JPA (Анотация за постоянство на Java ) е стандартното решение на Java за преодоляване на пропастта между обектно-ориентирани модели на домейни и системи за релационни бази данни. Идеята е да се съпоставят Java класовете с релационни таблици и свойствата на тези класове към редовете в таблицата. Това променя семантиката на цялостното изживяване на Java кодирането чрез безпроблемно сътрудничество на две различни технологии в рамките на една и съща парадигма на програмиране. Тази статия предоставя общ преглед и поддържащата я реализация в Java.
Общ преглед
Релационните бази данни са може би най-стабилната от всички технологии за постоянство, налични в изчисленията, вместо всички сложности, свързани с тях. Това е така, защото днес, дори в ерата на така наречените „големи данни“, релационните бази данни „NoSQL“ са постоянно търсени и процъфтяващи. Релационните бази данни са стабилна технология не само с думи, а с съществуването си през годините. NoSQL може да е добър за работа с големи количества структурирани данни в предприятието, но многобройните транзакционни натоварвания се обработват по-добре чрез релационни бази данни. Освен това има някои страхотни аналитични инструменти, свързани с релационни бази данни.
За да комуникира с релационна база данни, ANSI е стандартизирал език, наречен SQL (Език на структурирани заявки ). Изявление, написано на този език, може да се използва както за дефиниране, така и за манипулиране на данни. Но проблемът на SQL при работа с Java е, че те имат несъответстваща синтактична структура и много различни в основата си, което означава, че SQL е процедурен, докато Java е обектно-ориентиран. Така че се търси работещо решение, така че Java да може да говори обектно-ориентиран начин и релационната база данни все още да може да се разбира. JPA е отговорът на това обаждане и предоставя механизма за установяване на работещо решение между двете.
Свързано с картографирането на обекти
Java програмите взаимодействат с релационни бази данни чрез JDBC (Свързване с база данни на Java ) API. JDBC драйверът е ключът към свързаността и позволява на Java програма да манипулира тази база данни с помощта на JDBC API. След като връзката бъде установена, Java програмата задейства SQL заявки под формата на String s за комуникиране на операции за създаване, вмъкване, актуализиране и изтриване. Това е достатъчно за всички практически цели, но неудобно от гледна точка на Java програмиста. Ами ако структурата на релационните таблици може да бъде премоделирана в чисти Java класове и след това можете да се справите с тях по обичайния обектно-ориентиран начин? Структурата на релационната таблица е логическо представяне на данни в табличен вид. Таблиците са съставени от колони, описващи атрибути на обекти, а редовете са колекция от обекти. Например таблица EMPLOYEE може да съдържа следните обекти с техните атрибути.
| Emp_number | Име | dept_no | Заплата | Място |
| 112233 | Петър | 123 | 1200 | LA |
| 112244 | Лъч | 234 | 1300 | NY |
| 112255 | Sandip | 123 | 1400 | NJ |
| 112266 | Калпана | 234 | 1100 | LA |
Редовете са уникални по първичен ключ (emp_number) в таблица; това позволява бързо търсене. Една таблица може да бъде свързана с една или повече таблици чрез някакъв ключ, като външен ключ (dept_no), който се отнася до еквивалентния ред в друга таблица.
Съгласно спецификацията на Java Persistence 2.1, JPA добавя поддръжка за генериране на схеми, методи за преобразуване на типове, използване на графика на обекти в заявки и операция за намиране, несинхронизиран контекст на постоянство, извикване на съхранени процедури и инжектиране в класове слушатели на обекти. Той също така включва подобрения на езика за заявки Java Persistence, API на критериите и на картографирането на собствени заявки.
Накратко, той прави всичко, за да създаде илюзията, че няма процедурна част при работа с релационни бази данни и всичко е обектно ориентирано.
Внедряване на JPA
JPA описва управление на релационни данни в Java приложение. Това е спецификация и има редица нейни реализации. Някои популярни реализации са Hibernate, EclipseLink и Apache OpenJPA. JPA дефинира метаданните чрез анотации в Java класове или чрез XML конфигурационни файлове. Въпреки това можем да използваме както XML, така и анотацията, за да опишем метаданните. В такъв случай XML конфигурацията отменя поясненията. Това е разумно, тъй като поясненията са написани с Java кода, докато XML конфигурационните файлове са външни за Java кода. Следователно, по-късно, ако има такива, трябва да се направят промени в метаданните; в случай на конфигурация, базирана на анотации, тя изисква директен достъп до Java код. Това винаги може да не е възможно. В такъв случай можем да напишем нова или променена конфигурация на метаданни в XML файл без намек за промяна в оригиналния код и все пак да имаме желания ефект. Това е предимството на използването на XML конфигурация. Въпреки това, базираната на анотации конфигурация е по-удобна за използване и е популярен избор сред програмистите.
- Хибернация е най-популярната и най-напредналата сред всички JPA реализации благодарение на Red Hat. Той използва свои собствени настройки и добавени функции, които могат да се използват в допълнение към изпълнението на JPA. Той има по-голяма общност от потребители и е добре документиран. Някои от допълнителните собствени функции са поддръжка за многократно наемане, присъединяване на несвързани обекти в заявки, управление на времеви печати и така нататък.
- EclipseLink се базира на TopLink и е референтна реализация на версиите на JPA. Той предоставя стандартни JPA функционалности, освен някои интересни собствени функции, като например поддръжка от няколко наемания, обработка на събития за промяна на базата данни и т.н.
Използване на JPA в Java SE програма
За да използвате JPA в програма на Java, имате нужда от доставчик на JPA, като Hibernate или EclipseLink, или всяка друга библиотека. Освен това имате нужда от JDBC драйвер, който се свързва към конкретната релационна база данни. Например, в следния код сме използвали следните библиотеки:
- Доставчик: EclipseLink
- JDBC драйвер: JDBC драйвер за MySQL (Connector/J)
Ще установим връзка между две таблици — „Служител“ и „Отдел“ — като едно към едно и едно към много, както е показано на следващата диаграма на EER (вижте фигура 1).
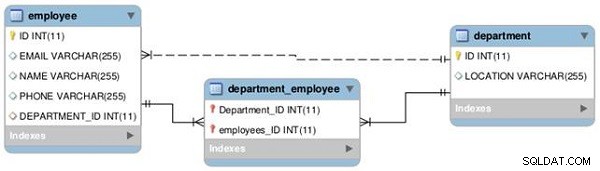
Фигура 1: Връзки в таблицата
Служителят таблицата се съпоставя с клас обект, използвайки анотация, както следва:
package org.mano.jpademoapp;
import javax.persistence.*;
@Entity
@Table(name = "employee")
public class Employee {
@Id
private int id;
private String name;
private String phone;
private String email;
@OneToOne
private Department department;
public Employee() {
super();
}
public Employee(int id, String name, String phone,
String email) {
super();
this.id = id;
this.name = name;
this.phone = phone;
this.email = email;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Department getDepartment() {
return department;
}
public void setDepartment(Department department) {
this.department = department;
}
}
И отдел таблицата се съпоставя с клас обект, както следва:
package org.mano.jpademoapp;
import java.util.*;
import javax.persistence.*;
@Entity
@Table(name = "department")
public class Department {
@Id
private int id;
private String location;
@OneToMany
private List<Employee> employees = new ArrayList<>();
public Department() {
super();
}
public Department(int id, String location) {
super();
this.id = id;
this.location = location;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getLocation() {
return location;
}
public void setLocation(String location) {
this.location = location;
}
public List<Employee> getEmployees() {
return employees;
}
public void setEmployees(List<Employee> employees) {
this.employees = employees;
}
}
Конфигурационният файл, persistence.xml , се създава в META-INF директория. Този файл съдържа конфигурацията на връзката, като използван JDBC драйвер, потребителско име и парола за достъп до базата данни и друга подходяща информация, изисквана от доставчика на JPA за установяване на връзката с базата данни.
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.1"
xmlns_xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi_schemaLocation="https://xmlns.jcp.org/xml/ns/persistence
https://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd">
<persistence-unit name="JPADemoProject"
transaction-type="RESOURCE_LOCAL">
<class>org.mano.jpademoapp.Employee</class>
<class>org.mano.jpademoapp.Department</class>
<properties>
<property name="javax.persistence.jdbc.driver"
value="com.mysql.jdbc.Driver" />
<property name="javax.persistence.jdbc.url"
value="jdbc:mysql://localhost:3306/testdb" />
<property name="javax.persistence.jdbc.user"
value="root" />
<property name="javax.persistence.jdbc.password"
value="secret" />
<property name="javax.persistence.schema-generation
.database.action"
value="drop-and-create"/>
<property name="javax.persistence.schema-generation
.scripts.action"
value="drop-and-create"/>
<property name="eclipselink.ddl-generation"
value="drop-and-create-tables"/>
</properties>
</persistence-unit>
</persistence>
Субектите не се запазват сами. Логиката трябва да се прилага за манипулиране на обекти, за да управляват техния постоянен жизнен цикъл. EntityManager интерфейс, предоставен от JPA, позволява на приложението да управлява и търси обекти в релационната база данни. Създаваме обект на заявка с помощта на EntityManager за комуникация с базата данни. За да получите EntityManager за дадена база данни ще използваме обект, който имплементира EntityManagerFactory интерфейс. Има статично метод, наречен createEntityManagerFactory , в Постоянство клас, който връща EntityManagerFactory за единицата за постоянство, посочена като String аргумент. В следната елементарна реализация ние приложихме логиката.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public enum PersistenceManager {
INSTANCE;
private EntityManagerFactory emf;
private PersistenceManager() {
emf=Persistence.createEntityManagerFactory("JPADemoProject");
}
public EntityManager getEntityManager() {
return emf.createEntityManager();
}
public void close() {
emf.close();
}
}
Сега сме готови да отидем и да създадем основния интерфейс на приложението. Тук сме внедрили само операцията за вмъкване с цел опростяване и ограничение на пространството.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
public class Main {
public static void main(String[] args) {
Department d1=new Department(11, "NY");
Department d2=new Department(22, "LA");
Employee e1=new Employee(111, "Peter",
"9876543210", "example@sqldat.com");
Employee e2=new Employee(222, "Ronin",
"993875630", "example@sqldat.com");
Employee e3=new Employee(333, "Kalpana",
"9876927410", "example@sqldat.com");
Employee e4=new Employee(444, "Marc",
"989374510", "example@sqldat.com");
Employee e5=new Employee(555, "Anik",
"987738750", "example@sqldat.com");
d1.getEmployees().add(e1);
d1.getEmployees().add(e3);
d1.getEmployees().add(e4);
d2.getEmployees().add(e2);
d2.getEmployees().add(e5);
EntityManager em=PersistenceManager
.INSTANCE.getEntityManager();
em.getTransaction().begin();
em.persist(e1);
em.persist(e2);
em.persist(e3);
em.persist(e4);
em.persist(e5);
em.persist(d1);
em.persist(d2);
em.getTransaction().commit();
em.close();
PersistenceManager.INSTANCE.close();
}
}
| Забележка: Моля, направете справка със съответната документация на Java API за подробна информация относно API, използвани в предходния код. |
Заключение
Както трябва да е очевидно, основната терминология на контекста на JPA и Persistence е по-широка от дадения тук поглед, но започването с бърз преглед е по-добре от дългия сложен мръсен код и техните концептуални детайли. Ако имате малък опит в програмирането в основния JDBC, несъмнено ще оцените как JPA може да направи живота ви по-лесен. Ще се потопим по-дълбоко в JPA постепенно, докато продължаваме в следващите статии.



