Забележка:Тази статия показва миграцията на модел на релационна база данни (RDB) към звездна схема с помощта на Eclipse IDE за Voracity (и включени в него продукти), IRI Workbench, след въведение в двете архитектури. Ако се интересувате от мигриране на вашата RDB или данни към модел Data Vault 2.0, нов съветник за Workbench ще дебютира в World Wide Data Vault Consortium през май 2019 г.; абонирайте се за блога на IRI, за да получите тези инструкции стъпка по стъпка веднага след като бъдат публикувани!
Складът за данни (DW) е колекция от данни, извлечени от оперативната или транзакционната система в бизнеса, трансформирани за изчистване на несъответствията и след това подредени да поддържат бърз анализ и/или отчитане. DW изисква схема или логическо описание и графично представяне на своята оперативна база данни. Тази статия засяга тези теми, като същевременно предоставя насоки за преминаване от конвенционална схема на релационна база данни към популярна DW схема, наречена звездна схема.
Звездна схема срещу релационна
Повечето релационни структури от данни са илюстрирани в диаграми на същност-връзка (ER). Диаграмата на ER се използва при разработването на концептуални модели за система за управление на база данни за онлайн обработка на транзакции (OLTP). Това е източникът, от който се превежда структурата на таблицата.
Звездната схема обаче е широко приетият стандарт за основната структура на таблицата на склад за данни. Неговата проста звездообразна форма (когато е ER-диаграма) показва таблицата с факти (съдържаща транзакционни стойности или мерки) в центъра и таблици с измерения (съдържащи описателни или атрибутивни стойности), излъчващи се от нея. Обикновено таблицата с факти е в трета нормална форма (3NF), докато таблиците с размери са денормализирани.
Основните разлики между модел на релация на обект (ER) и модел на звезда са този:
- ER моделите използват логически и физически структури за нормализиран дизайн на база данни
- Моделите на измеренията използват физическа структура за денормализиран дизайн на база данни
За да видите как софтуерът IRI може да де/нормализира данни чрез завъртане на ред-колона, щракнете тук.
Фон на процеса на преобразуване
В тази статия демонстрирам как да конвертирате данни от релационен модел в звезда, като използвате задачи, които трябва да дефинирате повече или по-малко ръчно, но можете да създавате и изпълнявате автоматично и лесно да променяте.
Това, което ще видите тук, са 4GL данните и спецификациите на заданието на IRI — изразени в скриптове „SortCL“[1] — които съпоставят данните в таблици с измерения и обединяват данните в централната таблица с факти. SortCL е основната програма за манипулиране и картографиране на данни в управлението на данни на IRI Voracity и платформата ETL. Въпреки това разбирането на методологията и съпоставянията в моите SortCL работи е ключът тук, а не синтаксиса на скриптовете.
Безплатният графичен интерфейс на Eclipse, IRI Workbench, осигурява съобразен със синтаксиса редактор SortCL, както и графични контури и диалози, диаграми на работния процес и картографиране и интуитивни съветници за работа, за автоматично изграждане или промяна на тези скриптове, ако не искате да го правите на ръка. FYI, IRI използва едни и същи метаданни и GUI за профилиране и диаграмиране на БД, генериране тестови данни, извършване на ETL, форматиране на отчети, маскиране на PII, улавяне на променени данни, мигриране и репликиране на данни, почистване и валидиране на данни и др.
Workbench използва подобрена версия на приставката Data Tools Platform (DTP) за Eclipse за свързване към бази данни през JDBC и за активиране на SQL операции и обмен на метаданни IRI в изгледа Data Source Explorer (DSE). В този случай Workbench поддържа:
- създаването и попълването на ограничени тестови таблици на Oracle (източник) чрез SortCL (или работни места IRI RowGen, според тази статия)
- съпоставянето на данните от таблицата на обектите в таблици с измерения чрез SortCL
- съпоставянето на фактологични елементи като n-арна връзка за асоцииране на таблицата с основни размери; т.е. извършване на свързване с няколко таблици в SortCL за създаване на таблица с факти
- популация на всички целеви (звездна схема) таблици
- ER диаграми на изходните и целевите схеми
Типовете обекти в моя оригинален релационен модел са:Dept, Emp, Project, Category, Item, Item_Use и Sale:
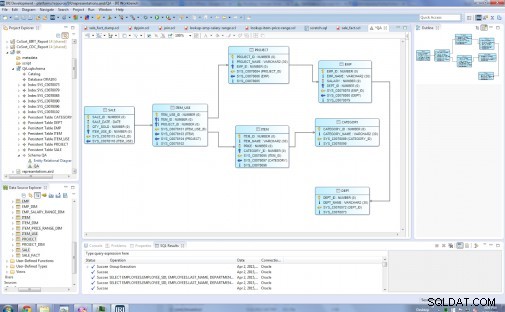
Преди …
Следващата диаграма показва окончателния модел Star с осем таблици с измерения и една таблица с факти. Таблиците с размери са: Dept_Dim, Emp_Dim, Emp_Salary_Range_Dim, Project_Dim, Category_Dim, Item_Price_Range_Dim, Item_Dim. Таблицата с факти в центъра е Sale_Fact, която съдържа ключове за всички таблици с измерения.

… След
Стъпки за преобразуване
- Дефинирайте и създайте таблица с факти
Структурата на таблицата Sale_Fact е показана в този документ. Първичният ключ е sale_id, а останалите атрибути са външни ключове, наследени от таблиците с измерения. Използвам база данни на Oracle (въпреки че всяка RDB работи), свързана с Workbench DSE (чрез JDBC) и SortCL за трансформиране и съпоставяне на данни ( чрез ODBC). Създадох таблиците си в SQL скриптове, редактирани в SQL лексиката на DSE и изпълнени в Workbench.
- Дефинирайте и създайте таблиците с измерения
Използвайте същата техника и метаданни, свързани по-горе, за да създадете тези таблици с измерения, които ще получават релационни данни, картографирани от SortCL задания в следващата стъпка:Category_Dim таблица, Dept до Dept_Dim, Project к Project_Dim, Item to Item_Dim и Emp to Emp_Dim. Можете да стартирате тази .SQL програма с цялата логика CREATE наведнъж, за да изградите таблиците.
- Преместете оригиналните данни от таблицата Entity в таблиците с измерения
Дефинирайте и стартирайте SortCL заданията, показани тук, за картографиране на данните (тест, създаден от RowGen) от релационната схема в таблици с измерения за схемата Star. По-конкретно, тези скриптове зареждат данни от таблица Category в таблицата Category_Dim , Dept до Dept_Dim, Project к Project_Dim, Item в Item_Dim и Emp в Emp_Dim.
- Попълнете таблицата с факти
Използвайте SortCL, за да обедините данни от оригиналните таблици Продажба, Emp, Project, Item_Use, Item, Category , за да подготвите данни за новата таблица Sale_Fact. Използвайте втория скрипт (за работа за присъединяване) тук.
За да подобрим нашия пример, ще използваме и SortCL, за да въведем нови данни за измерения в схемата Star, на която моята таблица с факти също ще разчита. Можете да видите тези допълнителни таблици в диаграмата Star по-горе, които не бяха в моята релационна схема:Emp_Salary_Range_Dim и Item_Price_Range_Dim. Тези таблици са създадени в същия .SQL файл за таблиците с факти и други измерения.
Таблицата с факти се нуждае от данните emp_salary_range_id и item_price_range_id от тези таблици, за да представи диапазона от стойности в тези таблици с величини. Когато зареждам стойностите на цените на размерите в хранилището на данни, например, искам да ги присвоя към ценови диапазон:
| Item_Price | Идентификатор_на_диапазон | Име_на_диапазон | Обхват_Край |
|---|---|---|---|
| 1 | Ниска | 1 | 100 |
| 2 | Среда | 101 | 500 |
| 3 | Висока | 501 | 999 |
Най-простият начин за присвояване на идентификатори на диапазона в скрипта на заданието (който подготвя данни за моята таблица Sale_Fact) е да използвате оператор IF-THEN-ELSE в изходната секция. Вижте тази статия за групиране на стойности за фон.
Както и да е, създадох цялата тази работа с CoSort Нова работа за присъединяване съветник в Workbench. И след като го стартирах, таблицата ми с факти беше попълнена:
 Показване на таблица Sale_Fact в IRI Workbench DSE
Показване на таблица Sale_Fact в IRI Workbench DSE
Заключение
Основното предимство на представянето на данни с размери е намаляването на сложността на структурата на базата данни. Това прави базата данни по-лесна за разбиране и писане на заявки за хората, като минимизира броя на таблиците и следователно броя на необходимите присъединявания. Както бе споменато по-рано, моделите с размери също оптимизират производителността на заявката. Въпреки това, той има слабост, както и сила. Фиксираната структура на звездната схема ограничава заявките. Така че, тъй като прави най-често срещаните заявки лесни за писане, той също така ограничава начина, по който данните могат да бъдат анализирани.
IRI Workbench GUI за Voracity има мощен и изчерпателен набор от инструменти, които опростяват интегрирането на данни, включително създаването, поддръжката и разширяването на хранилища за данни. С този интуитивен, лесен за използване интерфейс, Voracity улеснява бързото, гъвкаво създаване на ETL (извличане, трансформиране, зареждане) от край до край, включващо структури от данни в различни платформи.
При ETL операциите данните се извличат от различни източници, трансформират се отделно и се зареждат в хранилище за данни и евентуално други цели. Изграждането на ETL процеса е потенциално една от най-големите задачи при изграждането на склад; това е сложно и отнема много време. Подходът ETL на IRI поддържа този процес по високоефективен и независим от базата данни начин, като изпълнява цялата интеграция и етапиране на данни във файловата система.
[1] Ако сте любител на синтаксиса, имайте предвид, че скриптовете на SortCL, използвани в продукта IRI CoSort или платформата IRI Voracity, поддържат същия синтаксис и дефиниции на данни като IRI RowGen за генериране на тестови данни, IRI NextForm за миграция на данни и IRI FieldShield за маскиране на данни. Всички тези инструменти се поддържат в графичния интерфейс на IRI Workbench, а метаданните им също могат да бъдат споделяни и екипно управлявани за контрол на версиите, работа/данни и сигурност в облака.
[2] За показване на E-R диаграми в IRI Workbench:
- Изберете нов проект IRI и създайте нова папка
- Изберете тази папка и маркирайте всички приложими таблици на базата данни в Data Source Explorer; след това щракнете с десния бутон върху IRI, Нова ER-диаграма
- Ще бъде създаден файл (Schema.QA)
- Щракнете с десния бутон върху този файл и изберете Ново представяне, Нова диаграма на връзката на обекта.
[3] Елементите на ER диаграмата, които илюстрират такива модели, включват:
- дефинирани типове обекти
- дефинирани атрибути
- връзката между типовете обекти
- обща картина или концептуална диаграма
[4] IRI FACT и SQL*Loader са опции за групово извличане и зареждане, съответно.