Отдавна е установено, че променливите в таблицата с голям брой редове могат да бъдат проблематични, тъй като оптимизаторът винаги ги вижда като имащи един ред. Без прекомпилиране, след като променливата на таблицата е била попълнена (тъй като преди това е била празна), няма кардиналност за таблицата и автоматичното прекомпилиране не се случва, тъй като променливите на таблицата дори не подлежат на праг за повторно компилиране. Следователно плановете се основават на мощност на таблицата от нула, а не от единица, но минимумът се увеличава до единица, както Пол Уайт (@SQL_Kiwi) описва в този отговор на dba.stackexchange.
Начинът, по който обикновено можем да заобиколим този проблем, е да добавим OPTION (RECOMPILE) към заявката, препращаща променливата в таблицата, принуждавайки оптимизатора да провери мощността на променливата на таблицата, след като е била попълнена. За да се избегне необходимостта да отидете и да промените ръчно всяка заявка, за да добавите изричен намек за прекомпилиране, нов флаг за проследяване (2453) беше въведен в SQL Server 2012 Service Pack 2 и SQL Server 2014 Cumulative Update #3:
- KB #2952444 :КОРЕКЦИЯ:Лоша производителност, когато използвате таблични променливи в SQL Server 2012 или SQL Server 2014
Когато флагът за проследяване 2453 е активен, оптимизаторът може да получи точна картина на мощността на таблицата, след като променливата на таблицата е била създадена. Това може да бъде A Good Thing™ за много заявки, но вероятно не за всички и трябва да сте наясно как работи различно от OPTION (RECOMPILE) . Най-вече, оптимизацията за вграждане на параметър, за която Пол Уайт говори в тази публикация, се случва под OPTION (RECOMPILE) , но не и под този нов флаг за проследяване.
Прост тест
Първоначалният ми тест се състоеше от просто попълване на променлива в таблицата и избор от нея; това доведе до твърде познатия приблизителен брой редове от 1. Ето теста, който проведох (и добавих намек за повторно компилиране за сравнение):
DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, t.name FROM @t AS t; SELECT t.id, t.name FROM @t AS t OPTION (RECOMPILE); DBCC TRACEOFF(2453);
Използвайки SQL Sentry Plan Explorer, можем да видим, че графичният план и за двете заявки в този случай е идентичен, вероятно поне отчасти, защото това е буквално тривиален план:

Графичен план за тривиално сканиране на индекс срещу @t
Оценките обаче не са еднакви. Въпреки че флагът за проследяване е активиран, ние все още получаваме оценка от 1, излизаща от сканирането на индекса, ако не използваме съвета за повторно компилиране:
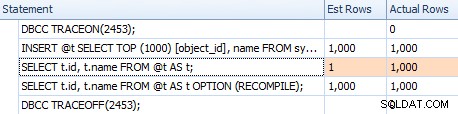
Сравняване на оценки за тривиален план в решетката на изявленията
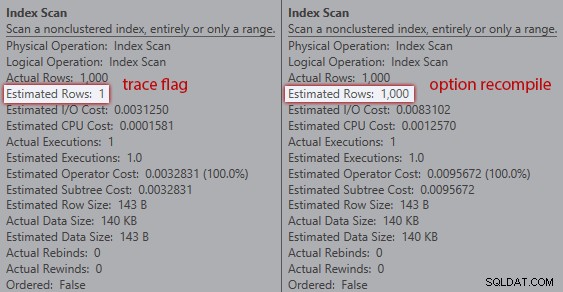
Сравняване на оценки между флаг за проследяване (вляво) и повторно компилиране (вдясно)
Ако някога сте били около мен лично, вероятно можете да си представите лицето, което направих в този момент. Мислех със сигурност, че или в статията на KB е посочен грешен номер на флага за проследяване, или че имам нужда от активирана друга настройка, за да бъде наистина активна.
Бенджамин Неварез (@BenjaminNevarez) бързо ми посочи, че трябва да разгледам по-отблизо статията KB „Бъгове, които са отстранени в SQL Server 2012 Service Pack 2“. Въпреки че са закрили текста зад скрит куршум под Акценти> Релационна машина, статията в списъка с корекции върши малко по-добра работа при описването на поведението на флага за проследяване от оригиналната статия (подчертавам моя):
Ако променлива на таблица се присъедини към други таблици в SQL Server, това може да доведе до бавна производителност поради неефективен избор на план за заявка, тъй като SQL Server не поддържа статистика или проследяване на броя на редовете в променлива на таблица, докато компилира план за заявка.Така че от това описание изглежда, че флагът за проследяване е предназначен само за справяне с проблема, когато променливата на таблицата участва в присъединяване. (Защо това разграничение не е направено в оригиналната статия, нямам представа.) Но също така работи, ако накараме заявките да вършат малко повече работа – горната заявка се счита за тривиална от оптимизатора, а флагът за проследяване не дори не се опитвайте да направите нещо в този случай. Но това ще започне, ако се извърши оптимизация, базирана на разходите, дори без присъединяване; флагът за проследяване просто няма ефект върху тривиалните планове. Ето пример за нетривиален план, който не включва присъединяване:
DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT TOP (100) t.id, t.name FROM @t AS t ORDER BY NEWID(); SELECT TOP (100) t.id, t.name FROM @t AS t ORDER BY NEWID() OPTION (RECOMPILE); DBCC TRACEOFF(2453);
Този план вече не е тривиален; оптимизацията е маркирана като пълна. По-голямата част от разходите се прехвърлят към оператор за сортиране:
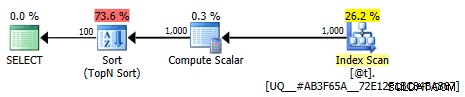
По-малко тривиален графичен план
И оценките се подреждат и за двете заявки (този път ще ви спестя съветите за инструменти, но мога да ви уверя, че са еднакви):

Решетка с изявления за по-малко тривиални планове със и без намек за прекомпилиране
Така че изглежда, че статията в KB не е точно точна – успях да принудя поведението, очаквано от флага за проследяване, без да въвеждам присъединяване. Но искам да го тествам и с присъединяване.
По-добър тест
Нека вземем този прост пример, със и без флага за проследяване:
--DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; --DBCC TRACEOFF(2453);
Без флага за проследяване, оптимизаторът изчислява, че един ред ще дойде от сканирането на индекса спрямо променливата на таблицата. Въпреки това, с активиран флаг за проследяване, той получава 1000 реда:
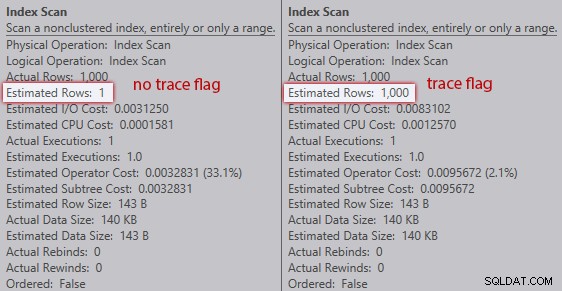
Сравнение на оценките за сканиране на индекса (без флаг за проследяване вляво, флаг за проследяване вдясно)
Разликите не спират дотук. Ако се вгледаме по-отблизо, можем да видим множество различни решения, взети от оптимизатора, всички произтичащи от тези по-добри оценки:
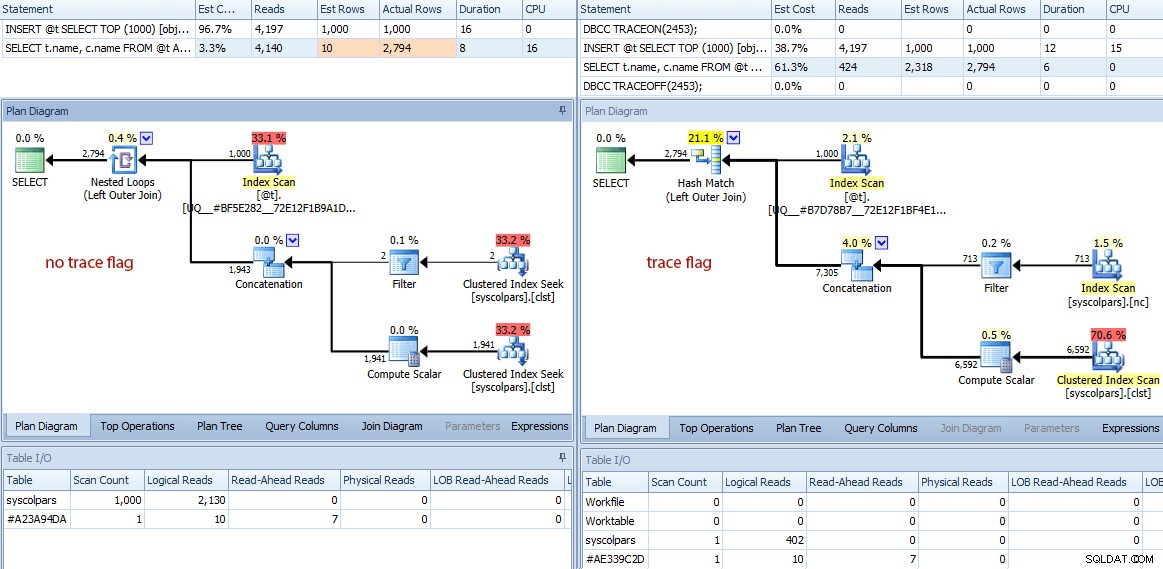
Сравнение на планове (без флаг за проследяване вляво, флаг за проследяване вдясно)
Кратко обобщение на разликите:
- Заявката без флага за проследяване е изпълнила 4140 операции за четене, докато заявката с подобрената оценка е извършила само 424 (приблизително 90% намаление).
- Оптимизаторът изчисли, че цялата заявка ще върне 10 реда без флага за проследяване и много по-точни 2318 реда при използване на флага за проследяване.
- Без флага за проследяване, оптимизаторът избра да извърши присъединяване на вложени цикли (което има смисъл, когато един от входните данни е оценен като много малък). Това доведе до оператора за конкатенация и двата търсения на индекса се изпълняват 1000 пъти, за разлика от хеш съвпадението, избрано под флага за проследяване, където операторът за конкатенация и двете сканирания се изпълняват само веднъж.
- Разделът Table I/O също така показва 1000 сканирания (сканиране на диапазон, прикрити като търсене на индекс) и много по-висок брой на логическо четене спрямо
syscolpars(системната таблица задsys.all_columns). - Въпреки че продължителността не е била значително засегната (24 милисекунди срещу 18 милисекунди), вероятно можете да си представите какъв ефект биха могли да имат тези други разлики върху по-сериозна заявка.
- Ако превключим диаграмата към прогнозни разходи, можем да видим колко много различна променливата на таблицата може да заблуди оптимизатора без флага за проследяване:
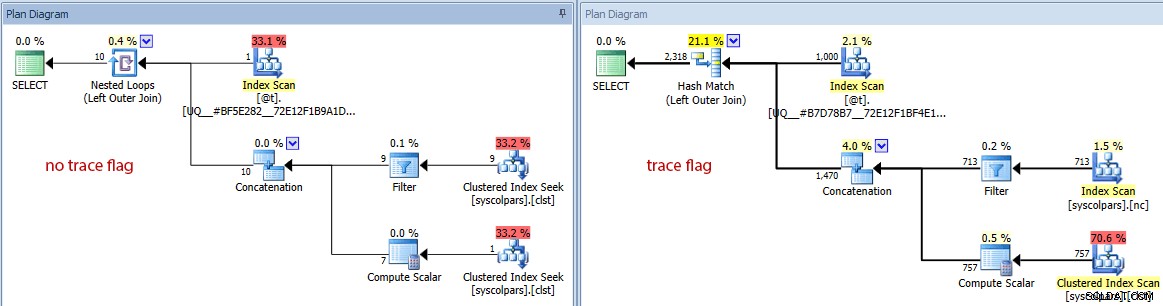
Сравняване на прогнозния брой редове (без флаг за проследяване вляво, проследяване флаг вдясно)
Ясно е и не е шокиращо, че оптимизаторът върши по-добра работа при избора на правилния план, когато има точна представа за включената мощност. Но на каква цена?
Прекомпилира и режийни
Когато използваме OPTION (RECOMPILE) с горната партида, без активиран флаг за проследяване, получаваме следния план – който е почти идентичен с плана с флага за проследяване (единствената забележима разлика е, че изчислените редове са 2316 вместо 2318):
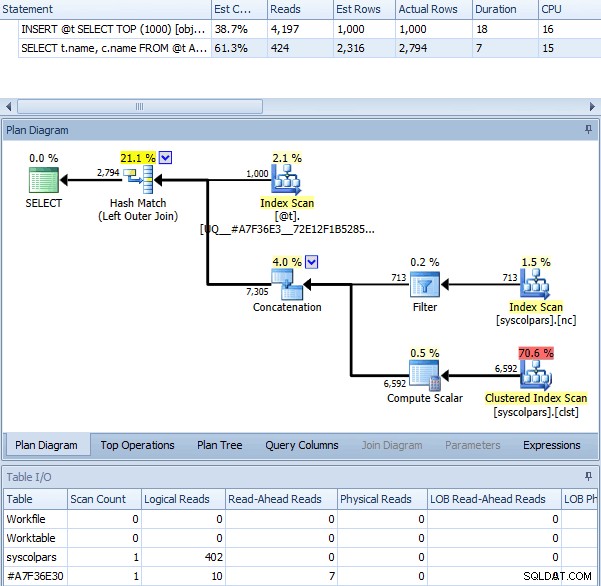
Същата заявка с OPTION (RECOMPILE)
Така че това може да ви накара да повярвате, че флагът за проследяване постига подобни резултати, като задейства прекомпилиране за вас всеки път. Можем да проучим това с помощта на много проста сесия за разширени събития:
CREATE EVENT SESSION [CaptureRecompiles] ON SERVER
ADD EVENT sqlserver.sql_statement_recompile
(
ACTION(sqlserver.sql_text)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = N'C:\temp\CaptureRecompiles.xel'
);
GO
ALTER EVENT SESSION [CaptureRecompiles] ON SERVER STATE = START; Изпълних следния набор от пакети, които изпълниха 20 заявки с (а) без опция за прекомпилиране или флаг за проследяване, (б) опция за повторно компилиране и (c) флаг за проследяване на ниво сесия.
/* default - no trace flag, no recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; GO 20 /* recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id] OPTION (RECOMPILE); GO 20 /* trace flag */ DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DBCC TRACEOFF(2453); GO 20
След това погледнах данните за събитието:
SELECT
sql_text = LEFT(sql_text, 255),
recompile_count = COUNT(*)
FROM
(
SELECT
x.x.value(N'(event/action[@name="sql_text"]/value)[1]',N'nvarchar(max)')
FROM
sys.fn_xe_file_target_read_file(N'C:\temp\CaptureRecompiles*.xel',NULL,NULL,NULL) AS f
CROSS APPLY (SELECT CONVERT(XML, f.event_data)) AS x(x)
) AS x(sql_text)
GROUP BY LEFT(sql_text, 255);
Резултатите показват, че не се е случило повторно компилиране при стандартната заявка, изразът, отнасящ се до променливата на таблицата, е бил прекомпилиран веднъж под флага за проследяване и, както може да очаквате, всеки път с RECOMPILE опция:
| sql_text | брой_прекомпилиране |
|---|---|
| /* прекомпилиране */ ДЕКЛАРИРАНЕ @t ТАБЛИЦА (i INT … | 20 |
| /* флаг за проследяване */ DBCC TRACEON(2453); ДЕКЛАРИРАНЕ @t … | 1 |
Резултати от заявка спрямо данни от XEvents
След това изключих сесията за разширени събития, след което промених партидата за измерване в мащаб. По същество кодът измерва 1000 итерации на създаване и попълване на променлива в таблицата, след което избира нейните резултати в таблица #temp (един от начините за потискане на изхода на толкова много изхвърляни набори от резултати), използвайки всеки от трите метода.
SET NOCOUNT ON; /* default - no trace flag, no recompile */ SELECT SYSDATETIME(); GO DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DROP TABLE #x; GO 1000 SELECT SYSDATETIME(); GO /* recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id] OPTION (RECOMPILE); DROP TABLE #x; GO 1000 SELECT SYSDATETIME(); GO /* trace flag */ DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DROP TABLE #x; DBCC TRACEOFF(2453); GO 1000 SELECT SYSDATETIME(); GO
Пуснах тази партида 10 пъти и взех средните стойности; те бяха:
| Метод | Средна продължителност (милисекунди) |
|---|---|
| По подразбиране | 23 148,4 |
| Прекомпилиране | 29 959,3 |
| Флаг за проследяване | 22 100,7 |
Средна продължителност за 1000 повторения
В този случай получаването на правилните оценки всеки път с помощта на подсказката за прекомпилиране беше много по-бавно от поведението по подразбиране, но използването на флага за проследяване беше малко по-бързо. Това има смисъл, защото – докато и двата метода коригират поведението по подразбиране за използване на фалшива оценка (и получаване на лош план в резултат на това), прекомпилирането отнема ресурси и, когато не го правят или не могат да доведат до по-ефективен план, са склонни да допринасят за общата продължителност на партидата.
Изглежда просто, но изчакайте...
Горният тест е леко – и умишлено – погрешен. Вмъкваме същия брой редове (1000) в променливата на таблицата всеки път . Какво се случва, ако първоначалната популация на променливата на таблицата варира за различните партиди? Със сигурност тогава ще видим прекомпилиране, дори под флага за проследяване, нали? Време е за още един тест. Нека настроим малко по-различна сесия за разширени събития, само с различно име на целевия файл (за да не смесим никакви данни от другата сесия):
CREATE EVENT SESSION [CaptureRecompiles_v2] ON SERVER
ADD EVENT sqlserver.sql_statement_recompile
(
ACTION(sqlserver.sql_text)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = N'C:\temp\CaptureRecompiles_v2.xel'
);
GO
ALTER EVENT SESSION [CaptureRecompiles_v2] ON SERVER STATE = START;
Сега, нека проверим тази партида, като настроим броя на редовете за всяка итерация, които са значително различни. Ще изпълним това три пъти, като премахнем съответните коментари, така че да имаме една партида без флаг за проследяване или изрично прекомпилиране, една партида с флага за проследяване и една партида с OPTION (RECOMPILE) (наличието на точен коментар в началото прави тези партиди по-лесни за идентифициране на места като изход за разширени събития):
/* default, no trace flag or recompile */
/* recompile */
/* trace flag */
DECLARE @i INT = 1;
WHILE @i <= 6
BEGIN
--DBCC TRACEON(2453); -- uncomment this for trace flag
DECLARE @t TABLE(id INT PRIMARY KEY);
INSERT @t SELECT TOP (CASE @i
WHEN 1 THEN 24
WHEN 2 THEN 1782
WHEN 3 THEN 1701
WHEN 4 THEN 12
WHEN 5 THEN 15
WHEN 6 THEN 1560
END) [object_id]
FROM sys.all_objects;
SELECT t.id, c.name
FROM @t AS t
INNER JOIN sys.all_objects AS c
ON t.id = c.[object_id]
--OPTION (RECOMPILE); -- uncomment this for recompile
--DBCC TRACEOFF(2453); -- uncomment this for trace flag
DELETE @t;
SET @i += 1;
END
Пуснах тези пакети в Management Studio, отворих ги поотделно в Plan Explorer и филтрирах дървото на изразите само в SELECT запитване. Можем да видим различното поведение в трите партиди, като разгледаме прогнозните и действителните редове:

Сравнение на три партиди, разглеждане на прогнозни спрямо действителни редове
В най-дясната мрежа можете ясно да видите къде не са се случили прекомпилации под флага за проследяване
Можем да проверим данните от XEvents, за да видим какво всъщност се е случило с прекомпилирането:
SELECT
sql_text = LEFT(sql_text, 255),
recompile_count = COUNT(*)
FROM
(
SELECT
x.x.value(N'(event/action[@name="sql_text"]/value)[1]',N'nvarchar(max)')
FROM
sys.fn_xe_file_target_read_file(N'C:\temp\CaptureRecompiles_v2*.xel',NULL,NULL,NULL) AS f
CROSS APPLY (SELECT CONVERT(XML, f.event_data)) AS x(x)
) AS x(sql_text)
GROUP BY LEFT(sql_text, 255); Резултати:
| sql_text | брой_прекомпилиране |
|---|---|
| /* прекомпилиране */ DECLARE @i INT =1; ДОКАТО ... | 6 |
| /* флаг за проследяване */ DECLARE @i INT =1; ДОКАТО ... | 4 |
Резултати от заявка спрямо данни от XEvents
Много интересно! Под флага за проследяване ние *правяме* виждаме повторно компилиране, но само когато стойността на параметъра по време на изпълнение се различава значително от кешираната стойност. Когато стойността на времето за изпълнение е различна, но не много, ние не получаваме повторно компилиране и се използват същите оценки. Така че е ясно, че флагът за проследяване въвежда праг за прекомпилиране към променливите на таблицата и аз потвърдих (чрез отделен тест), че това използва същия алгоритъм като този, описан за #temp таблици в тази "древна", но все още релевантна статия. Ще докажа това в последваща публикация.
Отново ще тестваме производителността, като стартираме партидата 1000 пъти (с изключена сесия за разширени събития) и ще измерваме продължителността:
| Метод | Средна продължителност (милисекунди) |
|---|---|
| По подразбиране | 101 285,4 |
| Прекомпилиране | 111 423,3 |
| Флаг за проследяване | 110 318,2 |
Средна продължителност за 1000 повторения
В този специфичен сценарий губим около 10% от производителността, като принуждаваме прекомпилиране всеки път или използвайки флаг за проследяване. Не съм съвсем сигурен как е разпределена делтата:Плановете, базирани на по-добри оценки, не бяха ли значително По-добре? Прекомпилирането компенсира всяко повишаване на производителността с толкова ? Не искам да отделям твърде много време за това и това беше тривиален пример, но той ще ви покаже, че играта с начина, по който работи оптимизатора, може да бъде непредсказуема работа. Понякога може да ви е по-добре с поведението по подразбиране на мощност =1, знаейки, че никога няма да предизвикате ненужни прекомпилации. Когато флагът за проследяване може да има много смисъл, е ако имате заявки, при които многократно попълвате променливи в таблицата със същия набор от данни (да речем, таблица за търсене на пощенски код) или винаги използвате 50 или 1000 реда (да речем, попълване таблична променлива за използване в пагинация). Във всеки случай, със сигурност трябва да тествате въздействието, което това има върху всяко работно натоварване, където планирате да въведете флага за проследяване или изрично прекомпилиране.
TVP и типове таблици
Също така ми беше любопитно как това ще се отрази на типовете таблици и дали ще видим някакви подобрения в кардиналността за TVP, където съществува същият симптом. Така че създадох прост тип таблица, която имитира използваната досега променлива на таблица:
USE MyTestDB; GO CREATE TYPE dbo.t AS TABLE ( id INT PRIMARY KEY );
След това взех горната партида и просто замених DECLARE @t TABLE(id INT PRIMARY KEY); с DECLARE @t dbo.t; – всичко останало си остана абсолютно същото. Пуснах същите три партиди и ето какво видях:

Сравняване на приблизителни и действителни стойности между поведението по подразбиране, прекомпилиране на опцията и флаг за проследяване 2453
Така че да, изглежда, че флагът за проследяване работи по абсолютно същия начин с TVP – прекомпилациите генерират нови оценки за оптимизатора, когато броят на редовете надвиши прага за повторно компилиране и се пропуска, когато броят на редовете е „достатъчно близо“.
Плюсове, минуси и предупреждения
Едно предимство на флага за проследяване е, че можете да избегнете някои прекомпилира и все още вижда кардиналността на таблицата – стига да очаквате броят на редовете в променливата на таблицата да бъде стабилен или да не наблюдавате значителни отклонения в плана поради различна мощност. Друго е, че можете да го активирате глобално или на ниво сесия и да не се налага да въвеждате съвети за повторно компилиране към всичките си заявки. И накрая, поне в случая, когато мощността на променливата на таблицата е била стабилна, правилните оценки доведоха до по-добра производителност от стандартната, а също и до по-добра производителност от използването на опцията за повторно компилиране – всички тези компилации със сигурност могат да се съберат.
Има и някои недостатъци, разбира се. Един, който споменах по-горе, е този в сравнение с OPTION (RECOMPILE) пропускате определени оптимизации, като например вграждане на параметри. Друго е, че флагът за проследяване няма да окаже въздействието, което очаквате върху тривиални планове. И едно, което открих по пътя е, че използвам QUERYTRACEON намек за налагане на флага за проследяване на ниво заявка не работи – доколкото мога да преценя, флагът за проследяване трябва да е на място, когато променливата на таблицата или TVP е създадена и/или попълнена, за да може оптимизаторът да види мощността по-горе 1.
Имайте предвид, че стартирането на флага за проследяване глобално въвежда възможността за регресия на плана на заявката към всяка заявка, включваща променлива на таблица (поради което тази функция беше въведена на първо място под флаг за проследяване), така че не забравяйте да тествате цялото си работно натоварване независимо как използвате флага за проследяване. Също така, когато тествате това поведение, моля, направете го в потребителска база данни; някои от оптимизациите и опростяванията, които обикновено очаквате да възникнат, просто не се случват, когато контекстът е зададен на tempdb, така че всяко поведение, което наблюдавате там, може да не остане последователно, когато преместите кода и настройките в потребителска база данни.
Заключение
Ако използвате таблични променливи или TVP с голям, но относително постоянен брой редове, може да ви се стори полезно да активирате този флаг за проследяване за определени партиди или процедури, за да получите точна мощност на таблицата, без ръчно да налагате прекомпилиране на отделни заявки. Можете също да използвате флага за проследяване на ниво екземпляр, което ще засегне всички заявки. Но както всяка промяна, и в двата случая ще трябва да бъдете усърдни в тестването на ефективността на цялото си работно натоварване, да следите изрично за всякакви регресии и да гарантирате, че искате поведението на флага за проследяване, защото можете да се доверите на стабилността на вашата променлива в таблицата брой редове.
Радвам се да видя флага за проследяване, добавен към SQL Server 2014, но би било по-добре това просто да стане поведението по подразбиране. Не че има някакво значително предимство при използването на големи таблични променливи пред големите #temp таблици, но би било хубаво да се види повече паритет между тези два типа временни структури, които биха могли да бъдат продиктувани на по-високо ниво. Колкото повече паритет имаме, толкова по-малко хората трябва да се обмислят кой да използват (или поне да имат по-малко критерии, които да вземат предвид при избора). Мартин Смит има страхотни въпроси и отговори в dba.stackexchange, които вероятно сега трябва да бъдат актуализирани:Каква е разликата между временна таблица и променлива на таблица в SQL Server?
Важна забележка
Ако ще инсталирате SQL Server 2012 Service Pack 2 (независимо дали ще използвате този флаг за проследяване или не), моля, вижте и моята публикация за регресия в SQL Server 2012 и 2014, която може – в редки случаи – да въведе потенциална загуба на данни или повреда по време на възстановяване на онлайн индекса. Налични са кумулативни актуализации за SQL Server 2012 SP1 и SP2, както и за SQL Server 2014. Няма да има корекция за клона на RTM 2012.
По-нататъшно тестване
Имам и други неща в списъка си за тестване. Първо, бих искал да видя дали този флаг за проследяване има някакъв ефект върху типовете таблици в паметта в SQL Server 2014. Също така ще докажа без сянка на съмнение, че флагът за проследяване 2453 използва същия праг за прекомпилиране за таблица променливи и TVP, както е за #temp таблици.