„Но работи добре на нашия сървър за разработка!“
Колко пъти го чух, когато тук-там възникнаха проблеми с производителността на SQL заявката? Самият аз го казах навремето. Предполагах, че заявка, изпълнявана за по-малко от секунда, ще работи добре в производствените сървъри. Но сгреших.
Можете ли да се свържете с това преживяване? Ако все още сте в тази лодка по някаква причина, тази публикация е за вас. Това ще ви даде по-добър показател за фина настройка на ефективността на вашата SQL заявка. Ще говорим за три от най-критичните фигури в STATISTICS IO.
Като пример ще използваме примерната база данни на AdventureWorks.
Преди да започнете да изпълнявате заявки по-долу, включете STATISTICS IO. Ето как да го направите в прозорец за заявка:
USE AdventureWorks
GO
SET STATISTICS IO ONСлед като стартирате заявка със STATISTICS IO ON, ще се появят различни съобщения. Можете да ги видите в раздела Съобщения на прозореца на заявката в SQL Server Management Studio (вижте фигура 1):
След като приключихме с краткото въведение, нека да копаем по-дълбоко.
1. Високи логически показания
Първата точка в нашия списък е най-честият виновник – високите логически четения.
Логическите четения са броят на страниците, прочетени от кеша на данни. Една страница е с размер 8KB. Кешът на данни, от друга страна, се отнася до RAM, използвана от SQL Server.
Логическите четения са от решаващо значение за настройката на производителността. Този фактор определя колко е необходимо на SQL Server, за да произведе необходимия набор от резултати. Следователно единственото нещо, което трябва да запомните е:колкото по-високи са логическите показания, толкова по-дълго трябва да работи SQL Server. Това означава, че вашата заявка ще бъде по-бавна. Намалете броя на логическите четения и ще увеличите ефективността на заявката си.
Но защо да използвате логически четения вместо изминало време?
- Изминалото време зависи от други неща, извършени от сървъра, а не само от вашата заявка.
- Изминалото време може да се промени от сървър за разработка към производствен сървър. Това се случва, когато и двата сървъра имат различен капацитет и хардуерни и софтуерни конфигурации.
Разчитането на изминалото време ще ви накара да кажете:„Но в нашия сървър за разработка работи добре!“ рано или късно.
Защо да използвате логическо четене вместо физическо четене?
- Физическите четения са броят на страниците, прочетени от дискове в кеша на данните (в паметта). След като страниците, необходими за заявка, са в кеша на данните, няма нужда да ги четете отново от дискове.
- Когато същата заявка се изпълни отново, физическите показания ще бъдат нула.
Логическите четения са логичният избор за фина настройка на производителността на SQL заявките.
За да видите това в действие, нека преминем към пример.
Пример за логически четения
Да предположим, че трябва да получите списъка с клиенти с поръчки, изпратени миналия 11 юли 2011 г. По-долу ще получите тази доста проста заявка:
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM Sales.SalesOrderHeader a
INNER JOIN Sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'Ясно е. Тази заявка ще има следния изход:

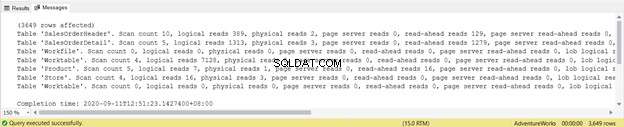
След това проверявате резултата СТАТИСТИКА IO от тази заявка:

Резултатът показва логическите показания на всяка от четирите таблици, използвани в заявката. Общо сумата от логическите показания е 729. Можете също да видите физически четения с обща сума от 21. Въпреки това, опитайте да изпълните отново заявката и тя ще бъде нула.
Разгледайте по-отблизо логическите показания на SalesOrderHeader . Чудите ли се защо има 689 логически показания? Може би сте помислили да проверите плана за изпълнение на заявката по-долу:
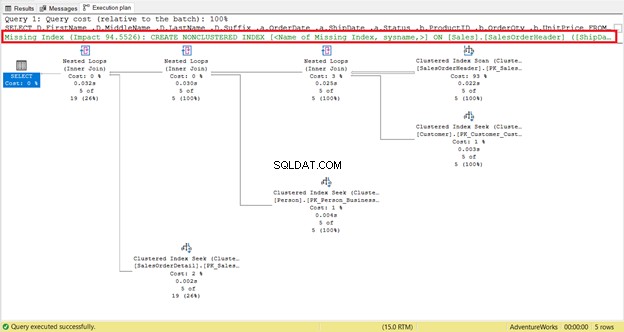
От една страна, има сканиране на индекс, което се е случило в SalesOrderHeader с 93% цена. Какво може да се случи? Да предположим, че сте проверили неговите свойства:
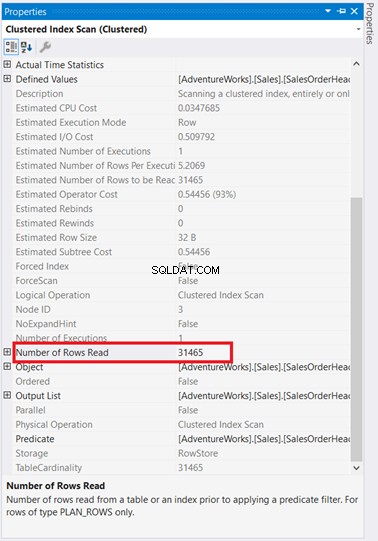
Уау! Върнати ли са 31 465 реда, прочетени само за 5 реда? Абсурдно е!
Намаляване на броя на логическите четения
Не е толкова трудно да намалите тези 31 465 прочетени реда. SQL Server вече ни даде улика. Пристъпете към следното:
СТЪПКА 1:Следвайте препоръката на SQL Server и добавете липсващия индекс
Забелязахте ли липсващата препоръка за индекс в плана за изпълнение (Фигура 4)? Това ще реши ли проблема?
Има един начин да разберете:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_ShipDate]
ON [Sales].[SalesOrderHeader] ([ShipDate])Изпълнете отново заявката и вижте промените в логическите показания на STATISTICS IO.

Както можете да видите в STATISTICS IO (Фигура 6), има огромен спад в логическите четения от 689 на 17. Новите общи логически четения са 57, което е значително подобрение от 729 логически четения. Но за да сме сигурни, нека отново проверим плана за изпълнение.
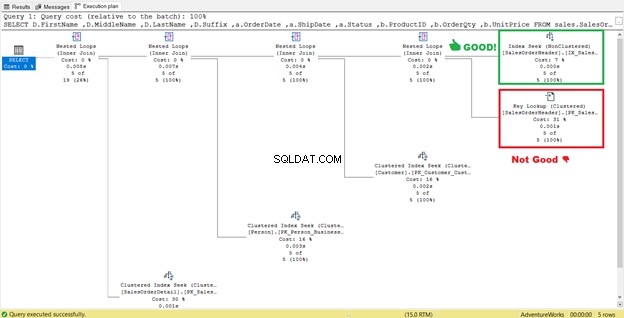
Изглежда, че има подобрение в плана, което води до намалени логически четения. Индексното сканиране вече е търсене на индекс. SQL Server вече няма да има нужда да проверява ред по ред, за да получи записите с Shipdate=’07/11/2011′ . Но нещо все още се крие в този план и не е правилно.
Трябва ви стъпка 2.
СТЪПКА 2:Променете индекса и добавете към включените колони:Дата на поръчка, състояние и идентификатор на клиента
Виждате ли този оператор Key Lookup в плана за изпълнение (Фигура 7)? Това означава, че създаденият неклъстериран индекс не е достатъчен – процесорът на заявки трябва да използва отново клъстерирания индекс.
Нека проверим неговите свойства.
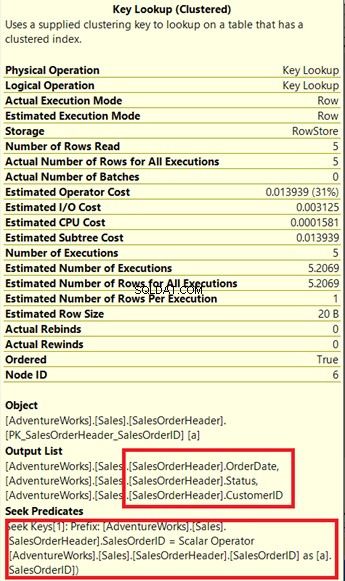
Обърнете внимание на приложеното поле под Изходен списък . Случва се да ни трябва OrderDate ,Състояние и CustomerID в резултатния набор. За да получи тези стойности, процесорът на заявки използва клъстерирания индекс (вижте Търсене на предикати ), за да стигнете до масата.
Трябва да премахнем това Key Lookup. Решението е да включите Дата на поръчка ,Състояние и CustomerID колони в индекса, създаден по-рано.
- Щракнете с десния бутон върху IX_SalesOrderHeader_ShipDate в SSMS.
- Изберете Свойства .
- Щракнете върху Включени колони раздел.
- Добавете Дата на поръчка ,Състояние и CustomerID .
- Щракнете върху OK .
След като пресъздадете индекса, изпълнете отново заявката. Това ще премахне ли Ключово търсене и да намалите логическите четения?

Проработи! От 17 логически показания надолу до 2 (Фигура 9).
И Ключово търсене ?
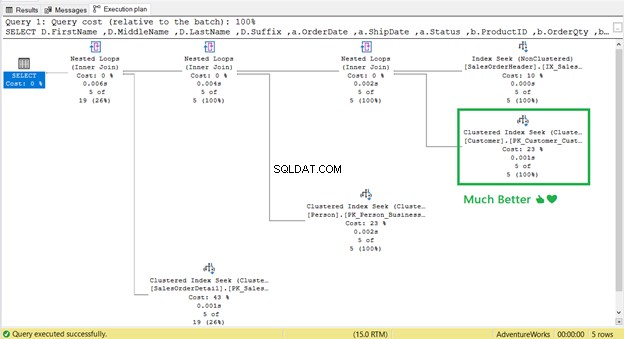
Няма го! Клъстерно търсене на индекси е заменил Key Lookup.
Вземането за вкъщи
И така, какво научихме?
Един от основните начини за намаляване на логическите четения и подобряване на производителността на SQL заявките е създаването на подходящ индекс. Но има уловка. В нашия пример той намали логическите показания. Понякога обратното ще бъде правилно. Това може да повлияе и на производителността на други свързани заявки.
Ето защо, винаги проверявайте СТАТИСТИКА IO и плана за изпълнение след създаване на индекса.
2. Логически четения на висок дял
Това е почти същото като точка №1, но ще се занимава с типове данни текст , ntext ,изображение ,varchar (макс. ), nvarchar (макс. ),варбинарно (макс. ), или columnstore индексни страници.
Нека се обърнем към пример:генериране на логически четения.
Пример за логически четения на Lob
Да приемем, че искате да покажете продукт с неговата цена, цвят, миниатюрно изображение и по-голямо изображение на уеб страница. По този начин получавате първоначална заявка, както е показано по-долу:
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,b.Name AS ProductSubcategory
,d.ThumbNailPhoto
,d.LargePhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
ORDER BY ProductSubcategory, ProductName, a.ColorСлед това го стартирате и виждате изхода като този по-долу:

Тъй като сте толкова високопроизводителен човек (или момиче), вие незабавно проверявате IO STATISTICS. Ето го:

Усеща се като някаква мръсотия в очите ти. 665 лоб логически четения? Не можете да приемете това. Да не говорим за 194 логически показания от ProductPhoto и ProductProductPhoto маси. Наистина смятате, че тази заявка се нуждае от някои промени.
Намаляване на логически четения на Lob
Предишната заявка имаше върнати 97 реда. Всичките 97 велосипеда. Смятате ли, че това е добре да се показва на уеб страница?
Индексът може да помогне, но защо първо не опростите заявката? По този начин можете да избирате какво SQL Server ще върне. Можете да намалите логическите четения на lob.
- Добавете филтър за подкатегорията на продукта и оставете клиента да избере. След това включете това в клаузата WHERE.
- Премахнете Подкатегорията на продукта колона, тъй като ще добавите филтър за продуктовата подкатегория.
- Премахнете LargePhoto колона. Заявете това, когато потребителят избере конкретен продукт.
- Използвайте пейджинг. Клиентът няма да може да види всичките 97 велосипеда наведнъж.
Въз основа на тези операции, описани по-горе, променяме заявката, както следва:
- Премахнете Подкатегория на продукта и Голяма снимка колони от набора от резултати.
- Използвайте OFFSET и FETCH, за да включите страници в заявката. Запитвайте само 10 продукта наведнъж.
- Добавете ProductSubcategoryID в клаузата WHERE въз основа на избора на клиента.
- Премахнете Подкатегорията на продукта колона в клаузата ORDER BY.
Заявката вече ще бъде подобна на тази:
DECLARE @pageNumber TINYINT
DECLARE @noOfRows TINYINT = 10 -- each page will display 10 products at a time
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,d.ThumbNailPhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
AND a.ProductSubcategoryID = 2 -- Road Bikes
ORDER BY ProductName, a.Color
OFFSET (@pageNumber-1)*@noOfRows ROWS FETCH NEXT @noOfRows ROWS ONLY
-- change the OFFSET and FETCH values based on what page the user is.С направените промени ще се подобрят ли лобните логически четения? STATISTICS IO вече отчита:

Снимка на продукта таблицата вече има 0 lob логически четения – от 665 lob логически четения надолу до нищо. Това е известно подобрение.
Вземане за вкъщи
Един от начините за намаляване на логическите четения е да пренапишете заявката, за да я опростите.
Премахнете ненужните колони и намалете върнатите редове до най-малко необходимия. Когато е необходимо, използвайте OFFSET и FETCH за пейджинг.
За да сте сигурни, че промените в заявката са подобрили логическите четения на lob и ефективността на SQL заявката, винаги проверявайте STATISTICS IO.
3. Логически четения на висока работна маса/работен файл
И накрая, това е логично четене на Worktable и Работен файл . Но какви са тези маси? Защо се появяват, когато не ги използвате в заявката си?
Разполага сРаботна маса и Работен файл появяването в STATISTICS IO означава, че SQL Server се нуждае от много повече работа, за да постигне желаните резултати. Прибягва до използване на временни таблици в tempdb , а именноРаботни маси и Работни файлове . Не е непременно вредно да ги има в изхода STATISTICS IO, стига логическите четения да са нулеви и това не създава проблеми на сървъра.
Тези таблици може да се появят, когато има ORDER BY, GROUP BY, CROSS JOIN или DISTINCT, наред с други.
Пример за логически четения на работна таблица/работен файл
Да приемем, че трябва да направите заявка във всички магазини без продажби на определени продукти.
Първоначално измисляте следното:
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
,ISNULL(c.OrderTotal,0) AS OrderTotal
FROM Sales.Store a
CROSS JOIN Production.Product b
LEFT JOIN (SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID, b.OrderDate) c ON a.SalesPersonID
= c.SalesPersonID
AND b.ProductID = c.ProductID
WHERE c.OrderTotal IS NULL
ORDER BY a.SalesPersonID, b.ProductIDТази заявка върна 3649 реда:
Нека проверим какво казва STATISTICS IO:

Струва си да се отбележи, че Работната маса логическите четения са 7128. Общите логически четения са 8853. Ако проверите плана за изпълнение, ще видите много паралелизми, хеш съвпадения, буфери и сканиране на индекси.
Намаляване на логическите четения на работна таблица/работен файл
Не можах да създам нито един оператор SELECT със задоволителен резултат. По този начин единственият избор е да разбиете израза SELECT на множество заявки. Вижте по-долу:
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
INTO #tmpStoreProducts
FROM Sales.Store a
CROSS JOIN Production.Product b
SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
INTO #tmpProductOrdersPerSalesPerson
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID
SELECT
a.SalesPersonID
,a.ProductID
FROM #tmpStoreProducts a
LEFT JOIN #tmpProductOrdersPerSalesPerson b ON a.SalesPersonID = b.SalesPersonID AND
a.ProductID = b.ProductID
WHERE b.OrderTotal IS NULL
ORDER BY a.SalesPersonID, a.ProductID
DROP TABLE #tmpProductOrdersPerSalesPerson
DROP TABLE #tmpStoreProductsТой е с няколко реда по-дълъг и използва временни таблици. Сега нека видим какво разкрива STATISTICS IO:
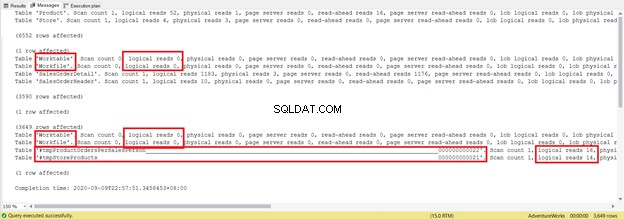
Опитайте се да не се фокусирате върху дължината на този статистически отчет – това е само разочароващо. Вместо това добавете логически показания от всяка таблица.
За общо 1279, това е значително намаление, тъй като бяха 8853 логически четения от единичния оператор SELECT.
Не сме добавили никакъв индекс към временните таблици. Може да имате нужда от такъв, ако към SalesOrderHeader се добавят много повече записи и SalesOrderDetail . Но разбирате смисъла.
Вземане за вкъщи
Понякога 1 оператор SELECT изглежда добър. Зад кулисите обаче е точно обратното. Работни маси и Работни файлове с високо логическо четене забавят производителността на вашата SQL заявка.
Ако не можете да измислите друг начин да реконструирате заявката и индексите са безполезни, опитайте подхода „разделяй и владей“. Работните маси и Работни файлове може все още да се появява в раздела Съобщение на SSMS, но логическите показания ще бъдат нула. Следователно общият резултат ще бъде по-малко логично четене.
Най-долната линия в производителността на SQL заявки и STATISTICS IO
Каква е голямата работа с тези 3 неприятни I/O статистики?
Разликата в производителността на SQL заявката ще бъде като нощ и ден, ако обърнете внимание на тези числа и ги намалите. Представихме само някои начини за намаляване на логическите четения като:
- създаване на подходящи индекси;
- опростяване на заявките – премахване на ненужните колони и минимизиране на набора от резултати;
- разбиване на заявка на множество заявки.
Има повече като актуализиране на статистика, дефрагментиране на индекси и настройка на правилния FILLFACTOR. Можете ли да добавите повече към това в секцията за коментари?
Ако ви харесва тази публикация, моля, споделете я с любимите си социални медии.