Като отклонение от моята поредица за „настройване на производителност на коляно“, бих искал да обсъдя как фрагментацията на индекса може да ви пълзи при определени обстоятелства.
Какво е фрагментация на индекса?
Повечето хора смятат, че „фрагментацията на индекса“ означава проблема, при който страниците на индекса не са в ред – листната страница на индекса със следващата ключова стойност не е тази, която е физически съседна във файла с данни до страницата на индекса, която се изследва в момента . Това се нарича логическа фрагментация (и някои хора го наричат външна фрагментация – объркващ термин, който не ми харесва).
Логическата фрагментация се случва, когато страница с индексен лист е пълна и върху нея се изисква място или за вмъкване, или за удължаване на съществуващ запис (от актуализиране на колона с променлива дължина). В този случай Storage Engine създава нова, празна страница и премества 50% от редовете (обикновено, но не винаги) от цялата страница към новата страница. Тази операция създава пространство и в двете страници, което позволява вмъкването или актуализирането да продължи и се нарича разделяне на страница. Има интересни патологични случаи, включващи повтарящи се разделяния на страници от една операция и разделяния на страници, които каскадират нагоре по нивата на индекса, но те са извън обхвата на тази публикация.
Когато възникне разделяне на страницата, това обикновено причинява логическа фрагментация, тъй като е малко вероятно новата страница, която е разпределена, да бъде физически съседна на тази, която се разделя. Когато индексът има много логическа фрагментация, сканирането на индекса се забавя, тъй като физическите четения на необходимите страници не могат да бъдат извършени толкова ефективно (използвайки многостранични „readahead“ четения), когато листовите страници не се съхраняват в ред във файла с данни .
Това е основната дефиниция за фрагментация на индекса, но има втори вид фрагментация на индекса, който повечето хора не разглеждат:ниска плътност на страниците (понякога наричаме вътрешна фрагментация отново, объркващ термин, който не харесвам).
Плътността на страниците е мярка за това колко данни се съхраняват на страница с индексен лист. Когато се случи разделяне на страница с обичайния случай 50/50, всяка листова страница (разделящата се и новата) остава с плътност на страницата от само 50%. Колкото по-ниска е плътността на страниците, толкова повече празно място има в индекса и следователно, толкова повече дисково пространство и памет на буферния пул можете да смятате за загубени. Преди няколко години писах в блог за този проблем и можете да прочетете за него тук.
След като дадох основна дефиниция на двата вида фрагментация на индекса, ще ги наричам заедно просто „фрагментация“.
До края на тази публикация бих искал да обсъдя три случая, при които клъстерираните индекси могат да бъдат фрагментирани, дори ако избягвате операции, които очевидно биха причинили фрагментация (т.е. произволните вмъквания и актуализирането на записи да бъдат по-дълги).
Фрагментиране от изтривания
„Как може едно изтриване от клъстерирана индексна страница да причини разделяне на страницата?“ може би питаш. При нормални обстоятелства няма да стане (и седях и мислех за това няколко минути, за да се уверя, че няма някакъв странен патологичен случай! Но вижте раздела по-долу...) Въпреки това, изтриванията могат да доведат до постепенно намаляване на плътността на страниците.
Представете си случая, в който клъстерираният индекс има голяма стойност на ключа за идентичност, така че вмъкванията винаги ще отиват от дясната страна на индекса и никога, никога няма да бъдат вмъкнати в по-ранна част от индекса (освен някой да заеме повторно стойността на идентичността – потенциално много проблематично!). Сега си представете, че работното натоварване изтрива записи от таблицата, които вече не са необходими, след което задачата за почистване на фонов призрак ще възстанови мястото на страницата и то ще стане свободно място.
При липса на произволни вмъквания (невъзможно в нашия сценарий, освен ако някой не зададе повторно самоличността или не посочи ключова стойност, която да се използва след активиране на SET IDENTITY INSERT за таблицата), никакви нови записи никога няма да използват пространството, което е било освободено от изтритите записи. Това означава, че средната плътност на страниците на по-ранните части от клъстерирания индекс постоянно ще намалява, което ще доведе до увеличаване на количеството загубено дисково пространство и памет на буферния пул, както описах по-рано.
Изтриванията могат да причинят фрагментиране, стига да считате плътността на страниците като част от „фрагментацията“.
Фрагментация от изолиране на моментна снимка
SQL Server 2005 въведе две нови нива на изолация:изолация на моментни снимки и изолация на моментни снимки, ангажирани за четене. Тези две имат малко по-различна семантика, но основно позволяват на заявките да видят изглед в даден момент на база данни и за избори без сблъсък на заключване. Това е голямо опростяване, но е достатъчно за моите цели.
За да улесни тези нива на изолация, екипът за разработка на Microsoft, който ръководех, внедри механизъм, наречен управление на версии. Начинът, по който работи управлението на версиите, е, че всеки път, когато даден запис се промени, версията за предварителна промяна на записа се копира в хранилището на версиите в tempdb, а промененият записан получава 14-байтов етикет за версия, добавен в края на него. Тагът съдържа указател към предишната версия на записа, плюс времева марка, която може да се използва, за да се определи коя е правилната версия на запис за четене на конкретна заявка. Отново силно опростено, но се интересуваме само от добавянето на 14-байта.
Така че всеки път, когато запис се промени, когато е в сила някое от тези нива на изолация, той може да се разшири с 14 байта, ако вече няма маркер за версия за записа. Ами ако няма достатъчно място за допълнителните 14 байта на страницата на индексния лист? Точно така, ще се получи разделяне на страницата, което ще доведе до фрагментация.
Голяма работа, може да си помислите, тъй като записът така или иначе се променя, така че ако все пак променяше размера, вероятно щеше да се получи разделяне на страницата. Не – тази логика е валидна само ако промяната на записа е увеличила размера на колона с променлива дължина. Ще бъде добавен маркер за версия, дори ако колона с фиксирана дължина е актуализирана!
Точно така – когато се изпълнява версията, актуализациите на колони с фиксирана дължина могат да доведат до разширяване на записа, което потенциално причинява разделяне и фрагментация на страницата. Още по-интересното е, че изтриването ще добави и 14-байтов маркер, така че изтриването в клъстериран индекс може да причини разделяне на страницата, когато се използва версията!
Изводът тук е, че разрешаването на която и да е форма на изолиране на моментни снимки може да доведе до внезапно започване на фрагментиране в клъстерирани индекси, където преди не е имало възможност за фрагментиране.
Фрагментация от четими вторични елементи
Последният случай, който искам да обсъдя, е използването на четими вторични елементи, част от функцията за група за наличност, добавена в SQL Server 2012.
Когато активирате четим вторичен, всички заявки, които правите към вторичната реплика, се преобразуват в използване на изолация на моментни снимки под кориците. Това не позволява на заявките да блокират постоянното възпроизвеждане на регистрационни записи от първичната реплика, тъй като кодът за възстановяване придобива ключалки, докато върви.
За да направите това, трябва да има 14-байтови етикети за версия на записи на вторичната реплика. Има проблем, защото всички реплики трябва да са идентични, така че възпроизвеждането на журнала да работи. Е, не съвсем. Съдържанието на маркера за версия не е уместно, тъй като се използва само в екземпляра, който ги е създал. Но вторичната реплика не може да добавя етикети за версия, което прави записите по-дълги, тъй като това би променило физическото оформление на записите на страница и би нарушило повторното възпроизвеждане на дневника. Ако маркерите за версия вече бяха там, той можеше да използва пространството, без да нарушава нищо.
Така че точно това се случва. Системата за съхранение гарантира, че всички необходими тагове за версии за вторичната реплика вече са там, като ги добавя към основната реплика!
Веднага след като бъде създадена четлива вторична реплика на база данни, всяка актуализация на запис в първичната реплика кара записът да има добавен празен 14-байтов маркер, така че 14-байтовете да се отчитат правилно във всички регистрационни записи . Тагът не се използва за нищо (освен ако изолирането на моментна снимка не е активирано на самата основна реплика), но фактът, че е създаден, кара записът да се разшири и ако страницата вече е пълна, тогава...
Да, разрешаването на четим вторичен предизвиква същия ефект върху първичната реплика, както ако сте активирали изолирането на моментна снимка за нея – фрагментация.
Резюме
Не мислете, че тъй като избягвате да използвате GUID като ключове за клъстери и избягвате да актуализирате колони с променлива дължина във вашите таблици, тогава вашите клъстерирани индекси ще бъдат имунизирани срещу фрагментация. Както описах по-горе, има други фактори на натоварването и околната среда, които могат да причинят проблеми с фрагментацията във вашите клъстерирани индекси, за които трябва да сте наясно.
Сега не се колебайте и не си мислете, че не трябва да изтривате записи, не трябва да използвате изолация на моментни снимки и не трябва да използвате четими вторични елементи. Просто трябва да сте наясно, че всички те могат да причинят фрагментиране и да знаете как да го откриете, премахнете и смекчите.
SQL Sentry има страхотен инструмент, Fragmentation Manager, който можете да използвате като добавка към Performance Advisor, за да разберете къде са проблемите с фрагментацията и след това да ги разрешите. Може да се изненадате от фрагментацията, която откривате, когато проверявате! Като бърз пример, тук мога да видя визуално – до нивото на отделния дял – колко фрагментация съществува, колко бързо е станала по този начин, какви са съществуващите модели и действителното въздействие, което оказва върху загубата на памет в системата:
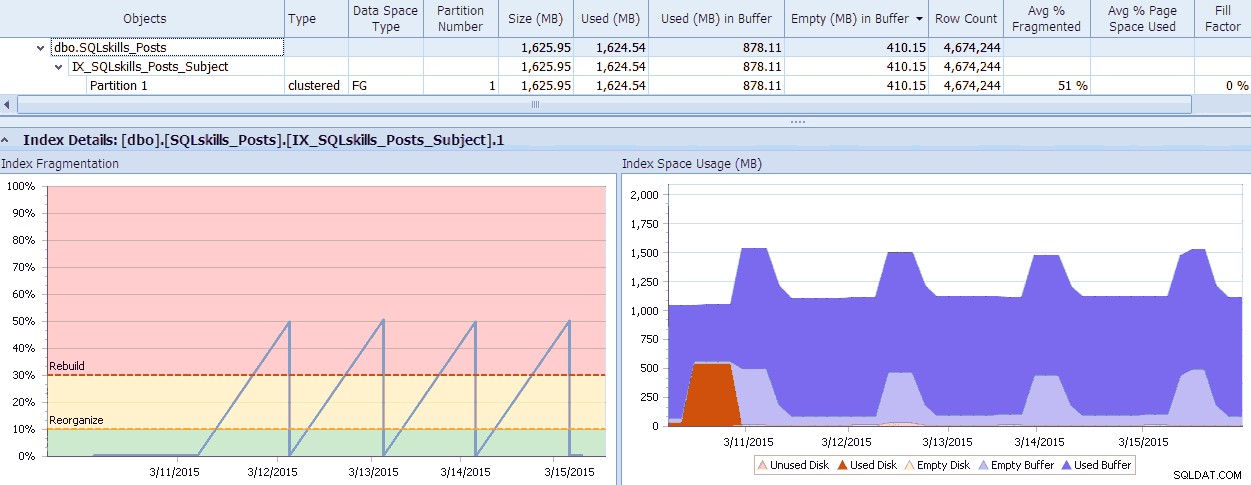 Данни на SQL Sentry Fragmentation Manager (щракнете, за да увеличите)
Данни на SQL Sentry Fragmentation Manager (щракнете, за да увеличите)
В следващата си публикация ще обсъдя повече за фрагментацията и как да я смекча, за да я направя по-малко проблематична.