В тази ера на тежка конкуренция порталите за работа не са просто платформи за публикуване и намиране на работа. Те използват модерни услуги и функции, за да поддържат ангажираността на своите клиенти. Нека се потопим в някои разширени функции и да изградим модел на данни, който може да се справи с тях.
Обясних основните функции, необходими за уебсайт на портал за работа в предишна статия. Моделът е показан по-долу. Ще разглеждаме този модел като база, която ще променим, за да отговорим на новите изисквания. Първо, нека помислим какви трябва да бъдат тези изисквания (или подобрения).
Какво добавяме към модела на данни на онлайн портала за работа?
Накратко, ще добавим четири подобрения към предишния ни модел на данни:
- Лично табло за управление за търсещи работа. Това проследява всички техни молби за работа и предоставя актуализации в реално време за всякакви промени в статуса (т.е. заявлението се променя от получено към преглед).
- Табло за управление на профил. Това описва кой посещава профила на търсещия работа и колко пъти е изтеглена автобиографията им през последния ден, седмица или месец.
- Управление на платени услуги. Порталите за работа често предлагат услуги като подготовка на експертна автобиография, управление на социални профили, кариерни консултации и др. Новите ни функции ще могат да поддържат предложения срещу заплащане.
- Управление на формуляра за предварително кандидатстване. Когато кандидатите подават заявление за работа, може да бъдат помолени да попълнят кратък въпросник, свързан с работното време, местоположенията и проверките на миналото. Ще изградим начини, по които този формуляр да бъде персонализиран от наемателите и въпросите и отговорите да бъдат уловени от системата.
Подобрение № 1:Лично табло за управление
Въпроси за отговор: Какво е текущото състояние на подадено заявление? Включен ли е в краткия списък за интервю? Изгледан ли е вече?
Можем да следим заявленията за работа, като поставим job_application_status_id колона в job_post_activity маса. Тази колона съдържа текущото състояние на заявление за работа. Трябва да създадем друга таблица, job_application_status , за да запази всички възможни състояния на приложението. Някои статуси може да са „изпратени“, „в процес на проверка“, „архивирани“, „отхвърлени“, „включени в списъка за интервю“, „в процес на набиране“ и т.н.
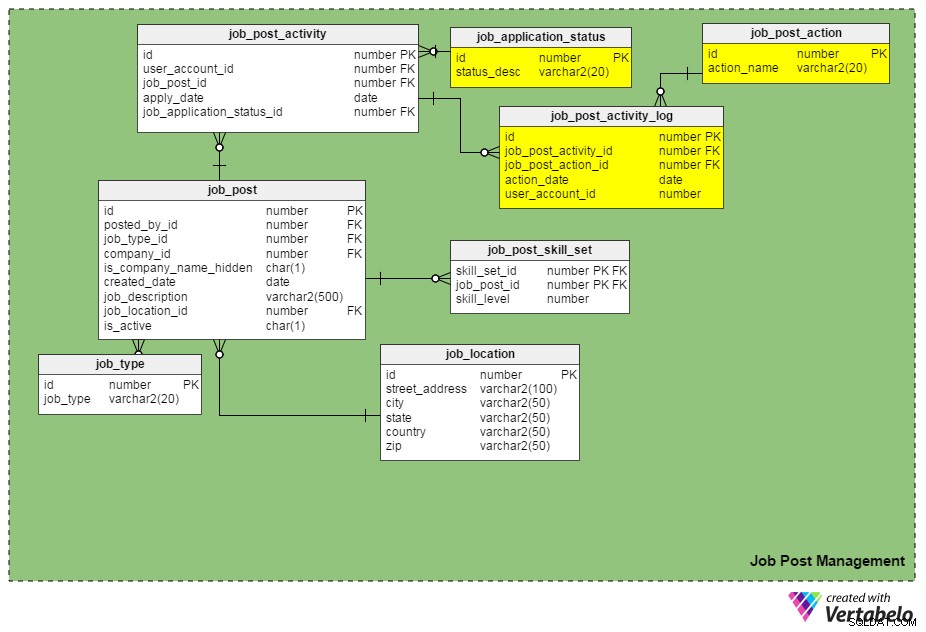
Друга нова таблица, job_post_activity_log , съхранява информация относно всички извършени действия по заявленията за работа, кой е извършил действието и кога е извършено. Тази таблица съдържа следните колони:
id– Първичният ключ на таблицата.job_post_activity_id– Идентификационният номер на приложението, върху който се извършва действието.job_post_action_id– ИД на извършеното действие. Това е външен ключ, който се свързва сjob_post_actionмаса. Типовете действия, които можем да съхраняваме тук, включват „изпратено“, „прегледано“, „разпитано“, „приет е писмен тест“, „оферта е в процес“, „оферта е изпратена“, „офертата е приета“ и т.н.action_date– Датата, на която е извършено действие.user_account_id– ИД на лицето, извършило действието.
Идентично ли е „job_post_action“ на „job_application_status“? С какво се различават?
На пръв поглед изглеждат еднакви, но наистина са различни. Има основателни причини, поради които се нуждаем от две подобни полета:
- Кандидат се интервюира от двама или повече души поотделно. В този случай статусът на кандидатурата за работа остава същият (т.е. „в процес на набиране на персонал“), докато приключат всички кръгове на интервюто. Въпреки това, записите за всеки отделен интервюиращ се вмъкват в
job_post_activity_logтаблица и те са „разпитани“. - Едно приложение може да бъде разгледано от повече от един работодател в една и съща компания. Използвайки тези два атрибута, няма да загубите информацията на кандидата.
- Отправянето на оферта към избран кандидат подлежи на многократни одобрения (т.е. одобрение от финансов екип, одобрение от ръководителя на отдела за наемане и т.н.). В този случай състоянието на заявлението за работа остава „оферта в процес на преглед“, но базата данни може да регистрира кои одобрения са преминали и кои не чрез
job_post_activity_logмаса.
Подобрение № 2:Табло за управление на профил
Въпроси за отговор: Кой наскоро намери моя профил? Колко пъти е бил гледан от наемателите през последния месец, седмица или ден? Набиращите персонал от водещи компании гледаха ли профила ми?
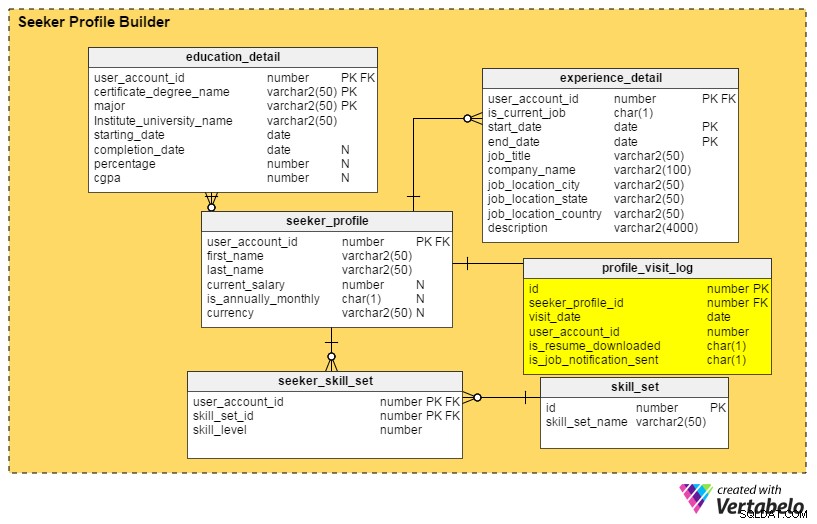
Отговорите на всички тези въпроси са в profile_visit_log маса. Тази таблица улавя всички данни за посещенията на профила, включително кой е посетил профил, кога е бил прегледан и т.н. Колоните в тази таблица са:
id– Първичният ключ на таблицата.seeker_profile_id– Кой профил е посетен.visit_date– Когато профилът е бил достъпен.user_account_id– Кой е видял профила.is_resume_downloaded– Колона с флаг, която обозначава дали свързаната автобиография е била изтеглена по време на посещението. Тази колона ще ни помогне да определим колко пъти е изтеглена автобиография от наемателите.is_job_notification_sent– Друга колона за флаг, в която се посочва дали е изпратено известие за работа до собственика на профила.
Подобрение № 3:Управление на платени услуги
Въпрос на отговор: Как онлайн порталите могат да използват допълнителни услуги срещу заплащане?
Освен платформа за публикуване и търсене на работа, много онлайн портали предоставят и други услуги, като съставяне на експертна автобиография, кариерно консултиране и т.н. Те също така предлагат продукти, които да помогнат на търсещите работа да намерят мечтаната работа в мечтания град. Например, един от водещите сайтове за работа предлага продукт, който поддържа вашия профил в горната част на списъците на наемателите, така че можете да получите повече оферти за интервюта. Повечето от тези продукти или услуги се предлагат на база абонамент. Когато потребител закупи услуга или продукт, той плаща за определен период от време (т.е. месец, три месеца, една година) за използването на този продукт или услуга.
Докато разглеждах тези портали за работа, забелязах, че почти не се предлагат продукти или услуги поотделно. В по-голямата си част множество продукти и услуги са обединени в пакет и този пакет се предлага както на търсещите работа, така и на наемателите.
Като вземам предвид всички тези точки, измислих следния модел на данни за включване на платени услуги и продукти в съществуващия ни онлайн сайт за работа:
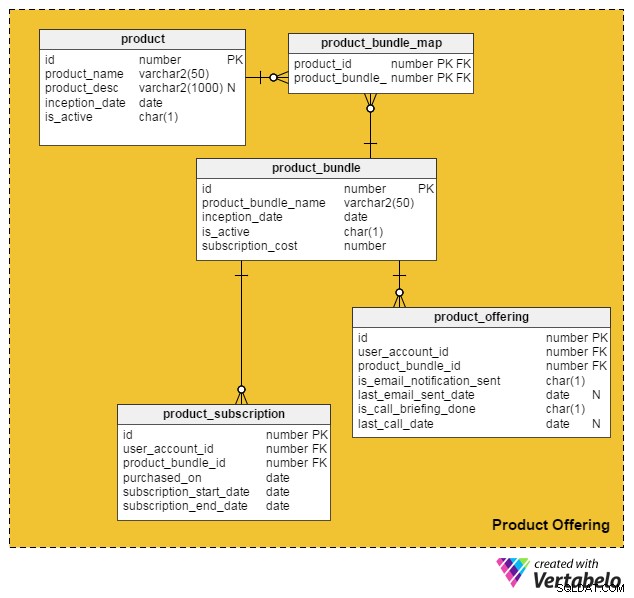
product таблицата съдържа подробности за отделните продукти. (Ще наричаме продуктите и услугите „продукти“). Колоните в тази таблица са:
id– Първичният ключ на тази таблица, който дава уникален идентификатор на всеки продукт, предлаган на нашия портал.product_name– Съдържа името на продукта.product_desc– Съхранява кратко описание на продукта.inception_date– Датата на представяне на продукта.is_active– Независимо дали даден продукт е активен или не.
Тъй като продуктите и услугите могат да бъдат обединени в пакет и да се предлагат на клиентите, създадох product_bundle таблица за съхраняване на записи за всички такива пакети. Атрибутите са:
id– Първичният ключ на таблицата, който предоставя уникален идентификатор за всеки пакет продукти.product_bundle_name– Съхранява името на пакета.inception_date– Датата на въвеждане на пакета.is_active– Означава дали пакетът е активен или не.subscription_cost– Съхранява исканата цена за пакета.
Може ли един продукт да се предлага на клиентите?
да. В този модел на данни един продукт може да бъде свой собствен „пакет“. Следващите таблици се справят с тази и някои други важни функции.
product_bundle_map таблицата съхранява списък на всички продукти, които са част от пакет. Неговите атрибути се разбират сами.
Следващата таблица, product_subscription , влиза в действие, когато клиентите се абонират за продуктови пакети. Той записва подробностите за това кои клиенти са записали към кои пакети. Колоните в тази таблица са:
id– Първичният ключ на таблицата.user_account_id– Потребителят, закупил пакета.product_bundle_id– Пакетът с продукти, закупен от потребителя.purchased_on– Датата на покупка.subscription_start_date– Датата, на която започва абонамента. Имайте предвид, че датата на закупуване на продукта и началната дата на абонамента може да се различават. По този начин имаме две различни колони за тях.subscription_end_date– Кога ще приключи абонаментът.
Финалната таблица, product_offering , се използва основно за маркетинг. Обикновено порталите за работа анализират последните дейности на потребителите (както търсещите работа, така и тези, които набират персонал) и след това решават кои продукти ще бъдат полезни за кои потребители. След това използват имейли или телефонни обаждания, за да се свържат с клиенти с избрани предложения. Колоните за тази таблица са:
id– Първичният ключ на таблицата.user_account_id– Потребителят, към когото е насочен порталът за работа.product_bundle_id– Пакетът от продукти, който маркетолозите на портала са съпоставили с потребителя.is_email_notification_sent– Дали е изпратен имейл относно предлагането на продукта.last_email_sent_date– Кога потребителят за последен път е получил продуктов имейл от маркетинговия екип. Обичайно е търговците да изпращат множество известия до потребител и периодично да изпращат други известия. Тази колона съхранява датата, на която е изпратено последното известие.is_call_briefing_done– Дали клиентът е получил телефонно обаждане, което го е информирало за даден продукт.last_call_date– Датата на последното телефонно обаждане. Може да има множество обаждания (последващи обаждания) към клиенти.
Подобрение № 4:Управление на формуляра преди кандидатстване
Въпрос на отговор: Как може един наемател да получи персонализиран формуляр за съгласие, попълнен от всички потенциални кандидати за работа?
Много пъти търсещите работа отговарят на конкретни въпроси, докато кандидатстват за пост. Това обикновено включва неща като съгласие за проверка на криминално минало. Съществуват обаче различни други видове съгласия, които може да са необходими. Например, работа в областта на маркетинга може да изисква много пътувания; работни места в аутсорсинг на бизнес процеси (BPO) може да изискват служителите да работят на смени в гробището (т.е. късно през нощта). Те са разгледани във формуляри за предварително кандидатстване.
Винаги е най-добре да получите съгласие при подаване на заявлението за работа. По този начин кандидатите, които не желаят да изпълнят тези изисквания, няма да кандидатстват за работата.
Преди да преминем към модела на данни, нека първо да подчертая някои основни факти за формулярите за съгласие:
- Обява за работа може да има повече от един формуляр за съгласие.
- Всеки формуляр за съгласие има различни въпроси, свързани с различни раздели.
- Въпросът може да бъде зададен като задължителен или незадължителен, в зависимост от това как е маркиран въпросът във формуляра. Въпросът може да бъде незадължителен в една форма и задължителен в друга.
- На всеки въпрос може да се отговори като (1) да, (2) не или (3) неприложимо.
- Всички отговори ще бъдат записани.
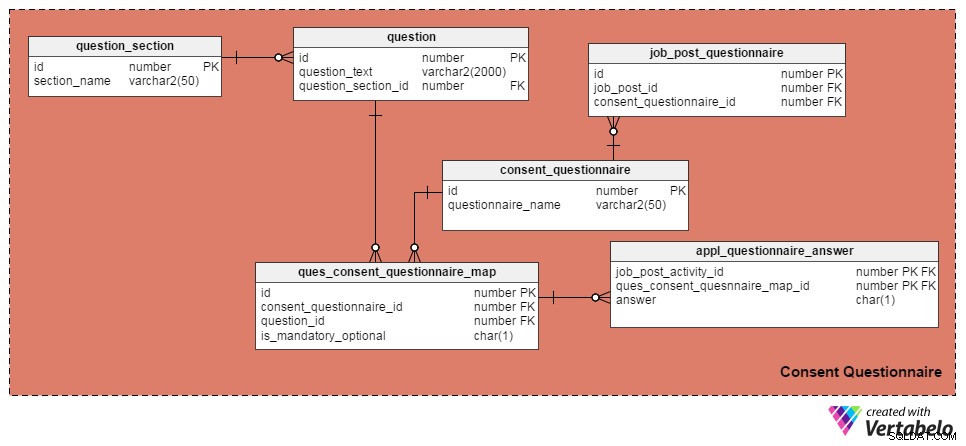
Използвах следните четири таблици за управление на въпроси и формуляри за съгласие. Първият, question таблица, съдържа списък с въпроси. Той има следните атрибути:
id– Първичният ключ на таблицата, който дава уникален идентификационен номер на всеки въпрос.question_text– Съхранява действителния текст на въпроса.question_section_id– Разделът, в който се появява въпросът. (Напр. „Работили ли сте в разработката на софтуер поне пет години?“ ще се появи в секцията „Работен опит“.) Това е колона с външен ключ, която се препраща отquestion_sectionмаса.
question_section таблицата съхранява информация за разделите. Това е начин за групиране на въпроси, свързани с една и съща тема. Освен id атрибут, който е първичен ключ за таблицата, единственият атрибут е section_name , което се разбира от само себе си.
consent_questionnaire таблицата съдържа имена на формуляри за съгласие. Двата му атрибута също са разбираеми.
ques_consent_questionnaire_map таблицата е ядрото на тази предметна област. Всички останали таблици в тази предметна област са пряко или косвено свързани с нея. Целта му е да поддържа списък с въпроси, маркирани към формуляри за съгласие. Колоните в тази таблица са:
id– Първичният ключ на тази таблица.consent_questionnaire_id– Идентификационният номер на формуляра за съгласие.question_id– Идентификационният номер на въпроса.is_mandatory_optional– Означава дали въпросът е задължителен или незадължителен за даден формуляр за съгласие. Въпросът може да бъде част от множество формуляри за съгласие, но може да бъде задължителен в някои и по избор в други. Това е единствената причина да запазите тази колона тук, вместо да я има вquestionмаса.
В следващите няколко таблици ще обсъдим маркирането на формуляри за съгласие към отделни обяви за работа и записване на отговорите на кандидатите. Нека започнем с job_post_questionnaire таблица, която съхранява информация за това кои формуляри за съгласие са част от обява за работа. Може да има един или повече формуляри за съгласие, маркирани с обява за работа. Колоните в тази таблица са:
id– Първичен ключ на таблицата.job_post_id– Означава коя длъжност е маркирана във формуляра за съгласие.consent_questionnaire_id– Формулярът за съгласие, маркиран към обява за работа.
След това appl_questionnaire_answer таблицата записва индивидуалните отговори на всеки въпрос от формуляра за съгласие, попълнен от кандидатите. Колоните в тази таблица са:
job_post_activity_id– Колона с външен ключ, препратка отjob_post_activityмаса. Той съхранява информация за кандидата, който е отговорил на въпроса.quest_consent_quesnnaire_map_id– Друга колона за външен ключ, посочена отquest_consent_questionnaire_mapмаса. Той съхранява на кой въпрос от кой формуляр за съгласие се отговаря.answer– Действителният отговор на кандидата за работа. Запазих го като колона CHAR(1), защото на всички въпроси в нашия модел може да се отговори като „Да“ (отговор =„Y“), „Не“ (отговор =„N“) или „Неприложимо“ (отговор =„X“).
Новият и подобрен онлайн модел на данни на портала за работа
Можете да видите завършения модел на данни по-долу.
Какво бихте добавили?
Сещате ли се за други функции, които да добавите към нашия онлайн портал за работа? Моля, споделете вашите мнения в секцията за коментари.