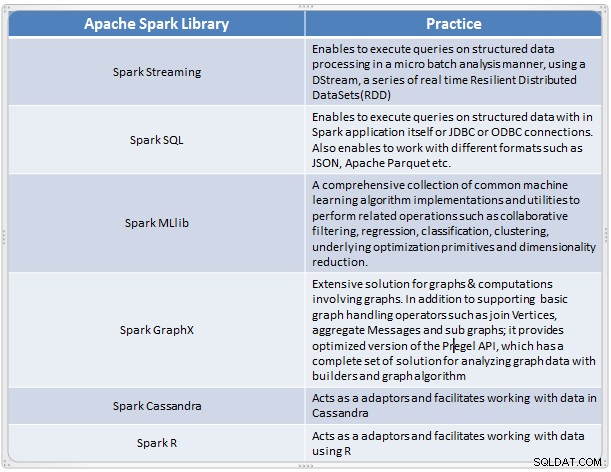
Spark започва живота си през 2009 г. като проект в рамките на AMLab в Калифорнийския университет, Бъркли. По-конкретно, той се роди от необходимостта да се докаже концепцията за Mesos, която също беше създадена в AMLab. Spark беше обсъден за първи път в бялата книга на Mesos, озаглавена Mesos:Платформа за фино споделяне на ресурси в центъра за данни, написана най-вече от Бенджамин Хиндман и Матей Захария.
Той се появи като бързо и удобно решение за извършване на сложен анализ на мащабни данни. Spark се разви като нова рамка за обработка на големи данни, която адресира много от недостатъците на модела MapReduce. Той поддържа широкомащабен анализ на данни и данните могат да бъдат от различни източници като реално време, пакетна обработка в различни формати като изображения, текстове, графики и много други. В допълнение към своето ядро на Apache Spark, той също така предоставя полезен набор от библиотеки за анализ на големи данни.
Преглед на компонентите на Spark
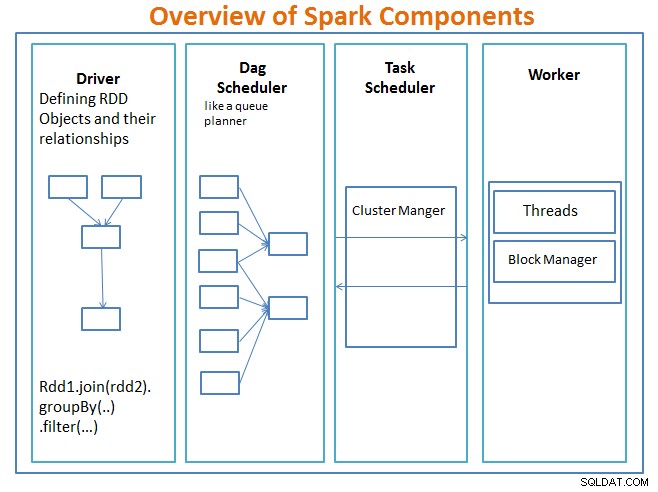
Шофьорът е кодът, който включва основната функция и дефинира устойчивите разпределени набори от данни (RDD) и техните трансформации. RDD са основните структури от данни, които ще се използват в нашите програми Spark.
Паралелните операции на RDD се изпращат към планировчика на DAG , което ще оптимизира кода и ще стигне до ефективна DAG, която представлява стъпките за обработка на данни в приложението.
Получената DAG се изпраща до мениджъра на клъстер и мениджърът на клъстера има информация за работниците, присвоените нишки и местоположението на блоковете от данни и е отговорен за възлагането на специфични задачи за обработка на работниците. Той също така се справя с неуспехите в случай на провал на работника. Мениджърът на клъстерите може да бъде YARN, Mesos, клъстер мениджър на Spark.
работникът получава единици работа и данни за управление и работникът изпълнява своята специфична задача без да знае цялата DAG и резултатите от нея се изпращат обратно към приложенията на драйверите.
Spark, подобно на други инструменти за големи данни, е мощен, способен и подходящ за справяне с редица предизвикателства, свързани с данните. Spark, подобно на други технологии за големи данни, не е непременно най-добрият избор за всяка задача за обработка на данни.
В част 2 – ще обсъдим основите на концепциите на Spark като устойчиви разпределени набори от данни, споделени променливи, SparkContext, трансформации, действие , и предимствата на използването на Spark заедно с примери и кога да използвате Spark.
Справка:
Научете Spark за един ден от Acodemy &Hadoop архитектури на приложения.