Публикувах множество бенчмаркове, сравняващи различни версии на PostgreSQL, като например разговора за археология на производителността (оценяване на PostgreSQL 7.4 до 9.4) и всички тези бенчмаркове предполагат фиксирана среда (хардуер, ядро, ...). Което е добре в много случаи (например при оценка на въздействието върху производителността на пач), но при производството тези неща се променят с времето – получавате надстройки на хардуера и от време на време получавате актуализация с нова версия на ядрото.
За надстройки на хардуера (по-добро съхранение, повече RAM, по-бързи процесори,...) въздействието обикновено е сравнително лесно за прогнозиране и освен това хората обикновено осъзнават, че трябва да оценят въздействието, като анализират тесните места в производството и може би дори първо тестват новия хардуер .
Но какво ще кажете за актуализациите на ядрото? За съжаление обикновено не правим много бенчмаркинг в тази област. Предположението е най-вече, че новите ядра са по-добри от по-старите (по-бързи, по-ефективни, мащабирани до повече CPU ядра). Но наистина ли е вярно? И колко голяма е разликата? Например какво ще стане, ако надстроите ядрото от 3.0 на 4.7 – това ще се отрази ли на производителността и ако да, ще се подобри ли производителността или не?
От време на време получаваме доклади за сериозни регресии с конкретна версия на ядрото или внезапно подобрение между версиите на ядрото. Така че е ясно, че версиите на ядрото могат да повлияят на производителността.
Запознат съм с един единствен бенчмарк на PostgreSQL, сравняващ различни версии на ядрото, направен през 2014 г. от Сергей Коноплев в отговор на препоръките за избягване на 3.0 – 3.8 ядра. Но този бенчмарк е доста стар (последната налична версия на ядрото преди ~18 месеца беше 3.13, докато в днешно време имаме 3.19 и 4.6), така че реших да стартирам някои бенчмаркове с текущите ядра (и PostgreSQL 9.6beta1).
PostgreSQL спрямо версиите на ядрото
Но първо, нека обсъдя някои значителни разлики между политиките, управляващи ангажиментите в двата проекта. В PostgreSQL имаме концепцията за главни и второстепенни версии – основните версии (например 9.5) се пускат приблизително веднъж годишно и включват различни нови функции. Малките версии (напр. 9.5.2) включват само корекции на грешки и се пускат на всеки три месеца (или по-често, когато се открие сериозна грешка). Така че не трябва да има големи промени в производителността или поведението между второстепенните версии, което прави доста безопасно внедряването на второстепенни версии без задълбочено тестване.
С версиите на ядрото ситуацията е много по-неясна. Ядрото на Linux също има разклонения (например 2.6, 3.0 или 4.7), които в никакъв случай не са равни на „основни версии“ от PostgreSQL, тъй като продължават да получават нови функции, а не само корекции на грешки. Не твърдя, че политиката на PostgreSQL за версиите е някак си автоматично по-добра, но последствието е, че актуализирането между второстепенни версии на ядрото може лесно да повлияе значително на производителността или дори да въведе грешки (например 3.18.37 страда от проблеми с OOM поради такава непоправка на грешки ангажимент).
Разбира се, дистрибуциите осъзнават тези рискове и често заключват версията на ядрото и правят допълнителни тестове, за да отстранят нови грешки. Тази публикация обаче използва ванилови дългосрочни ядра, налични на www.kernel.org.
Сравнение
Има много бенчмаркове, които можем да използваме – тази публикация представя набор от pgbench тестове, т.е. сравнително прост OLTP (подобен на TPC-B) бенчмарк. Планирам да направя допълнителни тестове с други типове сравнителни показатели (особено ориентирани към DWH/DSS) и ще ги представя в този блог в бъдеще.
Сега, обратно към pgbench – когато казвам „колекция от тестове“, имам предвид комбинации от
- само за четене срещу четене-запис
- размер на набора от данни – активният набор (не) се вписва в споделени буфери/RAM
- брой клиенти – един клиент срещу много клиенти (заключване/планиране)
Стойностите очевидно зависят от използвания хардуер, така че нека да видим на какъв хардуер се изпълняваше този кръг от бенчмаркове:
- ЦП:Intel i5-2500k @ 3,3 GHz (3,7 GHz турбо)
- RAM:8 GB (DDR3 @ 1333 MHz)
- съхранение:6x Intel SSD DC S3700 в RAID-10 (Linux sw raid)
- файлова система:ext4 с I/O планировчик по подразбиране (cfq)
Така че това е същата машина, която използвах за редица предишни тестове – сравнително малка машина, не точно най-новият процесор и т.н., но вярвам, че все още е разумна „малка“ система.
Параметрите на бенчмарк са:
- Мащати на набора от данни:30, 300 и 1500 (така че приблизително 450MB, 4,5GB и 22,5GB)
- брои на клиента:1, 4, 16 (машината има 4 ядра)
За всяка комбинация имаше 3 цикъла само за четене (по 15 минути всеки) и 3 цикъла за четене и запис (по 30 минути). Действителният скрипт, управляващ бенчмарка, е достъпен тук (заедно с резултати и други полезни данни).
Забележка :Ако имате значително различен хардуер (например ротационни устройства), може да видите много различни резултати. Ако имате система, която искате да тествате, уведомете ме и ще ви помогна с това (ако приемем, че ще ми бъде позволено да публикувам резултатите).
Версии на ядрото
По отношение на версиите на ядрото, тествах най-новите версии във всички дългосрочни клонове от 2.6.x (2.6.39, 3.0.101, 3.2.81, 3.4.112, 3.10.102, 3.12.61, 3.14.73, 3.16. 36, 3.18.38, 4.1.29, 4.4.16, 4.6.5 и 4.7). Все още има много системи, работещи на ядра 2.6.x, така че е полезно да знаете колко производителност може да спечелите (или загубите), като надстроите до по-ново ядро. Но компилирах всички ядра сам (т.е. използвах ванилови ядра, без специфични за дистрибуцията пачове) и конфигурационните файлове са в хранилището на git.
Резултати
Както обикновено, всички данни са налични в bitbucket, включително
- kernel .config файл
- скрипт за сравнителен анализ (run-pgbench.sh)
- Конфигурация на PostgreSQL (с някои основни настройки за хардуера)
- Регистъри на PostgreSQL
- различни системни регистрационни файлове (dmesg, sysctl, mount, ...)
Следните диаграми показват средните tps за всеки бенчмаркиран случай – резултатите за трите серии са доста последователни, с ~2% разлика между min и max в повечето случаи.
само за четене
За най-малкия набор от данни има ясен спад на производителността между 3,4 и 3,10 за всички клиенти. Резултатите за 16 клиента (4 пъти броя на ядрата) обаче се възстановяват повече от 3.12.
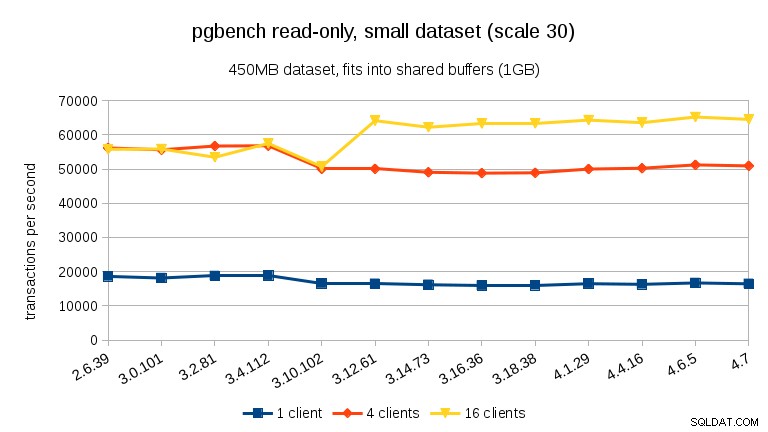
За средния набор от данни (побира се в RAM, но не и в споделени буфери) можем да видим същия спад между 3.4 и 3.10, но не и възстановяването в 3.12.
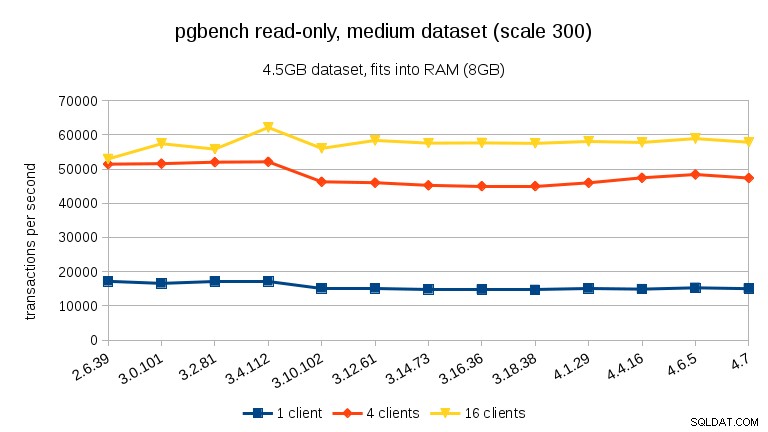
За големи набори от данни (надвишаващи RAM, толкова силно свързани с I/O) резултатите са много различни – не съм сигурен какво се случи между 3.10 и 3.12, но подобрението на производителността (особено за по-голям брой клиенти) е доста удивително.
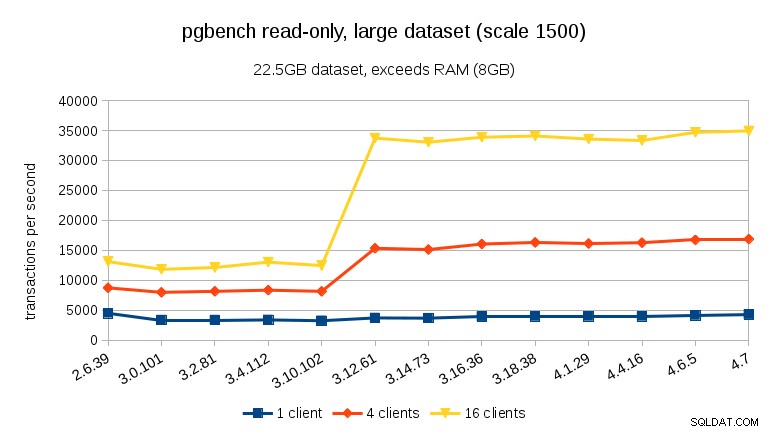
четене-запис
За натоварването за четене и запис резултатите са доста сходни. За малките и средните набори от данни можем да наблюдаваме същия спад от ~10% между 3.4 и 3.10, но за съжаление няма възстановяване в 3.12.
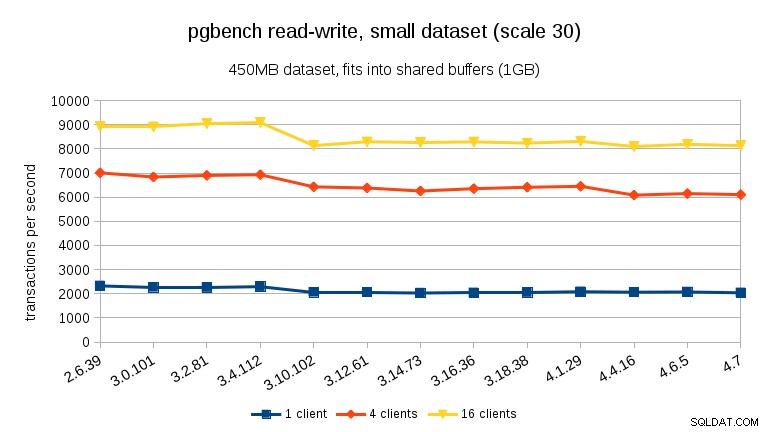
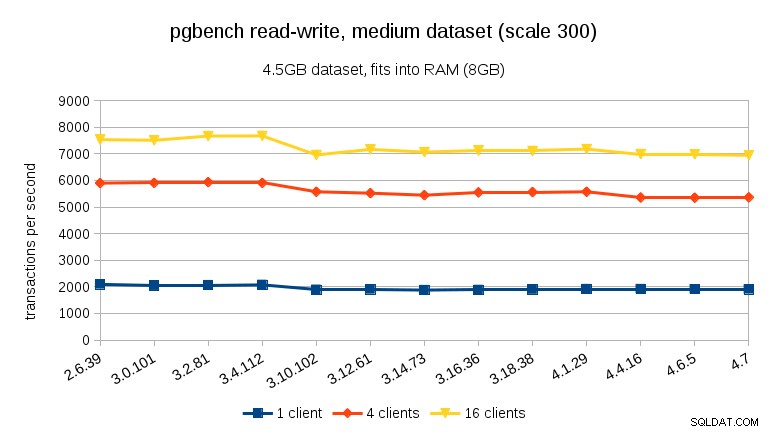
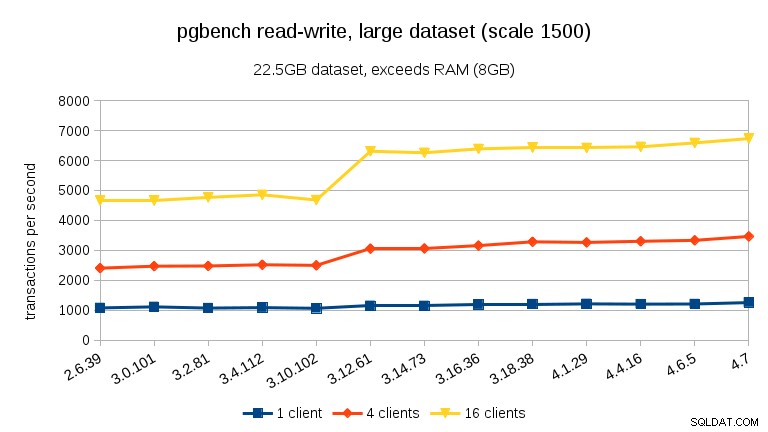
За големия набор от данни (отново, значително обвързан с I/O) можем да видим подобно подобрение в 3.12 (не толкова значително, колкото за натоварването само за четене, но все пак значително):
Резюме
Не смея да правя изводи от един бенчмарк на една машина, но мисля, че е безопасно да кажа:
- Общата производителност е доста стабилна, но можем да видим някои значителни промени в производителността (в двете посоки).
- С набори от данни, които се вписват в паметта (или в shared_buffers, или поне в RAM), виждаме измерим спад в производителността между 3.4 и 3.10. При тест само за четене това частично се възстановява в 3.12 (но само за много клиенти).
- С набори от данни, надвишаващи паметта и по този начин основно свързани с I/O, не виждаме подобен спад в производителността, а вместо това значително подобрение в 3.12.
Що се отнася до причините, поради които се случват тези внезапни промени, не съм съвсем сигурен. Между версиите има много възможни релевантни комитове, но не съм сигурен как да идентифицирам правилния без обширно (и отнемащо време) тестване. Ако имате други идеи (напр. знаете за подобни ангажименти), уведомете ме.