Въведение
На разработчиците често се казва да използват съхранени процедури, за да избегнат така наречените ad hoc заявки което може да доведе до ненужно раздуване на кеша на плана. Виждате, когато повтарящ се SQL код е написан непоследователно или когато има код, който генерира динамичен SQL в движение, SQL Server има тенденция да създава план за изпълнение за всяко отделно изпълнение. Това може да намали цялостната производителност от:
Изискване на фаза на компилация за всяко изпълнение на код.
Раздуване на кеша на плана с твърде много манипулатори на план, които може да не се използват повторно.
Оптимизиране за Ad Hoc работни натоварвания
Един от начините, по които този проблем е бил обработван в миналото, е оптимизирането на екземпляра за Ad Hoc работни натоварвания. Правенето на това може да бъде полезно само ако повечето бази данни или най-значимите бази данни в екземпляра изпълняват предимно Ad Hoc SQL.
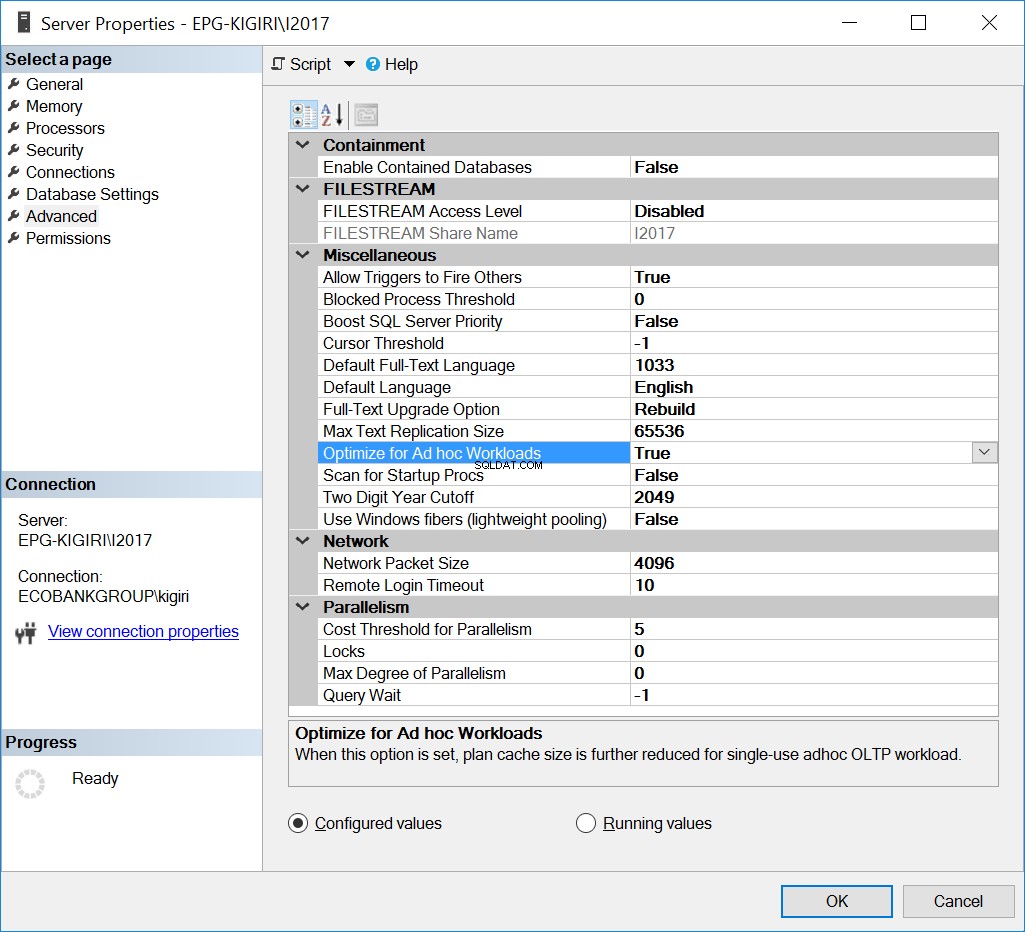
Фиг. 1 Оптимизиране за Ad Hoc работни натоварвания
--Enable OFAW Using T-SQL EXEC sys.sp_configure N'show advanced options', N'1' RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'optimize for ad hoc workloads', N'1' GO RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'show advanced options', N'0' RECONFIGURE WITH OVERRIDE GO
По същество тази опция казва на SQL Server да запази частична версия на плана, известна като компилиран план. Копчето заема много по-малко място от целия план.
Като алтернатива на този метод, някои хора подхождат към проблема доста брутално и от време на време промиват кеша на плана. Или, по по-внимателен начин, изчистете „плановете за еднократна употреба“, като използвате DBCC FREESYSTEMCACHE. Прочистването на целия кеш на плана има своите недостатъци, както може би вече знаете.
Използване на съхранени процедури и параметри
Чрез използване на съхранени процедури човек може на практика да премахне проблема, причинен от Ad Hoc SQL. Съхранената процедура се компилира само веднъж и същият план се използва повторно за последващо изпълнение на същите или подобни SQL заявки. Когато съхранените процедури се използват за внедряване на бизнес логика, ключовата разлика в SQL заявките, които в крайна сметка ще бъдат изпълнени от SQL Server, се крие в параметрите, предавани по време на изпълнение. Тъй като планът вече е въведен и готов за използване, SQL Server ще използва същия план, независимо кой параметър се предава.
Изкривени данни
В определени сценарии данните, с които работим, не са разпределени равномерно. Можем да демонстрираме това – първо ще трябва да създадем таблица:
--Create Table with Skewed Data
use Practice2017
go
create table Skewed (
ID int identity (1,1)
, FirstName varchar(50)
, LastName varchar(50)
, CountryCode char(2)
);
insert into Skewed values ('Kwaku','Amoako','GH')
go 10000
insert into Skewed values ('Kenneth','Igiri','NG')
go 10
insert into Skewed values ('Steve','Jones','US')
go 2
create clustered index CIX_ID on Skewed(ID);
create index IX_CountryCode on Skewed (CountryCode); Нашата таблица съдържа данни за членове на клуба от различни държави. Голям брой членове на клуба са от Гана, докато други две нации имат съответно десет и двама членове. За да се концентрирам върху дневния ред и за простота, използвах само три държави и едно и също име за членове, идващи от една и съща държава. Освен това добавих клъстериран индекс в колоната ID и неклъстериран индекс в колоната CountryCode, за да демонстрирам ефекта от различни планове за изпълнение за различни стойности.
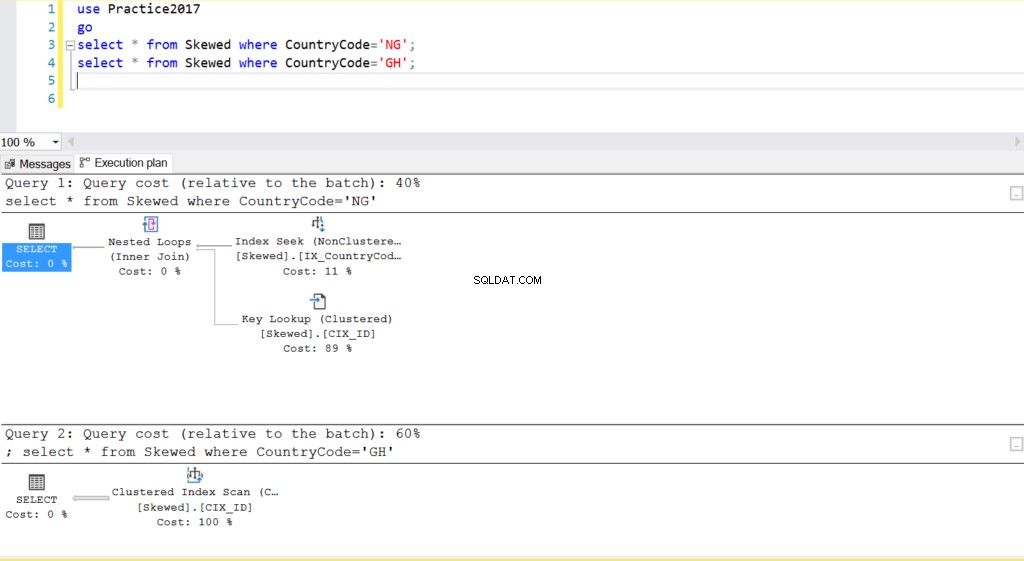
Фиг. 2 Планове за изпълнение за две заявки
Когато правим заявка в таблицата за записи, където CountryCode е NG и GH, откриваме, че SQL Server използва два различни плана за изпълнение в тези случаи. Това се случва, защото очакваният брой редове за CountryCode=’NG’ е 10, докато този за CountryCode=’GH’ е 10000. SQL Server определя предпочитания план за изпълнение въз основа на статистически данни на таблицата. Ако очакваният брой редове е висок в сравнение с общия брой редове в таблицата, SQL Server решава, че е по-добре просто да направи пълно сканиране на таблицата, вместо да се позовава на индекс. При много по-малък приблизителен брой редове индексът става полезен.
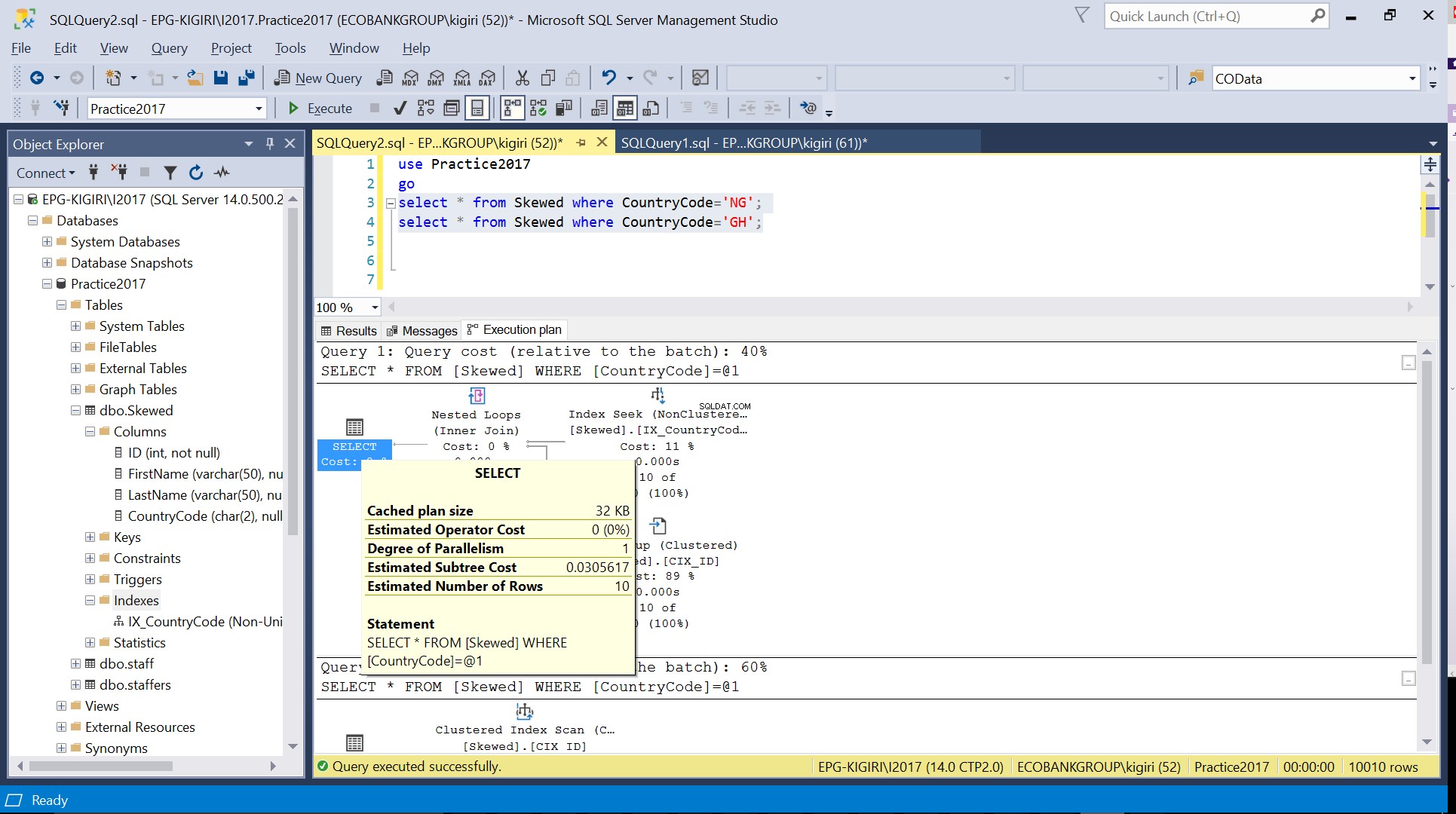
Фиг. 3 Приблизителен брой редове за CountryCode=’NG’
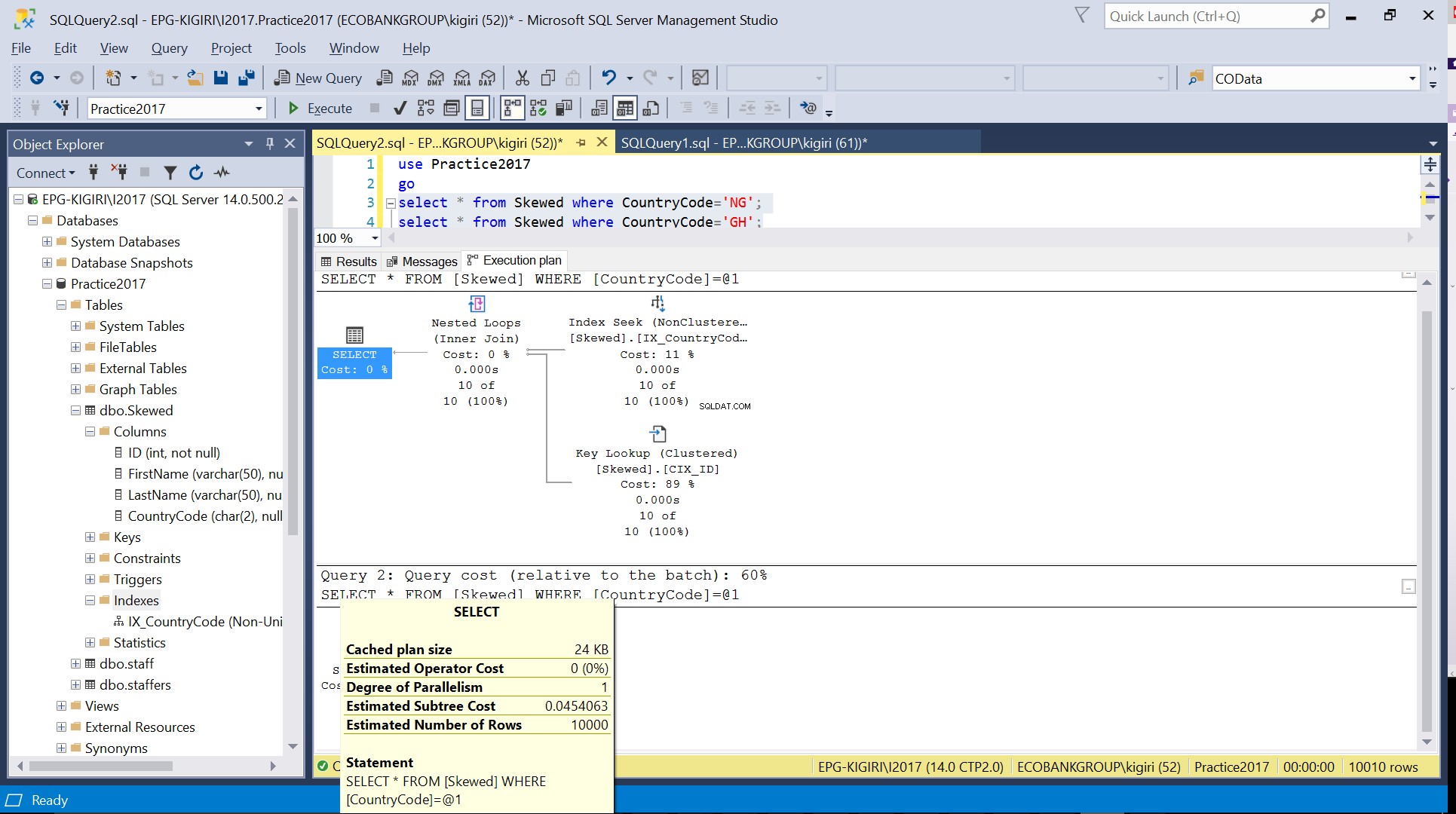
Фиг. 4 Приблизителен брой редове за CountryCode=’GH’
Въведете съхранени процедури
Можем да създадем съхранена процедура за извличане на записите, които искаме, като използваме същата заявка. Единствената разлика този път е, че предаваме CountryCode като параметър (вижте листинг 3). Когато правим това, откриваме, че планът за изпълнение е един и същ, независимо какъв параметър предадем. Планът за изпълнение, който ще се използва, се определя от плана за изпълнение, върнат при първото извикване на съхранената процедура. Например, ако стартираме процедурата с CountryCode=’GH’ първо, тя ще използва пълно сканиране на таблицата от този момент нататък. Ако след това изчистим кеша на процедурите и стартираме процедурата първо с CountryCode=’NG’, тя ще използва сканиране, базирано на индекси в бъдеще.
--Create a Stored Procedure to Fetch the Data use Practice2017 go select * from Skewed where CountryCode='NG'; select * from Skewed where CountryCode='GH'; create procedure FetchMembers ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com end; exec FetchMembers 'NG'; exec FetchMembers 'GH'; DBCC FREEPROCCACHE exec FetchMembers 'GH'; exec FetchMembers 'NG';
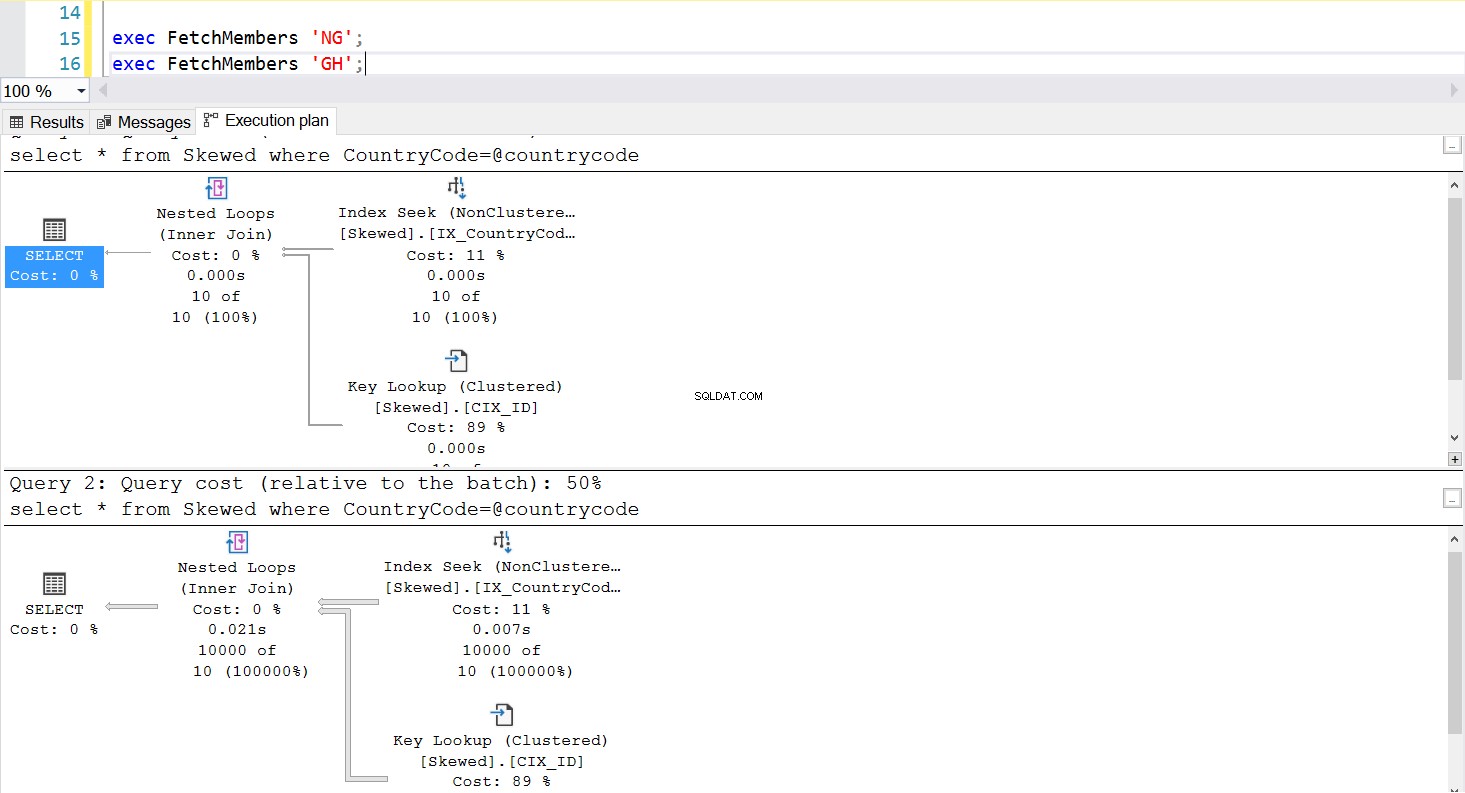
Фиг. 5 План за изпълнение на търсене на индекс, когато първо се използва „NG“
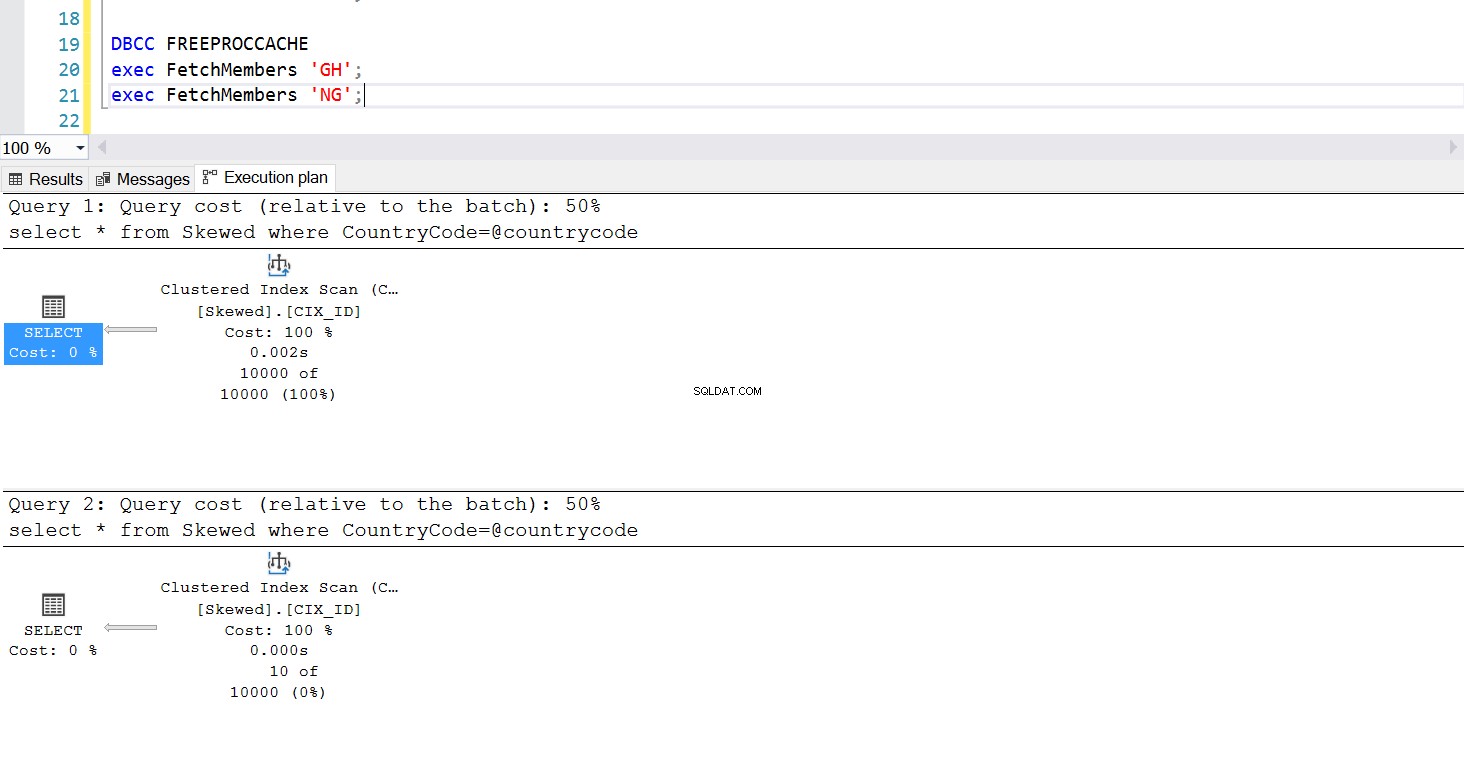
Фиг. 6 План за изпълнение на сканиране на клъстерен индекс, когато първо се използва „GH“
Изпълнението на съхранената процедура се държи както е проектирано – необходимият план за изпълнение се използва последователно. Това обаче може да е проблем, тъй като един план за изпълнение не е подходящ за всички заявки, ако данните са изкривени. Използването на индекс за извличане на колекция от редове, почти толкова голяма, колкото цялата таблица, не е ефективно – нито използва пълно сканиране за извличане само на малък брой редове. Това е проблемът с подслушването на параметри.
Възможни решения
Един често срещан начин за управление на проблема с подслушването на параметри е съзнателното извикване на повторно компилиране, когато се изпълнява съхранената процедура. Това е много по-добре от прочистването на кеша на плана – освен ако искате да прочистите кеша на тази специфична SQL заявка, което е напълно възможно. Разгледайте актуализирана версия на съхранената процедура. Този път използва OPTION (RECOMPILE) за управление на проблема. Фиг.6 ни показва, че когато се изпълнява новата съхранена процедура, тя използва план, подходящ за параметъра, който предаваме.
--Create a New Stored Procedure to Fetch the Data create procedure FetchMembers_Recompile ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com OPTION (RECOMPILE) end; exec FetchMembers_Recompile 'GH'; exec FetchMembers_Recompile 'NG';
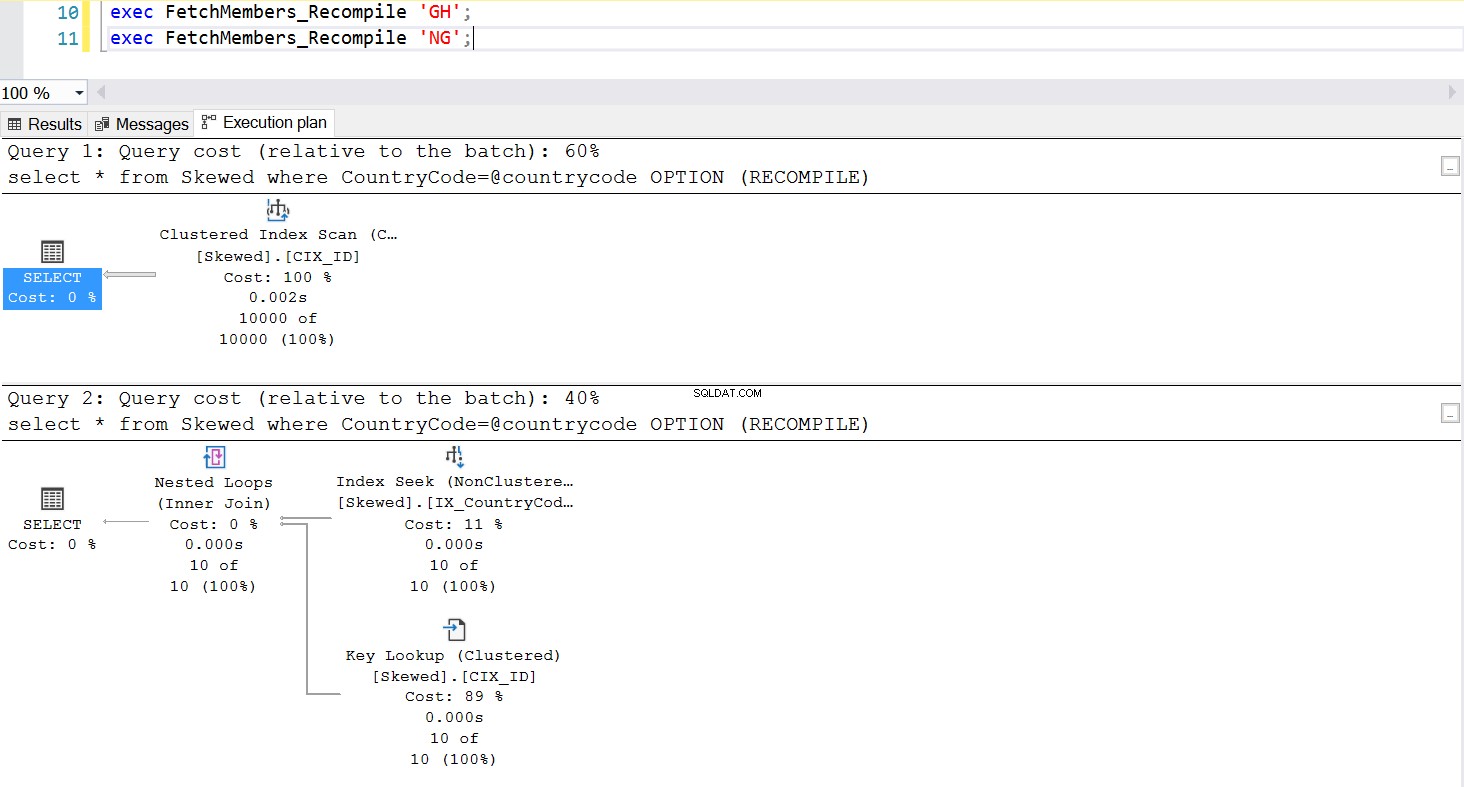
Фиг. 7 Поведение на съхранената процедура с OPTION (RECOMPILE)
Заключение
В тази статия разгледахме как последователните планове за изпълнение на съхранените процедури могат да се превърнат в проблем, когато данните, с които работим, са изкривени. Ние също демонстрирахме това на практика и научихме за общо решение на проблема. Смея да твърдя, че това знание е безценно за разработчиците, които използват SQL Server. Има редица други решения на този проблем – Брент Озар навлезе по-дълбоко в темата и изтъкна някои по-задълбочени подробности и решения на SQLDay Poland 2017. Изброих съответната връзка в раздела за справки.
Препратки
Кеш планиране и оптимизиране за Adhoc работни натоварвания
Идентифициране и коригиране на проблеми с подслушването на параметри



