Много е лесно да се докаже, че следните два израза дават абсолютно същия резултат:първия ден от текущия месец.
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE())); И те отнемат приблизително същото време за изчисляване:
SELECT SYSDATETIME(); GO DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); GO 1000000 GO SELECT SYSDATETIME(); GO DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()); GO 1000000 SELECT SYSDATETIME();
В моята система и двете партиди отнеха около 175 секунди за завършване.
И така, защо предпочитате един метод пред другия? Когато един от тях наистина се забърква с оценките за мощност .
Като кратък пример, нека сравним тези две стойности:
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), -- today: 2013-09-01
DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0); -- today: 1786-05-01
--------------------------------------^^^^^^^^^^^^ notice how these are swapped
(Обърнете внимание, че действителните стойности, представени тук, ще се променят в зависимост от това кога четете тази публикация – „днес“, споменат в коментара, е 5 септември 2013 г., денят, в който е написана тази публикация. През октомври 2013 г., например, изходът ще да бъде 2013-10-01 и 1786-04-01 .)
Като изключим това, позволете ми да ви покажа какво имам предвид...
Възпроизведение
Нека създадем много проста таблица, само с клъстерирана DATE колона и заредете 15 000 реда със стойността 1786-05-01 и 50 реда със стойността 2013-09-01 :
CREATE TABLE dbo.DateTest ( CreateDate DATE ); CREATE CLUSTERED INDEX x ON dbo.DateTest(CreateDate); INSERT dbo.DateTest(CreateDate) SELECT TOP (15000) DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 UNION ALL SELECT TOP (50) DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0) FROM sys.all_objects;
И тогава нека разгледаме действителните планове за тези две заявки:
SELECT /* Query 1 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); SELECT /* Query 2 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
Графичните планове изглеждат правилно:
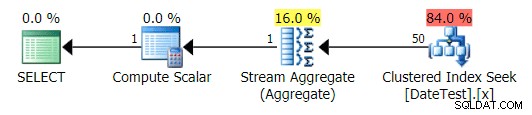
Графичен план за DATEDIFF(MONTH, 0, GETDATE()) запитване
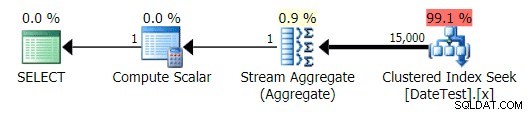
Графичен план за DATEDIFF(MONTH, GETDATE(), 0) запитване
Но прогнозните разходи са неуспешни – обърнете внимание колко по-високи са прогнозните разходи за първата заявка, която връща само 50 реда, в сравнение с втората заявка, която връща 15 000 реда!

Решетка на отчета, показваща прогнозните разходи
И разделът Най-добри операции показва, че първата заявка (търси 2013-09-01 ) изчисли, че ще намери 15 000 реда, докато в действителност намери само 50; втората заявка показва обратното:очаква се да намери 50 реда, съответстващи на 1786-05-01 , но намериха 15 000. Въз основа на неправилни оценки за мощността като тази, сигурен съм, че можете да си представите какъв драстичен ефект може да има това върху по-сложни заявки срещу много по-големи набори от данни.
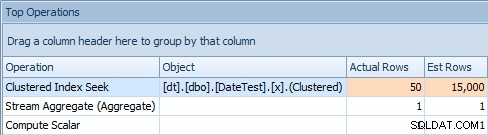
Раздел „Най-добри операции“ за първата заявка [DATEDIFF(MONTH, 0, GETDATE())]
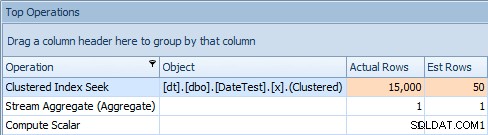
Раздел „Най-добри операции“ за втората заявка [DATEDIFF(MONTH, 0, GETDATE())]
Малко по-различен вариант на заявката, използващ различен израз за изчисляване на началото на месеца (за което се споменава в началото на публикацията), не показва този симптом:
SELECT /* Query 3 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
Планът е много подобен на заявка 1 по-горе и ако не сте погледнали по-отблизо, бихте помислили, че тези планове са еквивалентни:
Графичен план за заявка, която не е DATEDIFF
Когато погледнете раздела „Най-добри операции“ тук, обаче, виждате, че оценката е безупречна:
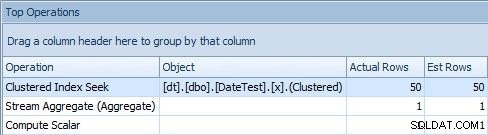
Раздел „Най-добри операции“, показващ точни прогнози
При този конкретен размер на данни и заявка, нетното въздействие върху производителността (най-вече продължителността и четенията) е до голяма степен без значение. И е важно да се отбележи, че самите заявки все още връщат правилни данни; просто оценките са грешни (и могат да доведат до по-лош план, отколкото демонстрирах тук). Въпреки това, ако извличате константи с помощта на DATEDIFF в рамките на вашите заявки по този начин, наистина трябва да тествате това въздействие във вашата среда.
И защо се случва това?
Казано по-просто, SQL Server има DATEDIFF грешка, при която разменя втория и третия аргумент, когато оценява израза за оценка на мощността. Това изглежда включва постоянно сгъване, поне периферно; има много повече подробности за постоянното сгъване в тази статия на Books Online, но за съжаление статията не разкрива никаква информация за този конкретен бъг.
Има поправка – или има?
Има статия от базата знания (KB #2481274), която твърди, че решава проблема, но има няколко собствени проблема:
- В статията на KB се твърди, че проблемът е отстранен в различни сервизни пакети или кумулативни актуализации за SQL Server 2005, 2008 и 2008 R2. Въпреки това, симптомът все още присъства в клонове, които не са изрично споменати там, въпреки че са виждали много допълнителни CU от публикуването на статията. Все още мога да възпроизвеждам този проблем на SQL Server 2008 SP3 CU #8 (10.0.5828) и SQL Server 2012 SP1 CU #5 (11.0.3373).
- Пренебрегва да се спомене, че за да се възползвате от корекцията, трябва да включите флаг за проследяване 4199 (и да се „ползвате“ от всички други начини, по които специфичен флаг за проследяване може да повлияе на оптимизатора). Фактът, че този флаг за проследяване е необходим за корекцията, е споменат в свързан елемент на Connect, #630583, но тази информация не се е върнала обратно в статията KB. Нито статията KB, нито елементът Connect дават някаква представа за причината (че аргументите за
DATEDIFFса били разменени по време на оценката). Положителната страна е, че изпълняването на горните заявки с включен флаг за проследяване (използвайкиOPTION (QUERYTRACEON 4199)) дава планове, които нямат проблем с неправилната оценка.
- Предлага ви да използвате динамичен SQL, за да заобиколите проблема. В моите тестове, използвайки различен израз (като този по-горе, който не използва
DATEDIFF) преодоля проблема в съвременните компилации както на SQL Server 2008, така и на SQL Server 2012. Препоръчването на динамичен SQL тук е ненужно сложно и вероятно прекомерно, като се има предвид, че различен израз може да реши проблема. Но ако трябваше да използвате динамичен SQL, бих го направил по този начин, вместо по начина, по който препоръчват в статията KB, най-важното за минимизиране на рисковете от инжектиране на SQL:DECLARE @date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), @sql NVARCHAR(MAX) = N'SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @date;'; EXEC sp_executesql @sql, N'@date DATE', @date;(И можете да добавите
OPTION (RECOMPILE)там, в зависимост от това как искате SQL Server да обработва подслушването на параметри.)Това води до същия план като по-ранната заявка, която не използва
DATEDIFF, с правилни оценки и 99,1% от разходите в търсенето на клъстерен индекс.Друг подход, който може да ви изкуши (и под вас имам предвид мен, когато за първи път започнах да разследвам) е да използвате променлива, за да изчислите стойността предварително:
DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
Проблемът с този подход е, че с променлива ще получите стабилен план, но кардиналността ще се основава на предположение (и видът на предположението ще зависи от наличието или отсъствието на статистика) . В този случай ето прогнозните спрямо действителните:
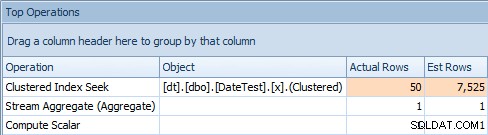
Раздел „Най-добри операции“ за заявка, която използва променливаТова очевидно не е правилно; изглежда SQL Server е предположил, че променливата ще съвпада с 50% от редовете в таблицата.
SQL Server 2014
Открих малко по-различен проблем в SQL Server 2014. Първите две заявки са фиксирани (чрез промени в оценителя на кардиналитета или други поправки), което означава, че DATEDIFF аргументите вече не се превключват. Ура!
Въпреки това, изглежда, че е въведена регресия в заобикалянето на използването на различен израз – сега той страда от неточна оценка (въз основа на същото 50% предположение като използването на променлива). Това са заявките, които изпълних:
SELECT /* 0, GETDATE() (2013) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0);
SELECT /* GETDATE(), 0 (1786) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
SELECT /* Non-DATEDIFF */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE());
SELECT /* Variable */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
DECLARE
@date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
@sql NVARCHAR(MAX) = N'SELECT /* Dynamic SQL */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = @date;';
EXEC sp_executesql @sql, N'@date DATE', @date; Ето таблицата на изявленията, сравняваща прогнозните разходи и действителните показатели по време на изпълнение:
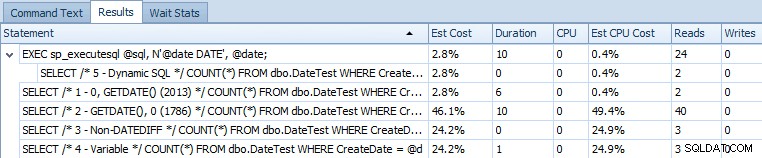
Прогнозни разходи за 5 заявки за екземпляри на SQL Server 2014
И това са техните прогнозни и действителни броя на редовете (сглобени с помощта на Photoshop):

Прогнозен и действителен брой редове за 5-те заявки в SQL Server 2014
От този изход става ясно, че изразът, който по-рано решаваше проблема, сега въвежда различен. Не съм сигурен дали това е симптом на работа в CTP (напр. нещо, което ще бъде поправено) или това наистина е регресия.
В този случай флагът за проследяване 4199 (самостоятелно) няма ефект; новият оценител на мощността прави предположения и просто не е правилен. Дали това води до действителен проблем с производителността зависи много от много други фактори извън обхвата на тази публикация.
Ако срещнете този проблем, можете – поне в текущите CTP – да възстановите старото поведение, като използвате OPTION (QUERYTRACEON 9481, QUERYTRACEON 4199) . Флаг за проследяване 9481 деактивира новия оценител на мощността, както е описано в тези бележки за изданието (което със сигурност ще изчезне или поне ще се премести в даден момент). Това от своя страна възстановява правилните оценки за не-DATEDIFF версия на заявката, но за съжаление все още не решава проблема, при който се прави предположение въз основа на променлива (и използването само на TF9481, без TF4199, принуждава първите две заявки да се върнат към старото поведение при размяна на аргументи).
Заключение
Признавам, че това беше голяма изненада за мен. Поздравления за Мартин Смит и t-clausen.dk, че упорстваха и ме убедиха, че това е реален, а не въображаем проблем. Също така голямо благодаря на Пол Уайт (@SQL_Kiwi), който ми помогна да запазя здравия си разум и ми напомни за нещата, които не бива да казвам. :-)
Тъй като не знаех за тази грешка, бях категоричен, че по-добрият план за заявка е генериран просто чрез промяна на текста на заявката изобщо, а не поради конкретната промяна. Както се оказва, понякога промяна в заявка, която предполагате няма да има разлика, всъщност ще има. Затова препоръчвам, ако имате подобни модели на заявки във вашата среда, да ги тествате и да се уверите, че оценките за кардиналност излизат правилно. И направете бележка, за да ги тествате отново, когато надстроите.