Разделянето на дялове е функция на SQL Server, която често се прилага за облекчаване на предизвикателствата, свързани с управляемостта, задачите за поддръжка или заключването и блокирането. Администрирането на големи таблици може да стане по-лесно с разделянето и може да подобри мащабируемостта и наличността. В допълнение, страничен продукт от разделянето може да бъде подобрена производителност на заявката. Това не е гаранция или даденост и не е движещата причина за внедряване на разделяне, но е нещо, което си струва да прегледате, когато разделяте голяма таблица.
Фон
Като бърз преглед, функцията за разделяне на SQL Server е налична само в Enterprise и Developer Editions. Разделянето може да бъде реализирано по време на първоначалното проектиране на база данни или може да бъде въведено на място, след като таблица вече има данни в нея. Разберете, че промяната на съществуваща таблица с данни в разделена таблица не винаги е бърза и проста, но е напълно осъществима с добро планиране и ползите могат бързо да бъдат реализирани.
Разделената таблица е тази, при която данните се разделят на по-малки физически структури въз основа на стойността за конкретна колона (наречена колона за разделяне, която е дефинирана във функцията за разделяне). Ако искате да разделите данните по години, можете да използвате колона, наречена DateSold като колона за разделяне и всички данни за 2013 г. ще се намират в една структура, всички данни за 2012 г. ще се намират в различна структура и т.н. Тези отделни набори от данни позволяват фокусирана поддръжка (можете да изградите отново само дял от индекс, а не целия индекс) и позволявате бързо добавяне и премахване на данни, тъй като те могат да бъдат поетапно предварително добавени или премахнати от таблицата.
Настройката
За да изследвам разликите в производителността на заявките за разделена спрямо неразделена таблица, създадох две копия на таблицата Sales.SalesOrderHeader от базата данни AdventureWorks2012. Неразделената таблица е създадена само с клъстериран индекс на SalesOrderID, традиционният първичен ключ за таблицата. Втората таблица беше разделена на OrderDate, с OrderDate и SalesOrderID като ключ за клъстериране и нямаше допълнителни индекси. Имайте предвид, че има много фактори, които трябва да имате предвид, когато решавате каква колона да използвате за разделяне. Разделянето често, но със сигурност не винаги, използва поле за дата за дефиниране на границите на дяла. Като такъв беше избран OrderDate за този пример и примерни заявки бяха използвани за симулиране на типична активност спрямо таблицата SalesOrderHeader. Изявленията за създаване и попълване на двете таблици могат да бъдат изтеглени тук.
След създаване на таблиците и добавяне на данни, съществуващите индекси бяха проверени и след това статистиката беше актуализирана с FULLSCAN:
EXEC sp_helpindex 'Sales.Big_SalesOrderHeader';GOEXEC sp_helpindex 'Sales.Part_SalesOrderHeader';GO АКТУАЛИЗИРАНЕ НА СТАТИСТИКАТА [Продажби].[Big_SalesOrderHeader] WITH FULLSCAN;GOUPDATE FULLSCAN;GOUPDATE FULLSTICAN;GOUPDATE FULLSTICAN;GOUPDATESALES; '.' + so.name AS [Таблица], ss.name AS [Статистика], sp.last_updated AS [Stats Last Updated], sp.rows AS [Редове], sp.rows_sampled AS [Извадка на редове], sp.modification_counter AS [Row Модификации]ОТ sys.stats КАТО ssINNER JOIN sys.objects AS so ON ss.[object_id] =so.[object_id]INNER JOIN sys.schemas КАТО sch ON so.[schema_id] =sch.[schema_id]ВЪНШНО ПРИЛОЖЕНИЕ sys.dm_db_stats_properties (so.[object_id], ss.stats_id) КАТО spWHERE so.[object_id] IN (OBJECT_ID(N'Sales.Big_SalesOrderHeader'), OBJECT_ID(N'Sales.Part_SalesOrderHeader'))AND ss.stats_id =1;Освен това и двете таблици имат точно същото разпределение на данните и минимална фрагментация.
Ефективност за обикновена заявка
Преди да бъдат добавени каквито и да било допълнителни индекси, към двете таблици беше изпълнена основна заявка за изчисляване на общите суми, спечелени от продавача за поръчки, направени през декември 2012 г.:
ИЗБЕРЕТЕ [SalesPersonID], SUM([TotalDue])FROM [Sales].[Big_SalesOrderHeader]WHERE [OrderDate] МЕЖДУ '2012-12-01' И '2012-12-31' ГРУПА ОТ [GOSELECTID]; [SalesPersonID], SUM([TotalDue])FROM [Sales].[Part_SalesOrderHeader]WHERE [OrderDate] МЕЖДУ '2012-12-01' И '2012-12-31'GROUP BY [SalesPersonID];GOСТАТИСТИЧЕСКИ ИЗХОД IOТаблица „Работна маса“. Брой на сканиране 0, логическо четене 0, физическо четене 0, четене напред 0, лобно логическо четене 0, лобно физическо четене 0, лобно четене напред чете 0.
Таблица 'Big_SalesOrderHeader'. Брой на сканиране 9, логически четения 2710440, физически четения 2226, четене напред 2658769, логически четения на лоб 0, физически четения на лоб 0, четене напред за четене 0.Таблица „Работна маса“. Брой на сканиране 0, логическо четене 0, физическо четене 0, четене напред за четене 0, лобно логическо четене 0, лобно физическо четене 0, лобно четене напред чете 0.
Таблица 'Part_SalesOrderHeader'. Брой сканирания 9, логически четения 248128, физически четения 3, четене напред 245030, логически четения на лоб 0, физически четения на лоб 0, четене напред за четене 0.
Общи суми по търговец за декември – таблица без дялове
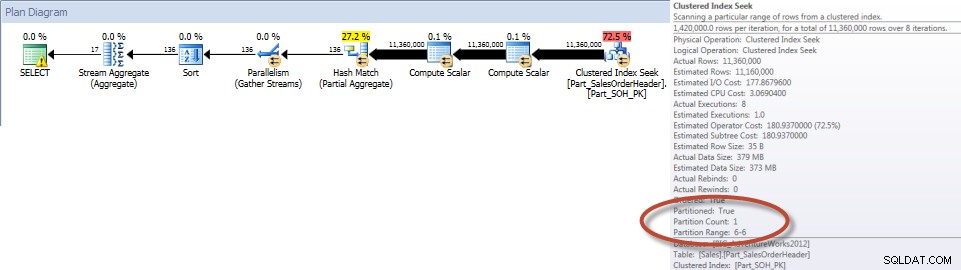
Общи суми по търговец за декември – разделена таблицаКакто се очакваше, заявката към неразделената таблица трябваше да извърши пълно сканиране на таблицата, тъй като нямаше индекс, който да я поддържа. За разлика от тях, заявката към разделената таблица е необходима само за достъп до един дял на таблицата.
За да бъдем честни, ако това беше заявка, изпълнявана многократно с различни периоди от време, би съществувал подходящият неклъстериран индекс. Например:
СЪЗДАЙТЕ НЕКЛУСТРИРАН ИНДЕКС [Big_SalesOrderHeader_SalesPersonID]ВЪВ [Продажби].[Big_SalesOrderHeader] ([OrderDate]) ВКЛЮЧЕТЕ ([SalesPersonID], [TotalDue]);С този създаден индекс, когато заявката се изпълни повторно, I/O статистиката пада и планът се променя, за да използва неклъстерирания индекс:
СТАТИСТИЧЕСКИ ИЗХОД IOТаблица „Работна маса“. Брой на сканиране 0, логическо четене 0, физическо четене 0, четене напред 0, лобно логическо четене 0, лобно физическо четене 0, лобно четене напред чете 0.
Таблица 'Big_SalesOrderHeader'. Брой на сканиране 9, логически четения 42901, физически четения 3, четене напред 42346, логически четения на лоб 0, физически четения на лоб 0, четене напред за четене 0.
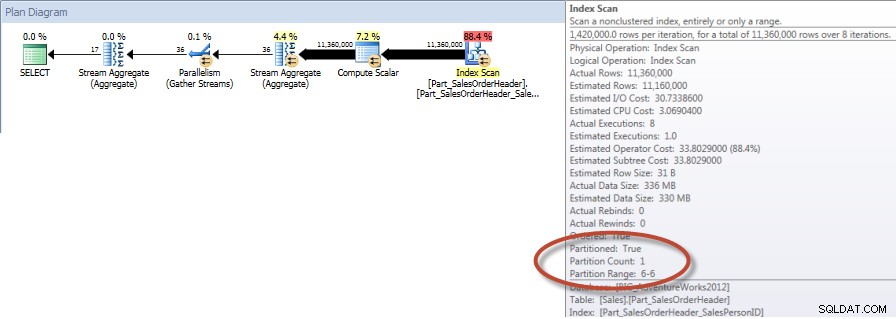
Общи суми по търговец за декември – NCI на таблица без дяловеС поддържащ индекс, заявката срещу Sales.Big_SalesOrderHeader изисква значително по-малко четения, отколкото сканирането на клъстерен индекс срещу Sales.Part_SalesOrderHeader, което не е неочаквано, тъй като клъстерираният индекс е много по-широк. Ако създадем сравним неклъстериран индекс за Sales.Part_SalesOrderHeader, ще видим подобни I/O номера:
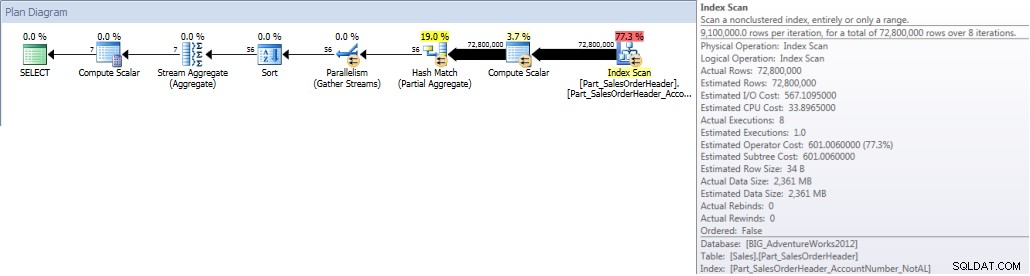
СЪЗДАЙТЕ НЕКЛУСТРИРАН ИНДЕКС [Part_SalesOrderHeader_SalesPersonID]ВЪВ [Продажби].[Part_SalesOrderHeader]([SalesPersonID]) ВКЛЮЧЕТЕ ([TotalDue]);СТАТИСТИЧЕСКИ ИЗХОД IOТаблица „Part_SalesOrderHeader“. Брой на сканиране 9, логически четения 42894, физически четения 1, четене напред 42378, логически четения на лоб 0, физически четения на лоб 0, четене напред за четене 0.
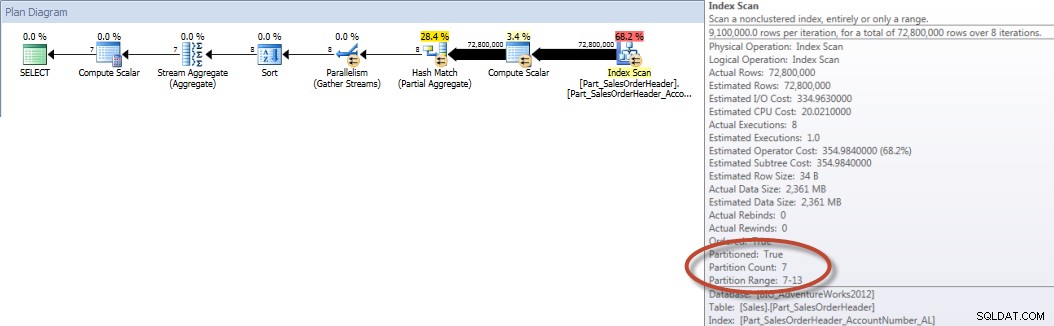
Общи суми от търговец за декември – NCI на разделена таблица с елиминиранеИ ако разгледаме свойствата на неклъстерираното индексно сканиране, можем да проверим дали машината е осъществила достъп само до един дял (6).
Както беше посочено първоначално, разделянето обикновено не се прилага за подобряване на производителността. В показания по-горе пример заявката към разделената таблица не работи значително по-добре, стига да съществува подходящият неклъстериран индекс.
Ефективност за Ad Hoc заявка
Заявка към разделената таблица може превъзхождат същата заявка спрямо неразделената таблица в някои случаи, например когато заявката трябва да използва клъстерирания индекс. Макар че е идеално по-голямата част от заявките да се поддържат от неклъстерирани индекси, някои системи позволяват ad hoc заявки от потребители, а други имат заявки, които може да се изпълняват толкова рядко, че не изискват поддържащи индекси. Срещу таблицата SalesOrderHeader потребителят може да изпълни следната заявка, за да намери поръчки от декември 2012 г., които трябва да бъдат изпратени до края на годината, но не, за определен набор от клиенти и с TotalDue по-голям от $1000:
SELECT[SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue]FROM [Sales].[Big_SalesWuHEREHeader]D. ]> 1000 И [CustomerID] МЕЖДУ 10 000 И 20 000 И [OrderDate] МЕЖДУ '2012-12-01' И '2012-12-31' И [DueDate] <'2012-12-12-31 Date> 2012-12-31' -31'; ИЗБЕРЕТЕ [SalesOrderID], [Дата на поръчката], [Дата на доставка], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue]FROM [Sales].[Part_SalesOrder]WHERE. [TotalDue]> 1000 И [CustomerID] МЕЖДУ 10000 И 20000 И [OrderDate] МЕЖДУ '2012-12-01' И '2012-12-31' И [DueDate] <'2012-3h' и 12 [DueDate] -12-31';GOСТАТИСТИЧЕСКИ ИЗХОД IOТаблица 'Big_SalesOrderHeader'. Брой на сканиране 9, логически четения 2711220, физически четения 8386, четене напред 2662400, логически четения на лоб 0, физически четения на лоб 0, четене напред за четене 0.
Таблица 'Part_SalesOrderHeader'. Брой на сканиране 9, логически четения 248128, физически четения 0, четене напред 243792, логически четения на лоб 0, физически четения на лоб 0, четене напред за четене 0.
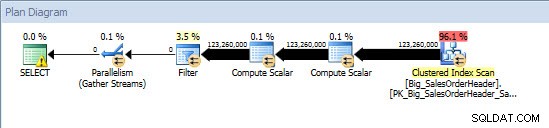
Ad-Hoc заявка – неразделена таблица
Ad-Hoc заявка – разделена таблицаСрещу неразделената таблица заявката изисква пълно сканиране спрямо клъстерирания индекс, но срещу разделената таблица, заявката извършва търсене на индекс на клъстерирания индекс, тъй като машината използва елиминиране на дял и чете само данните, от които е абсолютно необходим. В този пример това е значителна разлика по отношение на I/O и в зависимост от хардуера може да бъде драматична разлика във времето за изпълнение. Заявката може да бъде оптимизирана чрез добавяне на подходящия индекс, но обикновено не е възможно да се индексира за всеки единична запитване. По-специално, за решения, които позволяват ad hoc заявки, е справедливо да се каже, че никога не знаете какво ще направят потребителите. Една заявка може да се изпълни веднъж и никога повече, а създаването на индекс след факта е безполезно. Следователно, когато преминавате от таблица без дялове към таблица с дялове, е важно да приложите същите усилия и подход като обикновената настройка на индекса; искате да проверите дали съществуват подходящите индекси, за да поддържат повечето заявки.
Изпълнение и подравняване на индекса
Допълнителен фактор, който трябва да се вземе предвид при създаване на индекси за разделена таблица, е дали да се подравни индексът или не. Индексите трябва да бъдат подравнени с таблицата, ако планирате да превключвате данни в и извън дялове. Създаването на неклъстериран индекс върху разделена таблица създава подравнен индекс по подразбиране, където колоната за разделяне се добавя като включена колона към индекса.
Неподравнен индекс се създава чрез посочване на различна схема на дялове или различна файлова група. Колоната за разделяне може да бъде част от индекса като ключова колона или включена колона, но ако не се използва схемата на разделяне на таблицата или се използва различна файлова група, индексът няма да бъде подравнен.
Подравненият индекс се разделя точно като таблицата – данните ще съществуват в отделни структури – и следователно може да се случи елиминиране на дял. Неподравнен индекс съществува като една физическа структура и може да не осигури очакваната полза за заявка, в зависимост от предиката. Помислете за заявка, която отброява продажбите по номер на сметката, групирана по месеци:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber])FROM [Sales].[Part_SalesOrderHeader]КЪДЕ [OrderDate] МЕЖДУ '2013-01-01' И '2013-07-31'ГРУПА ПО ДАТА (МЕСЕЦ,[Дата на поръчката])ПОРЪЧКА ПО ЧАСТ ДАТА(МЕСЕЦ,[Дата на поръчка]);Ако не сте толкова запознати с разделянето на дялове, можете да създадете индекс като този, за да поддържате заявката (обърнете внимание, че е посочена ОСНОВНАТА файлова група):
СЪЗДАВАНЕ НА НЕКЛУСТРИРАН ИНДЕКС [Part_SalesOrderHeader_AccountNumber_NotAL]ВКЛ. [Продажби].[Part_SalesOrderHeader]([AccountNumber])ВКЛ. [ОСНОВЕН];Този индекс не е подравнен, въпреки че включва OrderDate, защото е част от първичния ключ. Колоните също са включени, ако създадем подравнен индекс, но обърнете внимание на разликата в синтаксиса:
СЪЗДАЙТЕ НЕКЛУСТРИРАН ИНДЕКС [Part_SalesOrderHeader_AccountNumber_AL]ВЪВ [Продажби].[Part_SalesOrderHeader]([AccountNumber]);Можем да проверим какви колони съществуват в индекса с помощта на sp_helpindex на Кимбърли Трип:
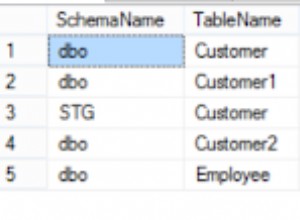
EXEC sp_SQLskills_SQL2008_helpindex 'Sales.Part_SalesOrderHeader';
sp_helpindex за Sales.Part_SalesOrderHeaderКогато стартираме нашата заявка и я принудим да използва неподравнения индекс, целият индекс се сканира. Въпреки че OrderDate е част от индекса, тя не е водещата колона, така че машината трябва да провери стойността на OrderDate за всеки AccountNumber, за да види дали попада между 1 януари 2013 г. и 31 юли 2013 г.:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber])FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_NotAL]))WHERE [OrderDate'1-1'0'3 МЕЖДУ МЕЖДУ 01'0'0'3. 2013-07-31'ГРУПА ПО ЧАСТ ДАТА(МЕСЕЦ,[Дата на поръчката])ПОРЪЧКА ПО ЧАСТ ДАТА(МЕСЕЦ,[Дата на поръчката]);СТАТИСТИЧЕСКИ ИЗХОД IOТаблица „Работна маса“. Брой на сканиране 0, логическо четене 0, физическо четене 0, четене напред за четене 0, лобно логическо четене 0, лобно физическо четене 0, лобно четене напред чете 0.
Таблица 'Part_SalesOrderHeader'. Брой на сканиране 9, логически четения 786861, физически четения 1, четене напред 770929, логически четения на лоб 0, физически четения на лоб 0, четене напред за четене 0.
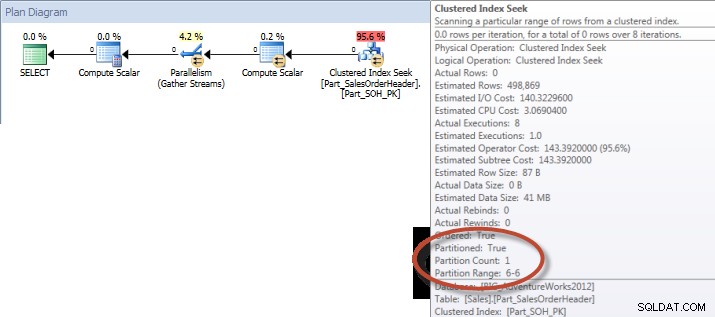
Общи суми на акаунта по месеци (януари – юли 2013 г.) с използване на не- Подравнен NCI (принудително)За разлика от това, когато заявката е принудена да използва подравнения индекс, може да се използва елиминиране на дял и са необходими по-малко I/O, въпреки че OrderDate не е водеща колона в индекса.
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber])FROM [Sales].[Part_SalesOrderHeader] WITH([Part_SalesOrderHeader_AccountNumber_AL]))WHERE [OrderDate] 013-'0'1 МЕЖДУ 013'-'1 '1 2013-07-31'ГРУПА ПО ЧАСТ ДАТА(МЕСЕЦ,[Дата на поръчката])ПОРЪЧКА ПО ЧАСТ ДАТА(МЕСЕЦ,[Дата на поръчката]);СТАТИСТИЧЕСКИ ИЗХОД IOТаблица „Работна маса“. Брой на сканиране 0, логическо четене 0, физическо четене 0, четене напред за четене 0, лобно логическо четене 0, лобно физическо четене 0, лобно четене напред чете 0.
Таблица 'Part_SalesOrderHeader'. Брой сканиране 9, логически четения 456258, физически четения 16, четене напред 453241, лобно логическо четене 0, лобно физическо четене 0, четене напред за четене 0.
Общи суми на акаунта по месеци (януари – юли 2013 г.) с помощта на Aligned NCI (принудително)Резюме
Решението за прилагане на разделяне е такова, което изисква надлежно разглеждане и планиране. Лесното управление, подобрената мащабируемост и наличност, както и намаляването на блокирането са често срещани причини за таблиците на дялове. Подобряването на производителността на заявките не е причина да се използва разделяне, въпреки че в някои случаи може да бъде полезен страничен ефект. По отношение на производителността е важно да гарантирате, че вашият план за внедряване включва преглед на ефективността на заявката. Уверете се, че вашите индекси продължават да поддържат по подходящ начин вашите заявки след таблицата е разделена и се уверете, че заявките, използващи клъстерираните и неклъстерираните индекси, се възползват от елиминирането на дял, където е приложимо.