Базата данни е критична и жизненоважна част от всеки бизнес или организация. Нарастващите тенденции прогнозират, че 82% от предприятията очакват броят на базите данни да се увеличи през следващите 12 месеца. Основно предизвикателство пред всеки DBA е да открие как да се справи с масивния растеж на данни и това ще бъде най-важната цел. Как можете да увеличите производителността на базата данни, да намалите разходите и да премахнете престоя, за да предоставите на потребителите възможно най-доброто изживяване? Опция ли е компресирането на данни? Нека започнем и да видим как някои от съществуващите функции могат да бъдат полезни за справяне с подобни ситуации.
В тази статия ще научим как решението за компресиране на данни може да ни помогне да оптимизираме решението за управление на данни. В това ръководство ще разгледаме следните теми:
- Общ преглед на компресията
- Предимства от компресията
- Очерк на данните са техниките за компресиране
- Обсъждане на различни видове компресия на данни
- Факти за компресирането на данни
- Съображения за внедряване
- и още...
Компресия
Компресирането е техника и следователно ресурсочувствителна операция, но с хардуерни компромиси. Човек трябва да помисли за внедряване на компресиране на данни за следните предимства:
- Ефективно управление на пространството
- Ефективна техника за намаляване на разходите
- Лесно управление на архивиране на база данни
- Ефективно използване на честотната лента N/W
- Безопасно и по-бързо възстановяване или възстановяване
- По-добра производителност – намалява обема на паметта на системата
Забележка: Ако SQL Server е с ограничен процесор или памет, тогава компресията може да не отговаря на вашата среда.
Компресирането на данни се отнася за:
- Купини
- Клъстерни индекси
- Неклъстерни индекси
- Дялове
- Индексирани изгледи
Забележка: Големите обекти не се компресират (например LOB и BLOB)
Най-подходящ за следните приложения:
- Регистрационни таблици
- Одиторски таблици
- Таблици с факти
- Отчитане
Въведение
Компресирането на данни е технология, която съществува от SQL Server 2008. Идеята на компресирането на данни е, че можете избирателно да избирате таблици, индекси или дялове в базата данни. I/O продължава да бъде пречка при преместването на информация между вход и изход от базата данни. Компресирането на данни се възползва от този тип и спомага за повишаване на ефективността на база данни. Тъй като знаем, че скоростите на мрежата са много по-бавни от скоростта на обработка, е възможно да се намери повишаване на ефективността, като се използва процесорната мощност за компресиране на данни в база данни, така че да пътуват по-бързо. И след това отново използвайте процесорна мощност, за да декомпресирате данните от другия край. Като цяло компресирането на данни намалява пространството, заето от данните. Техниката за компресиране на данни е достъпна за всяка база данни и се поддържа от всички издания на SQL Server 2016 SP1. Преди това беше достъпно само в издания на SQL Server Enterprise или Developer, а не в Standard или Express.
Поддръжка на функции

Типове компресия на данни
В SQL Server има два типа компресия на данни, на ниво ред и на ниво страница.
Компресията на ниво ред работи зад кулисите и преобразува всички типове данни с фиксирана дължина в типове с променлива дължина. Предположението тук е, че често данните се съхраняват с тип с фиксирана дължина, като char 100, и те всъщност не попълват целите 100 знака за всеки запис. Малки печалби могат да бъдат постигнати чрез премахване на това допълнително пространство от масата. Разбира се, ако вашите таблици с данни не използват текстови и числови полета с фиксирана дължина или ако го правят и всъщност съхранявате напълно допустимия брой знаци и цифри, тогава усилването на компресията по схемата на ниво ред ще бъде минимално в най-добрия случай.
Концепцията за компресия е разширена до всички типове данни с фиксирана дължина, включително char, int и float. SQL Server позволява спестяване на място чрез съхраняване на данните, сякаш е тип с променлив размер; данните ще се появят и ще се държат като фиксирана дължина.
Например, ако сте съхранили стойността на 100 в int колона, SQL Server не трябва да използва всички 32 бита, вместо това той просто използва 8 бита (1 байт).
Компресирането на ниво страница извежда нещата на друго ниво. Първо, той автоматично прилага компресия на ниво ред върху полета с данни с фиксирана дължина, така че автоматично получавате тези печалби по подразбиране. След това на всичкото отгоре прилага нещо, наречено компресиране на префикс, и друга техника, наречена компресия на речник.
Компресия на ред
Компресията на редове е вътрешно ниво на компресия, което съхранява фиксираните низове от знаци, като използва формат с променлива дължина, като не съхранява празните знаци. Следните стъпки се изпълняват при компресирането на ниво ред.
- Всички типове числови данни като int , float , десетична, и пари се преобразуват в типове данни с променлива дължина. Например, 125, съхранявани в колона, и типът данни на колоната е цяло число. Тогава знаем, че 4 байта се използват за съхраняване на целочислената стойност. Но 125 може да се съхранява в 1 байт, защото 1 байт може да съхранява стойности от 0 до 255. Така че 125 може да се съхранява като малък int , така че да могат да бъдат запазени 3 байта.
- Символ и Nchar типовете данни се съхраняват като типове данни с променлива дължина. Например, “SQL” се съхранява в char (20) тип колона. Но след компресиране ще се използват само 3 байта. След компресирането на данни с този тип данни не се съхранява празен знак.
- Метаданните на записа са намалени.
- Стойностите NULL и 0 са оптимизирани и не се изразходва място.
Компресия на страница
Компресирането на страници е усъвършенствано ниво на компресиране на данни. По подразбиране компресията на страница също прилага компресията на ниво ред. Компресирането на страници се категоризира в два типа
- Компресия на префикс и
- Компресия на речника.
Компресия на префикс
При компресиране на префикс за всяка страница, за всяка колона в страницата, обща стойност се извлича от всички редове и се съхранява под заглавката на всяка колона. Сега във всеки ред се съхранява препратка към тази стойност вместо обща стойност.
Компресиране на речник
Компресията на речника е подобна на компресията на префикса, но общите стойности се извличат от всички колони и се съхраняват във втория ред след заглавката. Компресирането на речника търси точни съвпадения на стойностите във всички колони и редове на всяка страница.
Можем да извършим компресиране на ниво ред и страница за следните обекти на база данни.
- Таблица, съхранявана в купчина.
- Цяла таблица, съхранена като клъстериран индекс.
- Индексиран изглед.
- Неклъстериран индекс.
- Разделени индекси и таблици.
Забележка: Можем да извършим компресиране на данни или по време на създаването като CREATE TABLE, CREATE INDEX или след създаването с помощта на команда ALTER с опция REBUILD като ALTER TABLE .... ИЗГРАЖДАНЕ СЪС.
Демо
WideWorldImporters базата данни се използва през цялата демонстрация. Също така DW в реално време база данни се разглежда за операцията на компресиране.
Нека да преминем през стъпките в подробности:
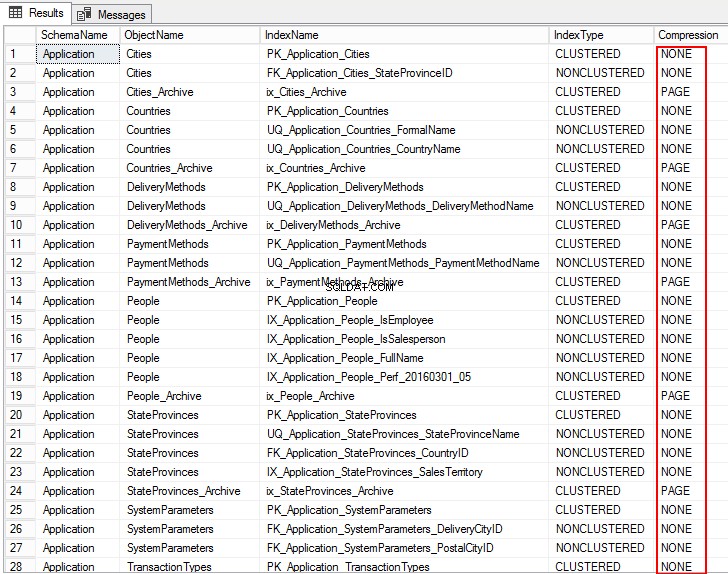
1. За да видите настройките за компресиране за обекти в базата данни, изпълнете следния T-SQL:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' ORDER BY S.name, O.name, I.index_id; GO
Следният изход показва типа на компресия като PAGE, ROW и за няколко таблици е NONE. Това означава, че не е конфигуриран за компресиране.
2. За да оцените компресията, изпълнете следната системна съхранена процедура sp_estimate_data_compression_savings . В този случай съхранената процедура се изпълнява в таблиците PurchaseOrderLines.
3. Нека разберем настройката за компресиране на PurchaseOrderLines, като изпълним следния T-SQL:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' and o.name ='PurchaseOrderLines' ORDER BY S.name, O.name, I.index_id;
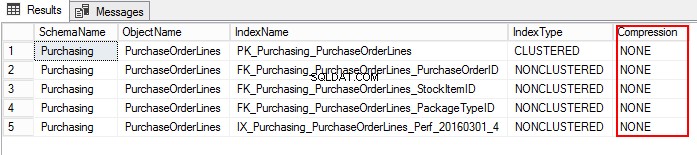
EXEC sp_estimate_data_compression_savings @schema_name = 'Purchasing', @object_name = 'PurchaseOrderLines', @index_id = NULL, @partition_number = NULL, @data_compression = 'Page'; GO

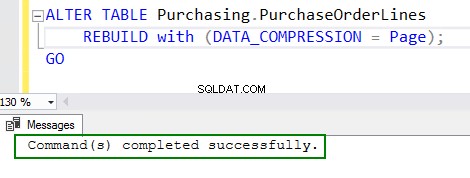
4. Активирайте компресията, като изпълните командата ALTER table:
ALTER TABLE Purchasing.PurchaseOrderLines REBUILD with (DATA_COMPRESSION = Page); GO
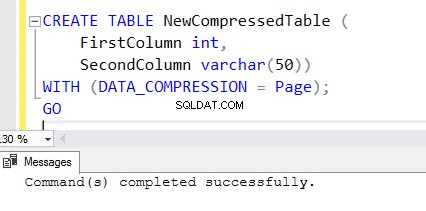
5. За да създадете нова таблица с активирана функция за компресиране, добавете клаузата WITH в края на израза CREATE TABLE. Можете да видите по-долу израз CREATE TABLE, използван за създаване на NewCompressedTable .
CREATE TABLE NewCompressedTable (
FirstColumn int,
SecondColumn varchar(50))
WITH (DATA_COMPRESSION = Page);
GO
Факти за компресиране на данни
Нека разгледаме част от действителната информация за компресията
- Компресията не може да се приложи към системни таблици
- Таблица не може да бъде активирана за компресиране, когато размерът на реда надвишава 8060 байта.
- Компресираните данни се кешират в буферния пул; това означава по-бързо време за реакция
- Активирането на компресията може да доведе до промяна на плановете на заявките, тъй като данните се съхраняват с помощта на различен брой страници и брой редове на страница.
- Неклъстерираните индекси не наследяват свойството на компресия
- Когато клъстериран индекс е създаден в хийп, клъстерираният индекс наследява състоянието на компресия на купчината, освен ако не е посочено алтернативно състояние на компресия.
- Компресиите на ниво ROW и PAGE могат да бъдат активирани и деактивирани, офлайн или онлайн.
- Ако настройката на хепа се промени, тогава всички неклъстерирани индекси трябва да бъдат възстановени.
- Изискванията за дисково пространство за активиране или деактивиране на компресията на ред или страница са същите като за създаване или повторно изграждане на индекс.
- Когато дяловете се разделят с помощта на оператора ALTER PARTITION, и двата дяла наследяват атрибута за компресиране на данни на оригиналния дял.
- Когато два дяла са обединени, полученият дял наследява атрибута за компресиране на данни на целевия дял.
- За да превключите дял, свойството за компресиране на данни на дяла трябва да съвпада със свойството за компресиране на таблицата.
- Таблиците и индексите на Columnstore винаги се съхраняват с компресията на Columnstore.
- Компресирането на данни е несъвместимо с редки колони, така че таблицата не може да бъде компресирана.
Сценарий в реално време
Нека да преминем през техниката за компресиране на данни и да разберем основните параметри на компресирането на данни.
За да проверите пространството, използвано от всяка таблица, изпълнете следния T-SQL. Резултатът от заявката ни дава подробна информация за използването на всяка таблица. Това би било решаващият фактор за прилагането на компресирането на данни.
SELECT
t.NAME AS TableName,
i.name as indexName,
sum(p.rows) as RowCounts,
sum(a.total_pages) as TotalPages,
sum(a.used_pages) as UsedPages,
sum(a.data_pages) as DataPages,
(sum(a.total_pages) * 8) / 1024 as TotalSpaceMB,
(sum(a.used_pages) * 8) / 1024 as UsedSpaceMB,
(sum(a.data_pages) * 8) / 1024 as DataSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
WHERE
t.NAME NOT LIKE 'dt%' AND
i.OBJECT_ID > 255 AND
i.index_id <= 1
GROUP BY
t.NAME, i.object_id, i.index_id, i.name
ORDER BY
TotalSpaceMB desc
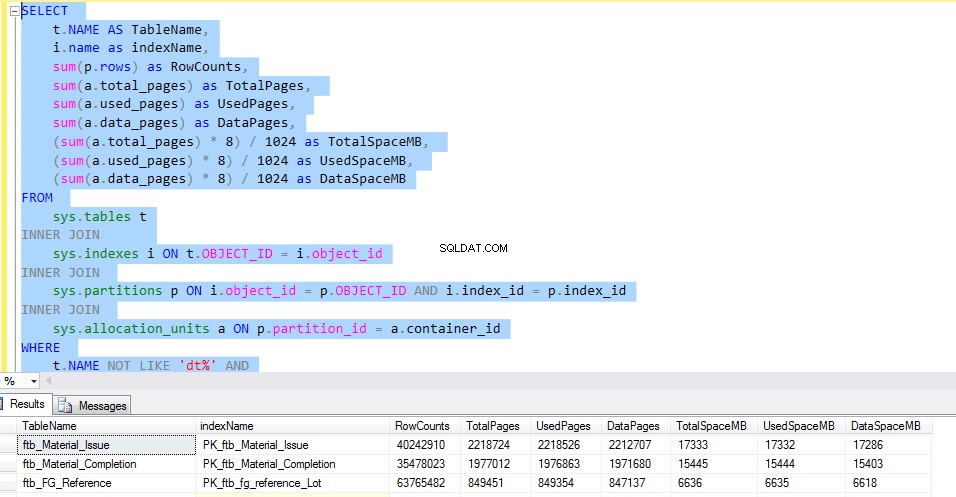
Нека разгледаме ftb_material_Issue таблица с факти. Таблицата с факти има числови типове данни BIGINT.
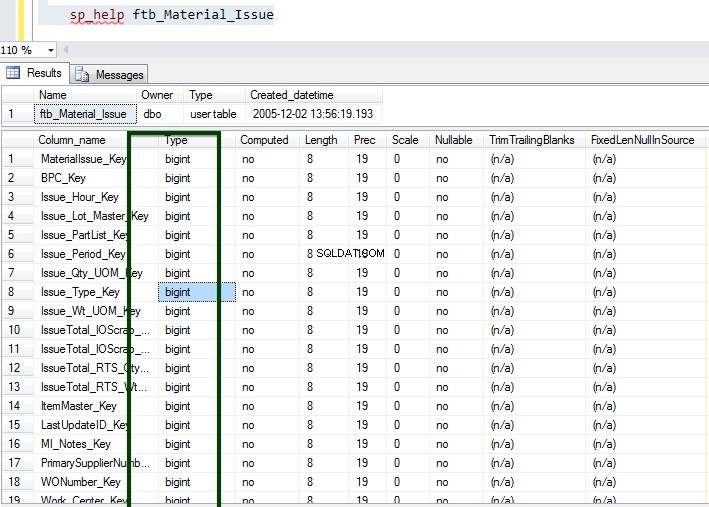
Сега стартирайте съхранената процедура sp_spaceused, за да разберете подробностите за таблицата. Можете да научите повече за командата sp_spaceused тук.
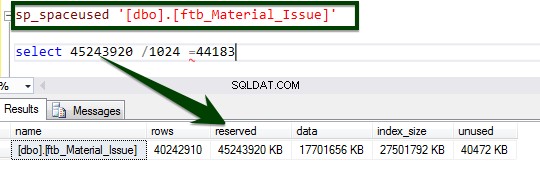
Активирайте компресирането на ниво таблица, като стартирате следния T-SQL. Следният T-SQL беше изпълнен на сървъра и отне 34 минути 14 секунди, за да се компресира страницата на ниво таблица.
ALTER TABLE dbo.ftb_material_Issue REBUILD with (DATA_COMPRESSION = Page);
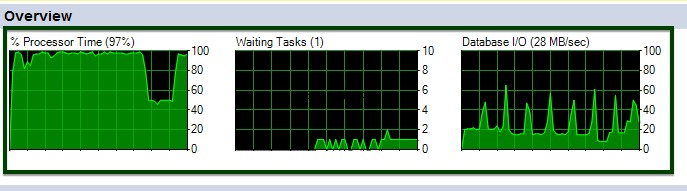
Можете да видите колебанията на процесора и I/O по време на изпълнението на командата ALTER table.
Сега, нека направим сравнението Преди v/s След компресията на данни. Размерът на таблицата около ~45 GB е намален до ~15 GB.
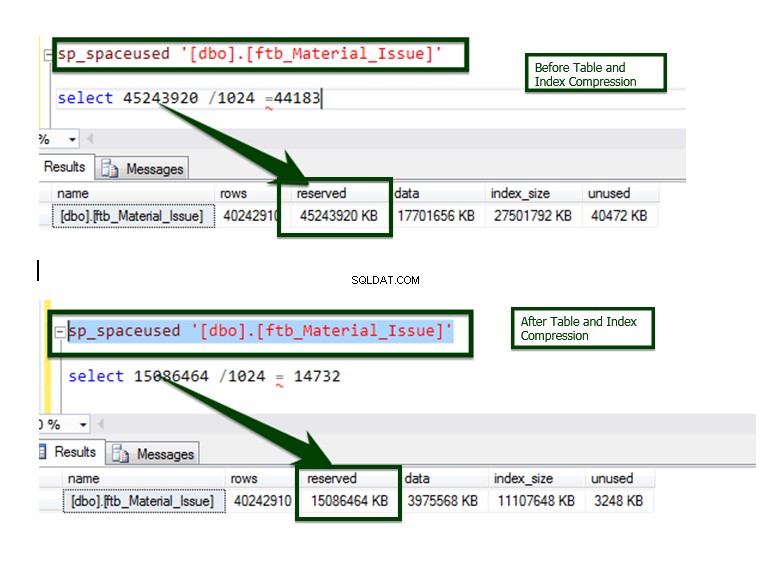
Процесът се реализира на повечето обекти с помощта на автоматизиран скрипт и ето крайният резултат от сравнението.
Сравнение на данни между преди и след операцията за компресиране на индекса.

Резюме
Компресирането на данни е много ефективна техника за намаляване на размера на данните; намалените данни изискват по-малко I/O процеси. Добавянето на компресия към базата данни увеличава натоварването на изискванията на процесора. Ще трябва да се уверите, че разполагате с наличния капацитет за обработка, за да посрещнете тези промени по ефективен начин. Така че е по-добре първо да направите малко проучване и да видите видовете печалби, които могат да се очакват, преди да приложите модификациите, за да активирате компресирането на данни. Това е много полезно при настройката на облачната база данни, където са включени разходи.
Поставете компресиите (не ги правете всички наведнъж) и компресирайте през периоди от време с ниска активност. Компресирането на данни и компресирането на архивиране съжителстват добре и могат да доведат до допълнително спестяване на място за съхранение, така че продължете и се отдайте.
Компресията не само намалява физическите размери на файловете, но също така намалява дисковия вход/изход, което може значително да подобри производителността на много приложения за бази данни, заедно с архивирането на база данни.
Вземането на решение за прилагане на компресия е по-лесно, ако познаваме основната инфраструктура и бизнес изисквания. Определено можем да използваме наличната системна процедура, за да разберем и оценим спестяванията от компресия. Тази съхранена процедура не предоставя такива подробности, които да ви кажат как компресията ще повлияе положително или отрицателно на вашата система. Очевидно е, че има компромиси с всякакъв вид компресия. Ако имате същите модели на огромни данни, тогава компресирането е ключът към спестяване на място. С нарастването на мощността на процесора и всяка система, свързана с многоядрени структури, компресията може да е подходяща за много системи. Бих препоръчал да тествате системите си. Тествайте, за да се уверите, че производителността няма отрицателно въздействие. Ако даден индекс има много актуализации и изтривания, цената на процесора за компресиране и декомпресиране на данните може да надвиши спестяванията на I/O и RAM от компресирането на данни. Не всяка база данни или таблица автоматично ще бъде добър кандидат за прилагане на компресия, така че е най-добре първо да направите малко проучване, за да видите видовете печалби, които могат да се очакват, преди да приложите модификациите, за да активирате компресирането на данни във вашите бази данни. Трябва да тествате компресията, за да видите дали работи добре във вашата среда, защото може да не работи добре в бази данни с тежко вмъкване.
Препратки
Издания и поддържани функции на SQL Server 2016
Компресиране на данни
Реализация на компресиране на ред
Внедряване на компресиране на страница



