерите и моят добър приятел и колега MVP Ерланд Сомарско случайно присъства. В един момент предложих, преди да създадете нов тригер в таблица, трябва да проверите дали вече съществуват тригери и да помислите за комбиниране на логиката, вместо да добавяте допълнителен тригер. Моите причини бяха предимно за поддръжка на кода, но също и за производителност. Ерланд попита дали някога съм тествал, за да видя дали има някакви допълнителни разходи при задействането на множество тригери за едно и също действие и трябваше да призная, че не, не съм правил нищо обширно. Така че ще го направя сега.
В AdventureWorks2014 създадох прост набор от таблици, които основно представляват sys.all_objects (~2700 реда) и sys.all_columns (~9 500 реда). Исках да измеря ефекта върху натоварването на различни подходи за актуализиране на двете таблици – по същество имате потребители, които актуализират таблицата с колони, и използвате тригер за актуализиране на различна колона в същата таблица и няколко колони в таблицата с обекти.
- T1:Изходно ниво :Да приемем, че можете да контролирате целия достъп до данни чрез съхранена процедура; в този случай актуализациите на двете таблици могат да бъдат извършени директно, без нужда от тригери. (Това не е практично в реалния свят, защото не можете надеждно да забраните директния достъп до масите.)
- T2:Единичен тригер срещу друга таблица :Да приемем, че можете да контролирате оператора за актуализация спрямо засегнатата таблица и да добавяте други колони, но актуализациите на вторичната таблица трябва да бъдат внедрени с тригер. Ще актуализираме и трите колони с едно изявление.
- T3:Единичен тригер срещу двете таблици :В този случай имаме тригер с два израза, единият, който актуализира другата колона в засегнатата таблица, и един, който актуализира всичките три колони във вторичната таблица.
- T4:Единичен тригер срещу двете таблици :Подобно на T3, но този път имаме тригер с четири израза, един, който актуализира другата колона в засегнатата таблица, и оператор за всяка колона, актуализирана във вторичната таблица. Това може да е начинът, по който се работи, ако изискванията се добавят с течение на времето и отделно изявление се счита за по-безопасно по отношение на регресионното тестване.
- T5:Две задействания :Един тригер актуализира само засегнатата таблица; другият използва един израз за актуализиране на трите колони във вторичната таблица. Това може да е начинът, по който се прави, ако другите тригери не са забелязани или ако промяната им е забранена.
- T6:Четири задействания :Един тригер актуализира само засегнатата таблица; останалите три актуализират всяка колона във вторичната таблица. Отново, това може да е начинът, по който се прави, ако не знаете, че другите задействания съществуват, или ако се страхувате да докоснете другите тригери поради опасения за регресия.
Ето изходните данни, с които работим:
-- sys.all_objects: SELECT * INTO dbo.src FROM sys.all_objects; CREATE UNIQUE CLUSTERED INDEX x ON dbo.src([object_id]); GO -- sys.all_columns: SELECT * INTO dbo.tr1 FROM sys.all_columns; CREATE UNIQUE CLUSTERED INDEX x ON dbo.tr1([object_id], column_id); -- repeat 5 times: tr2, tr3, tr4, tr5, tr6
Сега, за всеки от 6-те теста, ще стартираме нашите актуализации 1000 пъти и ще измерим продължителността на времето
T1:Изходно ниво
Това е сценарият, при който имаме късмета да избегнем тригери (отново не много реалистично). В този случай ние ще измерваме показанията и продължителността на тази партида. Сложих /*real*/ в текста на заявката, така че да мога лесно да изтегля статистическите данни само за тези изрази, а не за каквито и да е изявления от тригерите, тъй като в крайна сметка метриките се събират до операторите, които извикват тригерите. Също така имайте предвид, че действителните актуализации, които правя, всъщност нямат никакъв смисъл, така че игнорирайте, че задавам съпоставянето на името на сървъра/екземпляра и principal_id на обекта към session_id на текущата сесия .
UPDATE /*real*/ dbo.tr1 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; UPDATE /*real*/ s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID FROM dbo.src AS s INNER JOIN dbo.tr1 AS t ON s.[object_id] = t.[object_id] WHERE t.name LIKE '%s%'; GO 1000
T2:Единичен тригер
За това се нуждаем от следния прост тригер, който актуализира само dbo.src :
CREATE TRIGGER dbo.tr_tr2
ON dbo.tr2
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = SUSER_ID()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Тогава нашата партида трябва само да актуализира двете колони в основната таблица:
UPDATE /*real*/ dbo.tr2 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; GO 1000
T3:Единичен тригер срещу двете таблици
За този тест нашият тригер изглежда така:
CREATE TRIGGER dbo.tr_tr3
ON dbo.tr3
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr3 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO И сега партидата, която тестваме, просто трябва да актуализира оригиналната колона в първичната таблица; другият се управлява от тригера:
UPDATE /*real*/ dbo.tr3 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T4:Единичен тригер срещу двете таблици
Това е точно като T3, но сега тригерът има четири израза:
CREATE TRIGGER dbo.tr_tr4
ON dbo.tr4
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr4 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Тестовата партида е непроменена:
UPDATE /*real*/ dbo.tr4 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T5:Две задействания
Тук имаме едно задействане за актуализиране на първичната таблица и едно задействане за актуализиране на вторичната таблица:
CREATE TRIGGER dbo.tr_tr5_1
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr5 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr5_2
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Тестовата партида отново е много проста:
UPDATE /*real*/ dbo.tr5 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T6:Четири задействания
Този път имаме тригер за всяка колона, която е засегната; една в основната таблица и три във вторичната таблица.
CREATE TRIGGER dbo.tr_tr6_1
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr6 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_2
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_3
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_4
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO И тестовата партида:
UPDATE /*real*/ dbo.tr6 SET name += N'' WHERE name LIKE '%s%'; GO 1000
Измерване на въздействието върху работното натоварване
Накрая написах проста заявка срещу sys.dm_exec_query_stats за измерване на показанията и продължителността за всеки тест:
SELECT [cmd] = SUBSTRING(t.text, CHARINDEX(N'U', t.text), 23), avg_elapsed_time = total_elapsed_time / execution_count * 1.0, total_logical_reads FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.text LIKE N'%UPDATE /*real*/%' ORDER BY cmd;
Резултати
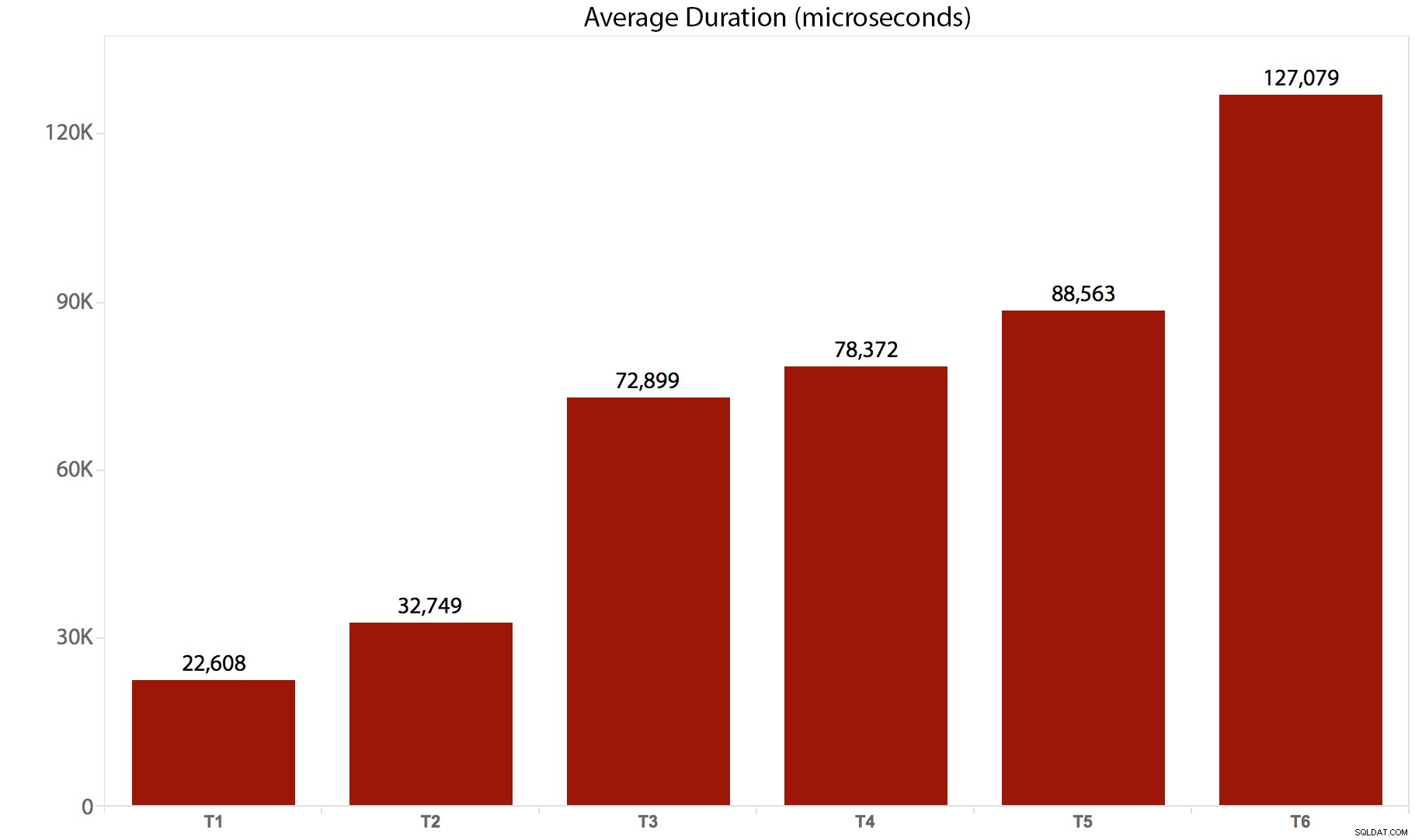
Проведох тестовете 10 пъти, събрах резултатите и усредних всичко. Ето как се развали:
| Тест/Пакет | Средна продължителност (микросекунди) | Общо четене (8K страници) |
|---|---|---|
| T1 :АКТУАЛИЗИРАНЕ /*реално*/ dbo.tr1 … | 22 608 | 205 134 |
| T2 :АКТУАЛИЗИРАНЕ /*реално*/ dbo.tr2 … | 32 749 | 11 331 628 |
| T3 :АКТУАЛИЗИРАНЕ /*реално*/ dbo.tr3 … | 72 899 | 22 838 308 |
| T4 :АКТУАЛИЗИРАНЕ /*реално*/ dbo.tr4 … | 78 372 | 44 463 275 |
| T5 :АКТУАЛИЗИРАНЕ /*реално*/ dbo.tr5 … | 88 563 | 41 514 778 |
| T6 :АКТУАЛИЗИРАНЕ /*реално*/ dbo.tr6 … | 127 079 | 100 330 753 |
А ето и графично представяне на продължителността:
Заключение
Ясно е, че в този случай има значителни допълнителни разходи за всеки тригер, който се извиква – всички тези партиди в крайна сметка засегнаха същия брой редове, но в някои случаи същите редове бяха докосвани многократно. Вероятно ще извърша последващо тестване, за да измеря разликата, когато един и същ ред никога не се докосва повече от веднъж – може би по-сложна схема, където 5 или 10 други таблици трябва да се докосват всеки път и тези различни твърдения могат да бъдат в единичен тригер или в множество. Предполагам, че разликите в режийните разходи ще се движат повече от неща като едновременността и броя на засегнатите редове, отколкото от режийните разходи на самия тригер – но ще видим.
Искате ли сами да изпробвате демото? Изтеглете скрипта тук.