Тази статия показва как SQL Server комбинира информацията за плътност от множество статистики с една колона, за да произведе оценка на мощността за агрегиране върху множество колони. Да се надяваме, че детайлите са интересни сами по себе си. Те също така дават представа за някои от общите подходи и алгоритми, използвани от оценителя на мощността.
Помислете за следната примерна заявка за база данни на AdventureWorks, която изброява броя на артикулите от инвентара на продукти във всеки кош на всеки рафт в склада:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin;
Приблизителният план за изпълнение показва 1069 реда, които се четат от таблицата, сортирани в Shelf и Bin поръчка, след което се обобщава с помощта на оператор Stream Aggregate:
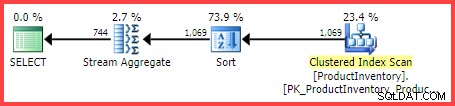
Прогнозен план за изпълнение
Въпросът е как оптимизаторът на заявки на SQL Server стигна до крайната оценка от 744 реда?
Налични статистически данни
Когато компилира заявката по-горе, оптимизаторът на заявки ще създаде статистически данни с една колона в Shelf и Bin колони, ако подходящи статистически данни все още не съществуват. Наред с други неща, тези статистически данни предоставят информация за броя на отделните стойности на колоните (във вектора на плътността):
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Shelf]
)
WITH DENSITY_VECTOR;
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Bin]
)
WITH DENSITY_VECTOR; Резултатите са обобщени в таблицата по-долу (третата колона се изчислява от плътността):
| Колона | Плътност | 1 / Плътност |
|---|---|---|
| Рафт | 0,04761905 | 21 |
| Кошче | 0,01612903 | 62 |
Векторна информация за плътността на рафта и кошчето
Както се отбелязва в документацията, реципрочната стойност на плътността е броят на отделните стойности в колоната. От показаната по-горе статистическа информация SQL Server знае, че е имало 21 различни Shelf стойности и 62 различни Bin стойности в таблицата, когато статистическите данни са били събрани.
Задачата за оценка на броя на редовете, произведени от GROUP BY клаузата е тривиална, когато е включена само една колона (като приемем, че няма други предикати). Например, лесно е да видите, че GROUP BY Shelf ще произведе 21 реда; GROUP BY Bin ще произведе 62.
Въпреки това, не е ясно веднага как SQL Server може да оцени броя на отделните (Shelf, Bin) комбинации за нашия GROUP BY Shelf, Bin запитване. За да поставим въпроса по малко по-различен начин:Като се имат предвид 21 рафта и 62 кошчета, колко уникални комбинации от рафтове и кошчета ще има? Като оставим настрана физическите аспекти и други човешки познания за проблемната област, отговорът може да бъде навсякъде от max(21, 62) =62 до (21 * 62) =1302. Без повече информация няма очевиден начин да разберете къде да поставите оценка в този диапазон.
И все пак, за нашата примерна заявка SQL Server изчислява 744.312 редове (закръглени до 744 в изгледа Plan Explorer), но на каква основа?
Разширено събитие за оценка на мощността
Документираният начин да разгледате процеса на оценка на мощността е да използвате разширеното събитие query_optimizer_estimate_cardinality (въпреки че е в канала за отстраняване на грешки). Докато тече сесия, събираща това събитие, операторите на план за изпълнение получават допълнително свойство StatsCollectionId който свързва оценките на отделните оператори с изчисленията, които ги произвеждат. За нашата примерна заявка идентификаторът за събиране на статистически данни 2 е свързан с оценката за мощността за групата по обобщен оператор.
Съответният изход от разширеното събитие за нашата тестова заявка е:
<data name="calculator">
<type name="xml" package="package0"></type>
<value>
<CalculatorList>
<DistinctCountCalculator CalculatorName="CDVCPlanLeaf" SingleColumnStat="Shelf,Bin" />
</CalculatorList>
</value>
</data>
<data name="stats_collection">
<type name="xml" package="package0"></type>
<value>
<StatsCollection Name="CStCollGroupBy" Id="2" Card="744.31">
<LoadedStats>
<StatsInfo DbId="6" ObjectId="258099960" StatsId="3" />
<StatsInfo DbId="6" ObjectId="258099960" StatsId="4" />
</LoadedStats>
</StatsCollection>
</value>
</data> Със сигурност има полезна информация.
Можем да видим, че класът на калкулатора на различни стойности на листа на плана (CDVCPlanLeaf ) беше използван, като се използва статистика от една колона на Shelf и Bin като входове. Елементът за събиране на статистики съпоставя този фрагмент с идентификатора (2), показан в плана за изпълнение, който показва оценката на кардиналитета от 744,31 , както и повече информация за използваните идентификатори на статистически обекти.
За съжаление, в изхода на събитието няма нищо, което да каже точно как калкулаторът е стигнал до крайната цифра, което е нещото, което наистина ни интересува.
Комбиниране на различни преброявания
При по-малко документиран маршрут можем да поискаме прогнозен план за заявката с флагове за проследяване 2363 и 3604 активиран:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin
OPTION (QUERYTRACEON 3604, QUERYTRACEON 2363); Това връща информация за отстраняване на грешки в раздела Съобщения в SQL Server Management Studio. Интересната част е възпроизведена по-долу:
Begin distinct values computation
Input tree:
LogOp_GbAgg OUT(QCOL: [INV].Shelf,QCOL: [INV].Bin,COL: Expr1001 ,) BY(QCOL: [INV].Shelf,QCOL: [INV].Bin,)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
AncOp_PrjList
AncOp_PrjEl COL: Expr1001
ScaOp_AggFunc stopCountBig
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=0)
Plan for computation:
CDVCPlanLeaf
0 Multi-Column Stats, 2 Single-Column Stats, 0 Guesses
Loaded histogram for column QCOL: [INV].Shelf from stats with id 3
Loaded histogram for column QCOL: [INV].Bin from stats with id 4
Using ambient cardinality 1069 to combine distinct counts:
21
62
Combined distinct count: 744.312
Result of computation: 744.312
Stats collection generated:
CStCollGroupBy(ID=2, CARD=744.312)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
End distinct values computation Това показва почти същата информация като Разширеното събитие в (вероятно) по-лесен за консумация формат:
- Входният релационен оператор за изчисляване на оценка на мощността за (
LogOp_GbAgg– логическа група по съвкупност) - Използваният калкулатор (
CDVCPlanLeaf) и входна статистика - Подробности за събирането на статистически данни в резултат
Интересната нова част от информацията е частта за използването на обкръжаващата мощност за комбиниране на отделни бройки .
Това ясно показва, че стойностите 21, 62 и 1069 са били използвани, но (разочароващо) все още не точно кои изчисления са извършени, за да се достигне до 744.312 резултат.
До инструмента за отстраняване на грешки!
Прикачването на инструмент за отстраняване на грешки и използването на публични символи ни позволява да изследваме подробно пътя на кода, следван при компилирането на примерната заявка.
Снимката по-долу показва горната част на стека от извиквания в представителна точка от процеса:
MSVCR120!log sqllang!OdblNHlogN sqllang!CCardUtilSQL12::ProbSampleWithoutReplacement sqllang!CCardUtilSQL12::CardDistinctMunged sqllang!CCardUtilSQL12::CardDistinctCombined sqllang!CStCollAbstractLeaf::CardDistinctImpl sqllang!IStatsCollection::CardDistinct sqllang!CCardUtilSQL12::CardGroupByHelperCore sqllang!CCardUtilSQL12::PstcollGroupByHelper sqllang!CLogOp_GbAgg::PstcollDeriveCardinality sqllang!CCardFrameworkSQL12::DeriveCardinalityProperties
Тук има няколко интересни подробности. Работейки отдолу нагоре, виждаме, че мощността се извлича с помощта на актуализирания CE (CCardFrameworkSQL12 ) наличен в SQL Server 2014 и по-нова версия (оригиналният CE е CCardFrameworkSQL7 ), за групата чрез обобщен логически оператор (CLogOp_GbAgg ).
Изчисляването на отделната мощност включва комбиниране (разбиране) на множество входни данни, като се използва извадка без замяна.
Препратката към H и (естествен) логаритъм във втория метод отгоре показва използването на ентропията на Шанън при изчислението:
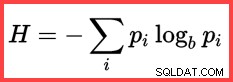
Ентропия на Шанън
Ентропията може да се използва за оценка на информационната корелация (взаимна информация) между две статистики:
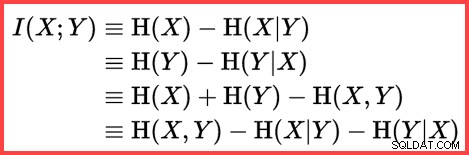
Взаимна информация
Събирайки всичко това заедно, можем да изградим скрипт за изчисление на T-SQL, съответстващ на начина, по който SQL Server използва извадка без замяна, ентропия на Шанън и взаимна информация за да произведете окончателната оценка за кардиналите.
Започваме с входните числа (околна мощност и броя на отделните стойности във всяка колона):
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62; Честотата на всяка колона е средният брой редове на отделна стойност:
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2; Извадката без замяна (SWR) е прост въпрос на изваждане на средния брой редове за отделна стойност (честота) от общия брой редове:
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2; Изчислете ентропиите (N log N) и взаимната информация:
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Using logarithms allows us to express
-- multiplication as addition and division as subtraction
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4); След като изчислихме доколко са свързани двата набора статистически данни, можем да изчислим крайната оценка:
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2;
Резултатът от изчислението е 744,311823994677, което е 744,312 закръглено до три знака след десетичната запетая.
За удобство ето целия код в един блок:
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62;
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2;
-- Sample without replacement
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2;
-- Entropy
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Mutual information
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4);
-- Final estimate
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2; Последни мисли
Окончателната оценка е несъвършена в този случай – примерната заявка всъщност връща 441 редове.
За да получим подобрена оценка, бихме могли да предоставим на оптимизатора по-добра информация за плътността на Bin и Shelf колони, използвайки статистика за няколко колони. Например:
CREATE STATISTICS stat_Shelf_Bin ON Production.ProductInventory (Shelf, Bin);
С тази статистика (или както е дадена, или като страничен ефект от добавянето на подобен многоколонен индекс), оценката за мощността за примерната заявка е точно правилна. Рядко се случва обаче да се изчисли толкова просто агрегиране. С допълнителни предикати статистиката с много колони може да бъде по-малко ефективна. Независимо от това, важно е да запомните, че допълнителната информация за плътност, предоставена от статистически данни с няколко колони, може да бъде полезна за агрегирания (както и сравнения на равенството).
Без статистика за няколко колони, обобщена заявка с допълнителни предикати все още може да използва основната логика, показана в тази статия. Например, вместо да се прилага формулата към мощността на таблицата, тя може да се приложи към входните хистограми стъпка по стъпка.
Свързано съдържание:Оценка на кардиналност за предикат върху израз COUNT