Вероятно сте правили някои от тези грешки, когато започвахте кариерата си в областта на дизайна на база данни. Може би все още ги правите или ще направите някои в бъдеще. Не можем да се върнем назад във времето и да ви помогнем да отмените грешките си, но можем да ви спасим от някои бъдещи (или настоящи) главоболия.
Четенето на тази статия може да ви спести много часове, прекарани в отстраняване на проблеми с дизайна и кода, така че нека се потопим. Разделих списъка с грешки на две основни групи:тези, които са нетехнически в природата и такива, които са строго технически . И двете групи са важна част от дизайна на база данни.
Очевидно, ако нямате технически умения, няма да знаете как да направите нещо. Не е изненадващо да видите тези грешки в списъка. Но нетехнически умения? Хората може да забравят за тях, но тези умения също са много важна част от процеса на проектиране. Те добавят стойност към вашия код и свързват технологията с реалния проблем, който трябва да решите.
И така, нека започнем първо с нетехническите проблеми, след което преминем към техническите.
Нетехнически грешки при проектирането на база данни
#1 Лошо планиране
Това определено е нетехнически проблем, но е основен и често срещан проблем. Всички се вълнуваме, когато стартира нов проект и като влезем в него, всичко изглежда страхотно. В началото проектът все още е празна страница и вие и вашият клиент сте щастливи да започнете да работите върху нещо, което ще създаде по-добро бъдеще и за двама ви. Всичко това е страхотно и вероятно крайният резултат ще бъде страхотно бъдеще. Но все пак трябва да останем фокусирани. Това е частта от проекта, в която можем да направим съществени грешки.
Преди да седнете да нарисувате модел на данни, трябва да сте сигурни, че:
- Вие сте напълно наясно какво прави вашият клиент (т.е. бизнес плановете им, свързани с този проект, както и цялостната им картина) и какво искат да постигне този проект сега и в бъдеще.
- Разбирате бизнес процеса и, ако или когато е необходимо, сте готови да направите предложения за опростяването и подобряването му (напр. за увеличаване на ефективността и приходите, намаляване на разходите и работното време и т.н.).
- Разбирате потока от данни в компанията на клиента. В идеалния случай бихте знаели всеки детайл:кой работи с данните, кой прави промени, кои отчети са необходими, кога и защо се случва всичко това.
- Можете да използвате езика/терминологията, които вашият клиент използва. Въпреки че може и да не сте експерт в тяхната област, вашият клиент определено е такъв. Помолете ги да обяснят това, което не разбирате. И когато обяснявате технически подробности на клиента, използвайте език и терминология, които те разбират.
- Знаете кои технологии ще използвате, от базата данни и езиците за програмиране до други инструменти. Това, което решите да използвате, е тясно свързано с проблема, който ще разрешите, но е важно да включите предпочитанията на клиента и текущата им ИТ инфраструктура.
По време на фазата на планиране трябва да получите отговори на следните въпроси:
- Кои таблици ще бъдат централните маси във вашия модел? Вероятно ще имате няколко от тях, докато другите таблици ще бъдат някои от обичайните (напр. user_account, role). Не забравяйте за речниците и връзките между таблиците.
- Какви имена ще се използват за таблици в модела? Не забравяйте да запазите терминологията подобна на тази, която клиентът използва в момента.
- Какви правила ще се прилагат при именуване на таблици и други обекти? (Вижте точка 4 относно конвенциите за именуване.)
- Колко време ще отнеме целият проект? Това е важно както за графика ви, така и за времевата линия на клиента.
Едва когато имате всички тези отговори, сте готови да споделите първоначално решение на проблема. Това решение не е необходимо да бъде цялостно приложение – може би кратък документ или дори няколко изречения на езика на бизнеса на клиента.
Доброто планиране не е специфично за моделирането на данни; той е приложим за почти всеки ИТ (и не-ИТ) проект. Пропускането е само опция, ако 1) имате наистина малък проект; 2) задачите и целите са ясни и 3) много бързате. Исторически пример е инженерите по изстрелването на Спутник 1, които дават устни инструкции на техниците, които го сглобяват. Проектът беше забързан заради новината, че САЩ планират скоро да изстрелят свой собствен сателит – но предполагам, че няма да бързате толкова.
#2 Недостатъчна комуникация с клиенти и разработчици
Когато започнете процеса на проектиране на база данни, вероятно ще разберете повечето от основните изисквания. Някои са много чести, независимо от бизнеса, напр. потребителски роли и статуси. От друга страна, някои таблици във вашия модел ще бъдат доста специфични. Например, ако създавате модел за таксиметрова компания, ще имате таблици за превозни средства, шофьори, клиенти и т.н.
Все пак не всичко ще бъде очевидно в началото на проекта. Може да сте разбрали погрешно някои изисквания, клиентът може да добави някои нови функционалности, ще видите нещо, което може да се направи по различен начин, процесът може да се промени и т.н. Всичко това причинява промени в модела. Повечето промени изискват добавяне на нови таблици, но понякога ще премахвате или променяте таблици. Ако вече сте започнали да пишете код, който използва тези таблици, ще трябва да пренапишете и този код.
За да намалите времето, прекарано за неочаквани промени, трябва:
- Говорете с разработчици и клиенти и не се страхувайте да задавате важни бизнес въпроси. Когато смятате, че сте готови да започнете, запитайте се Покрита ли е ситуация X в нашата база данни? Клиентът в момента прави Y по този начин; очакваме ли промяна в близко бъдеще? След като сме сигурни, че нашият модел има способността да съхранява всичко необходимо по правилния начин, можем да започнем да кодираме.
- Ако сте изправени пред значителна промяна в дизайна си и вече имате написан много код, не бива да се опитвате да го коригирате. Направете го така, както е трябвало да бъде направено, независимо от текущата ситуация. Бързата корекция може да спести известно време сега и вероятно ще работи добре известно време, но по-късно може да се превърне в истински кошмар.
- Ако смятате, че нещо е наред сега, но може да стане проблем по-късно, не го пренебрегвайте. Анализирайте тази област и внесете промени, ако те ще подобрят качеството и производителността на системата. Това ще струва известно време, но ще доставите по-добър продукт и ще спите много по-добре.
Ако се опитате да избегнете промени в модела си на данни, когато видите потенциален проблем – или ако изберете бързо решение, вместо да го правите правилно – ще платите за това рано или късно.
Освен това поддържайте връзка с вашия клиент и разработчиците по време на целия проект. Винаги проверявайте и вижте дали са направени промени след последната ви дискусия.
#3 Лоша или липсваща документация
За повечето от нас документацията идва в края на проекта. Ако сме добре организирани, вероятно сме документирали нещата по пътя и ще трябва само да приключим всичко. Но честно казано, това обикновено не е така. Писането на документация се случва точно преди затварянето на проекта - и точно след като умствено приключим с този модел на данни!
Цената, платена за лошо документиран проект, може да бъде доста висока, няколко пъти по-висока от цената, която плащаме, за да документираме правилно всичко. Представете си, че намирате грешка няколко месеца след като сте затворили проекта. Тъй като не сте документирали правилно, не знаете откъде да започнете.
Докато работите, не забравяйте да пишете коментари. Обяснете всичко, което се нуждае от допълнително обяснение, и по принцип запишете всичко, което смятате, че ще бъде полезно един ден. Никога не знаете дали и кога ще имате нужда от тази допълнителна информация.
Технически грешки при проектирането на база данни
#4 Не се използва конвенция за именуване
Никога не знаете със сигурност колко дълго ще продължи един проект и дали ще имате повече от един човек, работещ върху модела на данни. Има момент, когато сте наистина близо до модела на данни, но все още не сте започнали да го рисувате. Тогава е разумно да решите как ще наименувате обектите във вашия модел, в базата данни и в общото приложение. Преди да моделирате, трябва да знаете:
- Имената на таблици единствено или множествено число ли са?
- Ще групираме ли таблици по имена? (Напр. всички таблици, свързани с клиента, съдържат „client_“, всички таблици, свързани със задачи, съдържат „task_“ и т.н.)
- Ще използваме ли главни и малки букви или само малки?
- Какво име ще използваме за идентификационните колони? (Най-вероятно ще бъде „id“.)
- Как ще именуваме външни ключове? (Най-вероятно „id_“ и името на посочената таблица.)
Сравнете част от модел, който не използва конвенции за именуване, със същата част, която използва конвенции за именуване, както е показано по-долу:
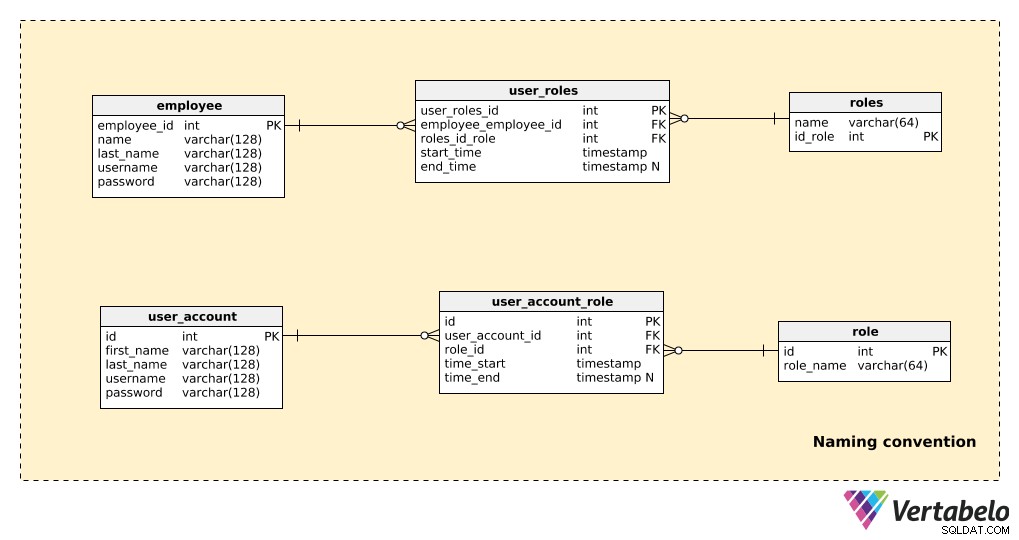
Тук има само няколко таблици, но все пак е доста очевидно кой модел е по-лесен за четене. Забележете, че:
- И двата модела „работят“, така че няма проблеми от техническа страна.
- В примера за неименуване на конвенцията (горните три таблици) има няколко неща, които значително влияят върху четливостта:използване на форми за единствено и множествено число в имената на таблиците; нестандартизирани имена на първичен ключ (
employees_id,id_role); и атрибутите в различни таблици споделят едно и също име (напр. името се появява и в двете „employee” и „roles” таблици).
Сега си представете бъркотията, която бихме създали, ако нашият модел съдържа стотици таблици. Може би бихме могли да работим с такъв модел (ако го създадохме сами), но бихме направили някой много нещастен, ако трябва да работи по него след нас.
За да избегнете бъдещи проблеми с имената, не използвайте запазени в SQL думи, специални знаци или интервали в тях.
Така че, преди да започнете да създавате имена, направете прост документ (може би само няколко страници), който описва конвенцията за именуване, която сте използвали. Това ще увеличи четливостта на целия модел и ще опрости бъдещата работа.
Можете да прочетете повече за конвенциите за именуване в тези две статии:
- Конвенции за именуване в моделирането на бази данни
- Неемоционален логически поглед към конвенциите за именуване на SQL Server
#5 Проблеми с нормализирането
Нормализирането е съществена част от дизайна на базата данни. Всяка база данни трябва да бъде нормализирана до поне 3NF (дефинирани са първичните ключове, колоните са атомарни и няма повтарящи се групи, частични зависимости или преходни зависимости). Това намалява дублирането на данни и гарантира референтната цялост.
Можете да прочетете повече за нормализирането в тази статия. Накратко, когато говорим за модела на релационна база данни, ние говорим за нормализирана база данни. Ако база данни не е нормализирана, ще се сблъскаме с куп проблеми, свързани с целостта на данните.
В някои случаи може да искаме да денормализираме нашата база данни. Ако направите това, имайте наистина добра причина. Можете да прочетете повече за денормализирането на базата данни тук.
#6 Използване на модела Entity-Attribute-Value (EAV)
EAV означава стойност на обект-атрибут. Тази структура може да се използва за съхраняване на допълнителни данни за всичко в нашия модел. Нека да разгледаме един пример.
Да предположим, че искаме да съхраним някои допълнителни атрибути на клиента. „customer ” таблицата е нашият обект, „attribute ” очевидно е нашият атрибут, а „attribute_value ” таблицата съдържа стойността на този атрибут за този клиент.
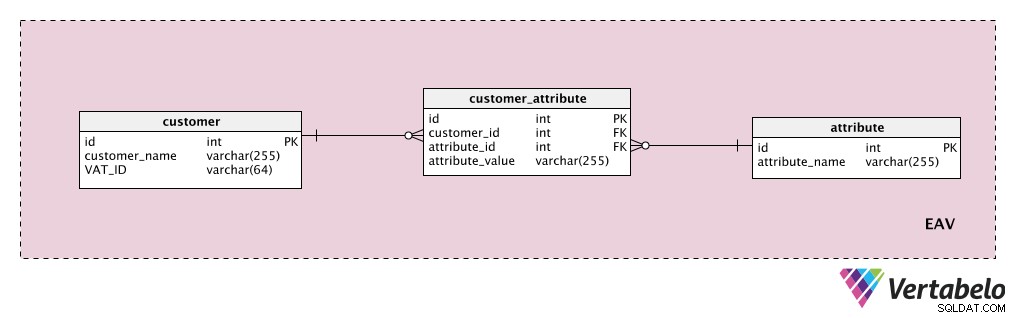
Първо, ще добавим речник със списък на всички възможни свойства, които можем да присвоим на клиент. Това е „attribute ” таблица. Може да съдържа свойства като „стойност на клиента“, „подробности за контакт“, „допълнителна информация“ и т.н. „customer_attribute ” таблицата съдържа списък с всички атрибути, със стойности, за всеки клиент. За всеки клиент ще имаме записи само за атрибутите, които имат, и ще съхраняваме „attribute_value ” за този атрибут.
Това може да изглежда наистина страхотно. Това би ни позволило лесно да добавяме нови свойства (защото ги добавяме като стойности в „customer_attribute ” таблица). По този начин бихме избягвали да правим промени в базата данни. Почти твърде хубаво, за да е истина.
И е твърде добре. Докато моделът ще съхранява необходимите ни данни, работата с такива данни е много по-сложна. И това включва почти всичко, от писане на прости заявки SELECT до получаване на всички стойности, свързани с клиента, до вмъкване, актуализиране или изтриване на стойности.
Накратко, трябва да избягваме структурата на EAV. Ако трябва да го използвате, използвайте го само когато сте 100% сигурни, че наистина е необходим.
#7 Използване на GUID/UUID като първичен ключ
GUID (глобално уникален идентификатор) е 128-битово число, генерирано съгласно правилата, дефинирани в RFC 4122. Понякога те са известни също като UUID (универсално уникални идентификатори). Основното предимство на GUID е, че е уникален; шансът да ударите два пъти един и същ GUID е наистина малко вероятен. Следователно GUID изглеждат чудесен кандидат за колоната с първичен ключ. Но това не е така.
Общо правило за първичните ключове е, че използваме целочислена колона със свойството autoincrement, зададено на „да“. Това ще добави данни в последователен ред към първичния ключ и ще осигури оптимална производителност. Без последователен ключ или времева марка няма начин да разберете кои данни са били вмъкнати първи. Този проблем възниква и когато използваме УНИКАЛНИ стойности от реалния свят (например идентификационен номер по ДДС). Въпреки че притежават УНИКАЛНИ стойности, те не създават добри първични ключове. Вместо това ги използвайте като алтернативни клавиши.
Една допълнителна забележка: Предпочитам да използвам автоматично генерирани целочислени атрибути с една колона като първичен ключ. Това определено е най-добрата практика. Препоръчвам ви да избягвате използването на съставни първични ключове.
#8 Недостатъчно индексиране
Индексите са много важна част от работата с бази данни, но задълбочено обсъждане на тях е извън обхвата на тази статия. За щастие вече имаме няколко статии, свързани с индекси, които можете да разгледате, за да научите повече:- Какво е индекс на база данни?
- Всичко за индексите:много основи
- Всичко за индексите, част 2:Структура и производителност на MySQL индекс
Кратката версия е, че препоръчвам да добавите индекс, където очаквате, че ще е необходим. Можете също да ги добавите, след като базата данни е в производство, ако видите, че добавянето на индекс на определено място ще подобри производителността.
#9 Излишни данни
Излишните данни обикновено трябва да се избягват във всеки модел. Той не само заема допълнително дисково пространство, но също така значително увеличава шансовете за проблеми с целостта на данните. Ако нещо трябва да е излишно, трябва да се погрижим оригиналните данни и „копието“ да са винаги в последователни състояния. Всъщност има някои ситуации, в които излишните данни са желателни:
- В някои случаи трябва да зададем приоритет на определено действие — и за да се случи това, трябва да извършим сложни изчисления. Тези изчисления могат да използват много таблици и да консумират много ресурси. В такива случаи би било разумно тези изчисления да се извършват в извън работно време (като по този начин се избягват проблеми с производителността през работното време). Ако го направим по този начин, бихме могли да съхраним тази изчислена стойност и да я използваме по-късно, без да се налага да я преизчисляваме. Разбира се, стойността е излишна; обаче това, което печелим в производителността, е значително повече от това, което губим (някое място на твърдия диск).
- Може да съхраняваме и малък набор от отчетни данни в базата данни. Например, в края на деня ще съхраняваме броя на обажданията, които сме направили през този ден, броя на успешните продажби и т.н. Данните за отчитане трябва да се съхраняват по този начин само ако трябва да ги използваме често. Още веднъж ще загубим малко място на твърдия диск, но ще избегнем преизчисляване на данни или свързване с базата данни за отчети (ако имаме такава).
В повечето случаи не трябва да използваме излишни данни, защото:
- Съхраняването на едни и същи данни повече от веднъж в базата данни може да повлияе на целостта на данните. Ако съхранявате името на клиента на две различни места, трябва да направите всякакви промени (вмъкване/актуализиране/изтриване) на двете места едновременно. Това също така усложнява кода, който ще ви е необходим, дори и за най-простите операции.
- Въпреки че бихме могли да съхраняваме някои обобщени числа в нашата оперативна база данни, трябва да правим това само когато наистина имаме нужда. Оперативната база данни не е предназначена да съхранява отчетни данни и смесването на тези две обикновено е лоша практика. Всеки, който изготвя отчети, ще трябва да използва същите ресурси като потребителите, работещи по оперативни задачи; заявките за отчитане обикновено са по-сложни и могат да повлияят на производителността. Ето защо трябва да разделите оперативната си база данни и базата данни за отчети.
Сега е ваш ред да претеглите
Надявам се, че четенето на тази статия ви даде някои нови прозрения и ще ви насърчи да следвате най-добрите практики за моделиране на данни. Ще ви спестят малко време!
Изпитвали ли сте някой от проблемите, споменати в тази статия? Мислите ли, че сме пропуснали нещо важно? Или мислите, че трябва да премахнем нещо от нашия списък? Моля, кажете ни в коментарите по-долу.