Общ преглед
Тази статия обсъжда два различни налични подхода за премахване на дублиращи се редове от SQL таблица(и), което често става трудно с течение на времето с нарастването на данните, ако това не се направи навреме.
Наличието на дублиращи се редове е често срещан проблем, с който SQL разработчиците и тестери се сблъскват от време на време, но тези дублиращи се редове попадат в редица различни категории, които ще обсъдим в тази статия.
Тази статия се фокусира върху конкретен сценарий, когато данните, вмъкнати в таблица на база данни, водят до въвеждането на дублиращи се записи и след това ще разгледаме по-отблизо методите за премахване на дубликати и накрая ще премахнем дубликатите с помощта на тези методи.
Подготовка на примерни данни
Преди да започнем да изследваме различните налични опции за премахване на дубликати, на този етап си струва да създадем примерна база данни, която ще ни помогне да разберем ситуациите, когато дублирани данни проникват в системата, и подходите, които да се използват за премахването им .
Настройте примерна база данни (UniversityV2)
Започнете със създаване на много проста база данни, която се състои само от Студент таблица в началото.
-- (1) Create UniversityV2 sample database
CREATE DATABASE UniversityV2;
GO
USE UniversityV2
CREATE TABLE [dbo].[Student] (
[StudentId] INT IDENTITY (1, 1) NOT NULL,
[Name] VARCHAR (30) NULL,
[Course] VARCHAR (30) NULL,
[Marks] INT NULL,
[ExamDate] DATETIME2 (7) NULL,
CONSTRAINT [PK_Student] PRIMARY KEY CLUSTERED ([StudentId] ASC)
);
Попълване на таблица за ученици
Нека добавим само два записа към таблицата Student:
-- Adding two records to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (1, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (2, N'Peter', N'Database Management System', 85, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Проверка на данните
Вижте таблицата, която съдържа два отделни записа в момента:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
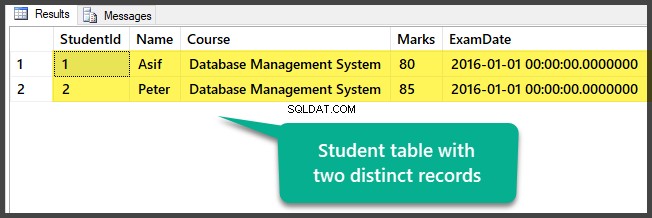
Успешно подготвихте примерните данни, като настроихте база данни с една таблица и два различни (различни) записа.
Сега ще обсъдим някои потенциални сценарии, при които се въвеждат и изтриват дубликати, като се започне от прости до леко сложни ситуации.
Случай 01:Добавяне и премахване на дубликати
Сега ще представим дублиращи се редове в таблицата Student.
Предварителни условия
В този случай се казва, че таблица има дублиращи се записи, ако Име на ученика , Курс , Отметки и Дата на изпита съвпадат в повече от един запис, дори ако идентификационният номер на ученика е различно.
Така че приемаме, че няма двама студенти с едно и също име, курс, оценки и дата на изпита.
Добавяне на дублиращи се данни за ученик Asif
Нека нарочно вмъкнем дублиран запис за Студент:Асиф доСтудента таблица, както следва:
-- Adding Student Asif duplicate record to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (3, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Преглед на дублирани студентски данни
Вижте Студентски таблица, за да видите дублиращи се записи:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
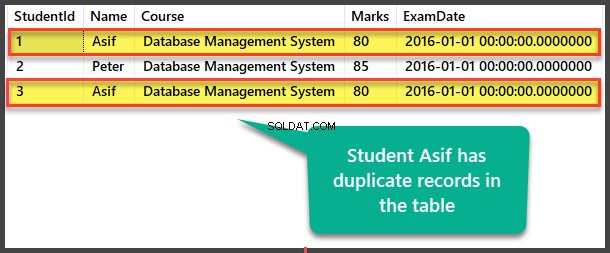
Намиране на дубликати чрез метод за саморефериране
Ами ако има хиляди записи в тази таблица, тогава прегледът на таблицата няма да е от голяма полза.
При метода за самостоятелно препращане ние вземаме две препратки към една и съща таблица и ги свързваме с помощта на съпоставяне колона по колона с изключение на идентификатора, който е по-малък или по-голям от другия.
Нека разгледаме метода за саморефериране, за да намерим дубликати, който изглежда така:
USE UniversityV2
-- Self-Referencing method to finding duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1,[dbo].[Student] S2
WHERE S1.StudentId<S2.StudentId AND
S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
Резултатът от горния скрипт ни показва само дублиращите се записи:

Намиране на дубликати чрез метод за саморефериране-2
Друг начин за намиране на дубликати чрез саморефериране е да използвате INNER JOIN, както следва:
-- Self-Referencing method 2 to find duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
INNER JOIN
[dbo].[Student] S2
ON S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
WHERE S1.StudentId<S2.StudentId

Премахване на дубликати чрез метод за саморефериране
Можем да премахнем дубликатите, използвайки същия метод, който използвахме за намиране на дубликати, с изключение на използването на DELETE в съответствие с неговия синтаксис, както следва:
USE UniversityV2
-- Removing duplicates by using Self-Referencing method
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
Проверка на данните след премахване на дубликати
Нека бързо да проверим записите, след като сме премахнали дубликатите:
USE UniversityV2
-- View Student data after duplicates have been removed
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
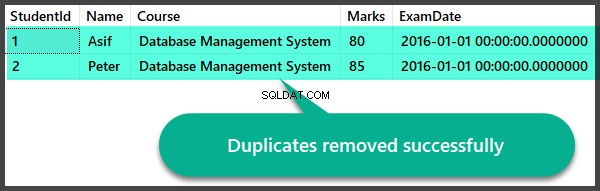
Създаване на дубликати Преглед и съхранена процедура за премахване на дубликати
Сега, когато знаем, че нашите скриптове могат успешно да намират и изтриват дублиращи се редове в SQL, по-добре е да ги превърнем в преглед и съхранена процедура за по-лесно използване:
USE UniversityV2;
GO
-- Creating view find duplicate students having same name, course, marks, exam date using Self-Referencing method
CREATE VIEW dbo.Duplicates
AS
SELECT
S1.[StudentId] AS S1_StudentId
,S2.StudentId AS S2_StudentID
,S1.Name AS S1_Name
,S2.Name AS S2_Name
,S1.Course AS S1_Course
,S2.Course AS S2_Course
,S1.ExamDate AS S1_ExamDate
,S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
,[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
GO
-- Creating stored procedure to removing duplicates by using Self-Referencing method
CREATE PROCEDURE UspRemoveDuplicates
AS
BEGIN
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
END
Добавяне и преглед на множество дублиращи се записи
Нека сега добавим още четири записа към Студент таблица и всички записи са дублирани по такъв начин, че да имат едно и също име, курс, оценки и дата на изпита:
--Adding multiple duplicates to Student table
INSERT INTO Student (Name,
Course,
Marks,
ExamDate)
VALUES ('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01');
-- Viewing Student table after multiple records have been added to Student table
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
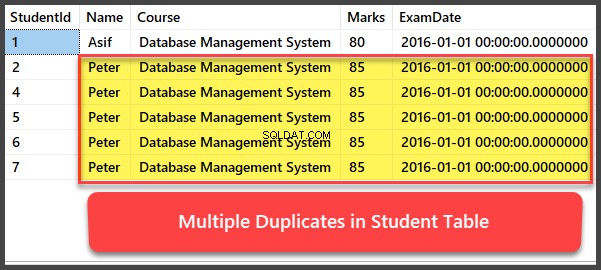
Премахване на дубликати с помощта на процедура UspRemoveDuplicates
USE UniversityV2
-- Removing multiple duplicates
EXEC UspRemoveDuplicates
Проверка на данните след премахване на множество дубликати
USE UniversityV2
--View Student table after multiple duplicates removal
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
USE UniversityV2
-- Creating Course table without primary key
CREATE TABLE [dbo].[Course] (
[CourseId] INT NOT NULL,
[Name] VARCHAR (30) NOT NULL,
[Detail] VARCHAR (200) NULL,
);
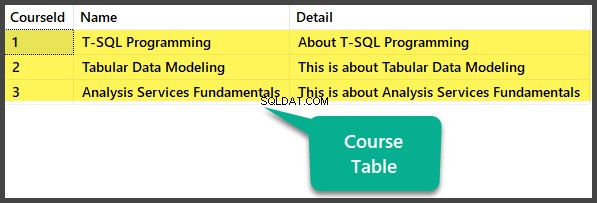
Попълване на таблицата за курсове
-- Populating Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (2, N'Tabular Data Modeling', N'This is about Tabular Data Modeling')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (3, N'Analysis Services Fundamentals', N'This is about Analysis Services Fundamentals')
Проверка на данните
Вижте Курс таблица:
USE UniversityV2
-- Viewing Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course
Добавяне на дублиращи се данни в таблицата на курса
Сега поставете дубликати в Курс таблица:
USE UniversityV2
-- Inserting duplicate records in Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
Преглед на дублиращи се данни за курса
Изберете всички колони, за да видите таблицата:
USE UniversityV2
-- Viewing duplicate data in Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course

Намиране на дубликати чрез обобщен метод
Можем да намерим точни дубликати, като използваме метода на обобщаване, като групираме всички колони с общо повече от една, след като изберете всички колони, заедно с преброяване на всички редове с помощта на функцията за обобщен брой (*):
-- Finding duplicates using Aggregate method
SELECT <column1>,<column2>,<column3>…
,COUNT(*) AS Total_Records
FROM <Table>
GROUP BY <column1>,<column2>,<column3>…
HAVING COUNT(*)>1
Това може да се приложи по следния начин:
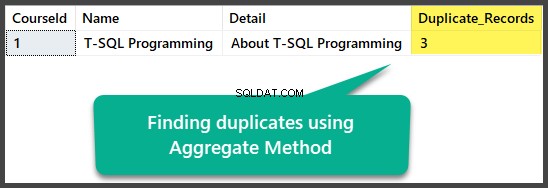
USE UniversityV2
-- Finding duplicates using Aggregate method
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
Премахване на дубликати чрез обобщен метод
Нека премахнем дубликатите, като използваме обобщения метод, както следва:
USE UniversityV2
-- Removing duplicates using Aggregate method
-- (1) Finding duplicates and put them into a new table (CourseNew) as a single row
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records INTO CourseNew
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
-- (2) Rename Course (which contains duplicates) as Course_OLD
EXEC sys.sp_rename @objname = N'Course'
,@newname = N'Course_OLD'
-- (3) Rename CourseNew (which contains no duplicates) as Course
EXEC sys.sp_rename @objname = N'CourseNew'
,@newname = N'Course'
-- (4) Insert original distinct records into Course table from Course_OLD table
INSERT INTO Course (CourseId, Name, Detail)
SELECT
co.CourseId
,co.Name
,co.Detail
FROM Course_OLD co
WHERE co.CourseId <> (SELECT
c.CourseId
FROM Course c)
ORDER BY CO.CourseId
-- (4) Data check
SELECT
cn.CourseId
,cn.Name
,cn.Detail
FROM Course cn
-- Clean up
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
Проверка на данните
USE UniversityV2
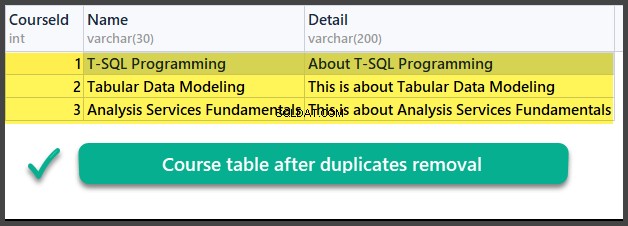
И така, ние успешно се научихме как да премахваме дубликати от таблица на база данни, използвайки два различни метода, базирани на два различни сценария.
Неща за правене
Вече можете лесно да идентифицирате и освободите таблица от база данни от дублирана стойност.
1. Опитайте да създадете UspRemoveDuplicatesByAggregate съхранена процедура, базирана на метода, споменат по-горе, и премахване на дубликати чрез извикване на съхранената процедура
2. Опитайте да модифицирате съхранената процедура, създадена по-горе (UspRemoveDuplicatesByAggregates) и да приложите съветите за почистване, споменати в тази статия.
DROP TABLE CourseNew
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
3. Можете ли да сте сигурни, че UspRemoveDuplicatesByAggregate съхранената процедура може да се изпълнява колкото е възможно повече пъти, дори след премахване на дубликатите, за да се покаже, че процедурата остава последователна на първо място?
4. Моля, вижте предишната ми статия Прескочете към стартиране на разработване на база данни, управлявана от тестове (TDDD) – част 1 и опитайте да вмъкнете дубликати в таблиците на базата данни на SQLDevBlog, след което опитайте да премахнете дубликатите, като използвате и двата метода, споменати в този съвет.
5. Моля, опитайте да създадете друга примерна база данни EmployeesSample позовавайки се на предишната ми статия Изкуство за изолиране на зависимости и данни при тестване на единици от база данни и вмъкнете дубликати в таблиците и опитайте да ги премахнете, като използвате и двата метода, които научихте от този съвет.
Полезен инструмент:
dbForge Data Compare за SQL Server – мощен инструмент за сравнение на SQL, способен да работи с големи данни.