Базите данни, които обслужват бизнес приложения, често трябва да поддържат времеви данни. Например, да предположим, че договорът с доставчик е валиден само за ограничен период от време. Тя може да бъде валидна от определен момент нататък или може да е валидна за определен интервал от време - от начална времева точка до крайна времева точка. Освен това много пъти трябва да одитирате всички промени в една или повече таблици. Може също да се наложи да можете да покажете състоянието в определен момент от време или всички промени, направени в таблица през определен период от време. От гледна точка на целостта на данните може да се наложи да приложите много допълнителни специфични за времето ограничения.
Въвеждане на времеви данни
В таблица с времева поддръжка заглавката представлява предикат с поне еднократен параметър, който представлява интервала когато останалата част от предиката е валидна — следователно пълният предикат е предикат с времеви печат. Редовете представляват предложения с времеви печат, а валидният период от време на реда обикновено се изразява с два атрибута:от идо , или започнете икрай .
Типове временни таблици
Може да сте забелязали по време на уводната част, че има два вида темпорални проблеми. Първият е време на валидност на предложението – в кой период твърдението, което представлява отпечатан с времеви ред в таблица, всъщност е вярно. Например, договор с доставчик е бил валиден само от момент 1 до момент 2. Този вид време на валидност е значимо за хората, значимо за бизнеса. Времето на валидност се нарича още време за кандидатстване иличовешко време . Можем да имаме няколко валидни периода за едно и също лице. Например, гореспоменатият договор, който е бил валиден от времева точка 1 до времева точка 2, може също да е валиден от времева точка 7 до времева точка 9.
Вторият временен проблем е времето на транзакцията . Ред за договора, споменат по-горе, беше вмъкнат в точка 1 и беше единствената версия на истината, известна на базата данни, докато някой не я промени или дори до края на времето. Когато редът се актуализира във времева точка 2, първоначалният ред е известен като верен на базата данни от времева точка 1 до времева точка 2. Вмъква се нов ред за същото предложение с времето, валидно за базата данни от времева точка 2 до края на времето. Времето за транзакция е известно още като системно време или време на базата данни .
Разбира се, можете също да внедрите както таблици с версии на приложения, така и на системата. Такива таблици се наричатбиттемпорални таблици.
В SQL Server 2016 получавате поддръжка за системното време от кутията с временни таблици с версии на системата . Ако трябва да внедрите време за прилагане, трябва сами да разработите решение.
Интервални оператори на Алън
Теорията за времевите данни в релационен модел започна да се развива преди повече от тридесет години. Ще представя доста полезни булеви оператори и няколко оператора, които работят на интервали и връщат интервал. Тези оператори са известни като оператори на Алън, кръстени на Дж. Ф. Алън, който дефинира редица от тях в изследователска статия от 1983 г. за времеви интервали. Всички те все още се приемат като валидни и необходими. Системата за управление на база данни може да ви помогне да се справите с времето за прилагане, като внедрите тези оператори от кутията.
Нека първо представя нотацията, която ще използвам. Ще работя на два интервала, обозначени като i1 и i2 . Началната времева точка на първия интервал е b1 , а краят е e1 ; началната времева точка на втория интервал е b2 и краят е e2 . Булеви оператори на Алън са дефинирани в следващата таблица.
[table id=2 /]
В допълнение към булевите оператори, има три оператора на Алън, които приемат интервали като входни параметри и връщат интервал. Тези оператори представляват простаинтервална алгебра . Имайте предвид, че тези оператори имат същото име като релационните оператори, с които вероятно вече сте запознати:Union, Intersect и Minus. Те обаче не се държат точно като своите колеги в отношенията. Като цяло, използвайки някой от трите интервални оператора, ако операцията би довела до празен набор от времеви точки или до набор, който не може да бъде описан с един интервал, тогава операторът трябва да върне NULL. Обединението на два интервала има смисъл само ако интервалите се срещат или се припокриват. Пресичането има смисъл само ако интервалите се припокриват. Операторът за интервал минус има смисъл само в някои случаи. Например, (3:10) Минус (5:7) връща NULL, защото резултатът не може да бъде описан с един интервал. Следващата таблица обобщава дефиницията на операторите на интервалната алгебра.
[table id=3 /]
Проблем с производителността на припокриващи се заявки Един от най-сложните оператори за прилагане е припокриванията оператор. Заявките, които трябва да намерят припокриващи се интервали, не са лесни за оптимизиране. Такива заявки обаче са доста чести във времевите таблици. В тази и следващите две статии ще ви покажа няколко начина за оптимизиране на такива заявки. Но преди да представя решенията, нека представя проблема.
За да обясня проблема ми трябват някои данни. Следният код показва пример как да създадете таблица с интервали на валидност, изразени с b ие колони, където началото и краят на интервал са представени като цели числа. Таблицата се попълва с демонстрационни данни от таблицата WideWorldImporters.Sales.OrderLines. Моля, имайте предвид, че има множество версии на WideWorldImporters база данни, така че може да получите малко по-различни резултати. Използвах архивния файл WideWorldImporters-Standard.bak от https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0, за да възстановя тази демонстрационна база данни на моя екземпляр на SQL Server .
Създаване на демонстрационни данни
Създадох демонстрационна таблица dbo.Intervals вtempd база данни със следния код.
USE tempdb; GO SELECT OrderLineID AS id, StockItemID * (OrderLineID % 5 + 1) AS b, LastEditedBy + StockItemID * (OrderLineID % 5 + 1) AS e INTO dbo.Intervals FROM WideWorldImporters.Sales.OrderLines; -- 231412 rows GO ALTER TABLE dbo.Intervals ADD CONSTRAINT PK_Intervals PRIMARY KEY(id); CREATE INDEX idx_b ON dbo.Intervals(b) INCLUDE(e); CREATE INDEX idx_e ON dbo.Intervals(e) INCLUDE(b); GO
Моля, обърнете внимание и на индексите създадена. Двата индекса са оптимални за търсения в началото на интервал или в края на интервал. Можете да проверите минималното начало и максималния край на всички интервали със следния код.
SELECT MIN(b), MAX(e) FROM dbo.Intervals;
Можете да видите в резултатите, че минималната начална времева точка е 1, а максималната крайна времева точка е 1155.
Даване на контекста на данните
Може да забележите, че представлявам началните и крайните времеви точки като цели числа. Сега трябва да дам на интервалите някакъв времеви контекст. В този случай една точка от време представлява ден . Следният код създава таблица за търсене на дати и го заселва. Имайте предвид, че началната дата е 1 юли 2014 г.
CREATE TABLE dbo.DateNums (n INT NOT NULL PRIMARY KEY, d DATE NOT NULL); GO DECLARE @i AS INT = 1, @d AS DATE = '20140701'; WHILE @i <= 1200 BEGIN INSERT INTO dbo.DateNums (n, d) SELECT @i, @d; SET @i += 1; SET @d = DATEADD(day,1,@d); END; GO
Сега можете да присъедините таблицата dbo.Intervals към таблицата dbo.DateNums два пъти, за да дадете контекста на целите числа, които представляват началото и края на интервалите.
SELECT i.id, i.b, d1.d AS dateB, i.e, d2.d AS dateE FROM dbo.Intervals AS i INNER JOIN dbo.DateNums AS d1 ON i.b = d1.n INNER JOIN dbo.DateNums AS d2 ON i.e = d2.n ORDER BY i.id;
Представяне на проблема с производителността
Проблемът с времевите заявки е, че при четене от таблица SQL Server може да използва само един индекс и успешно да елиминира редове, които не са кандидати за резултата само от едната страна, и след това да сканира останалите данни. Например, трябва да намерите всички интервали в таблицата, които се припокриват с даден интервал. Не забравяйте, че два интервала се припокриват, когато началото на първия е по-ниско или равно на края на втория, а началото на втория е по-ниско или равно на края на първия, или математически, когато (b1 ≤ e2) И (b2 ≤ e1).
Следната заявка търси всички интервали, които се припокриват с интервала (10, 30). Обърнете внимание, че второто условие (b2 ≤ e1) се обръща към (e1 ≥ b2) за по-лесно четене (началото и краят на интервали от таблицата винаги са от лявата страна на условието). Даденият или търсеният интервал е в началото на времевата линия за всички интервали в таблицата.
SET STATISTICS IO ON; DECLARE @b AS INT = 10, @e AS INT = 30; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
Заявката използва 36 логически четения. Ако проверите плана за изпълнение, можете да видите, че заявката е използвала търсенето на индекс в индекса idx_b с предиката за търсене [tempdb].[dbo].[Интервали].b <=Скаларен оператор((30)) и след това сканира. редовете и изберете получените редове с помощта на остатъчния предикат [tempdb].[dbo].[Интервали].[e]>=(10). Тъй като търсеният интервал е в началото на времевата линия, предикатът за търсене успешно елиминира по-голямата част от редовете; само няколко интервала в таблицата имат начална точка по-ниска или равна на 30.
Ще получите подобна ефективна заявка, ако търсеният интервал е в края на времевата линия, просто SQL Server ще използва индекса idx_e за търсене. Какво се случва обаче, ако търсеният интервал е в средата на времевата линия, както показва следната заявка?
DECLARE @b AS INT = 570, @e AS INT = 590; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
Този път заявката използва 111 логически четения. При по-голяма таблица разликата с първата заявка би била още по-голяма. Ако проверите плана за изпълнение, можете да разберете, че SQL Server е използвал индекса idx_e с [tempdb].[dbo].[Интервали].e>=Скаларен оператор((570)) търси предикат и [tempdb].[ dbo].[Интервали].[b]<=(590) остатъчен предикат. Предикатът за търсене изключва приблизително половината от редовете от едната страна, докато половината от редовете от другата страна се сканира и получените редове се извличат с остатъчния предикат.
Подобрено T-SQL решение
Има решение, което би използвало този индекс за елиминиране на редовете от двете страни на търсения интервал чрез използване на един индекс. Следната фигура показва тази логика.
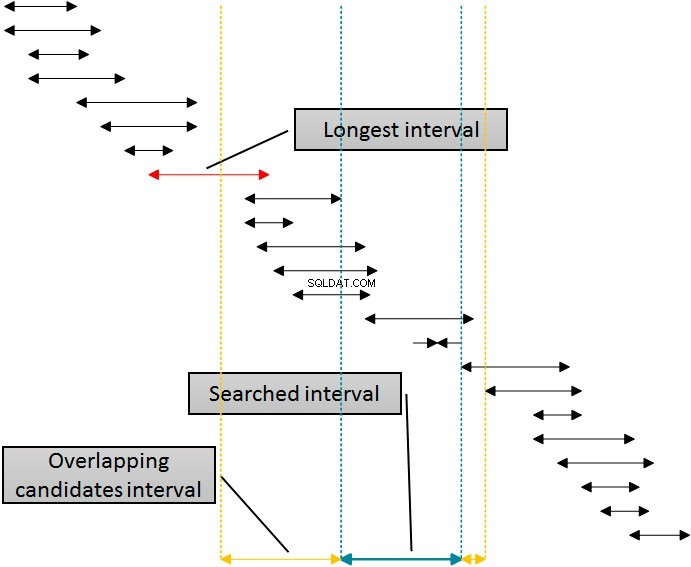
Интервалите на фигурата са сортирани по долната граница, представляваща използването от SQL Server на индекса idx_b. Елиминирането на интервали от дясната страна на дадения (търсен) интервал е просто:просто елиминирайте всички интервали, при които началото е поне с една единица по-голямо (повече вдясно) от края на дадения интервал. Можете да видите тази граница на фигурата, обозначена с най-дясната пунктирана линия. Елиминирането отляво обаче е по-сложно. За да използвам същия индекс, индексът idx_b за елиминиране отляво, трябва да използвам началото на интервалите в таблицата в клаузата WHERE на заявката. Трябва да отида в лявата страна далеч от началото на дадения (търсен) интервал поне за дължината на най-дългия интервал в таблицата, който е отбелязан с извикване на фигурата. Интервалите, които започват преди лявата жълта линия, не могат да се припокриват с дадения (син) интервал.
Тъй като вече знам, че дължината на най-дългия интервал е 20, мога да напиша подобрена заявка по доста прост начин.
DECLARE @b AS INT = 570, @e AS INT = 590; DECLARE @max AS INT = 20; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND b >= @b - @max AND e >= @b AND e <= @e + @max OPTION (RECOMPILE);
Тази заявка извлича същите редове като предишната само с 20 логически четения. Ако проверите плана за изпълнение, можете да видите, че е използван idx_b с предиката търсене Ключове за търсене[1]:Старт:[tempdb].[dbo].[Интервали].b>=Скаларен оператор((550)) , Край:[tempdb].[dbo].[Интервали].b <=Скаларен оператор((590)), който успешно елиминира редове от двете страни на времевата линия, а след това и остатъчния предикат [tempdb].[dbo]. [Интервали].[e]>=(570) И [tempdb].[dbo].[Интервали].[e]<=(610) бяха използвани за избор на редове от много ограничено частично сканиране.
Разбира се, фигурата може да се обърне, за да обхване случаите, когато индексът idx_e би бил по-полезен. С този индекс елиминирането отляво е просто – елиминирайте всички интервали, които завършват поне една единица преди началото на дадения интервал. Този път елиминирането отдясно е по-сложно – краят на интервалите в таблицата не може да бъде по-вдясно от края на дадения интервал плюс максималната дължина на всички интервали в таблицата.
Моля, имайте предвид, че това представяне е следствие от конкретните данни в таблицата. Максималната дължина на интервала е 20. По този начин SQL Server може много ефективно да елиминира интервалите от двете страни. Въпреки това, ако има само един дълъг интервал в таблицата, кодът ще стане много по-малко ефективен, тъй като SQL Server няма да може да елиминира много редове от едната страна, отляво или отдясно, в зависимост кой индекс ще използва . Както и да е, в реалния живот дължината на интервала не варира много пъти, така че тази техника за оптимизиране може да е много полезна, особено защото е проста.
Заключение
Моля, имайте предвид, че това е само едно възможно решение. Можете да намерите решение, което е по-сложно, но то дава предвидима производителност, независимо от дължината на най-дългия интервал в статията за интервални заявки в SQL Server от Itzik Ben-Gan (https://sqlmag.com/t-sql/ sql-server-interval-queries). Въпреки това много харесвамподобрения T-SQL решение, което представих в тази статия. Решението е много просто; всичко, което трябва да направите, е да добавите два предиката към клаузата WHERE на вашите припокриващи се заявки. Това обаче не е краят на възможностите. Останете на линия, в следващите две статии ще ви покажа още решения, така че ще имате богат набор от възможности във вашата кутия с инструменти за оптимизация.
Полезен инструмент:
dbForge Query Builder за SQL Server – позволява на потребителите да създават бързо и лесно сложни SQL заявки чрез интуитивен визуален интерфейс без ръчно писане на код.