Причина за проблема :
TOKEN метод в SSIS използва внедряването на strtok функция в C++ . Събрах тази информация, докато четях книгата Microsoft® SQL Server® 2012 Integration Services
. Споменава се като бележка на страница 113 (Харесвам тази книга! Много хубава информация. ).
Търсих внедряването на strtok функция и намерих следните връзки.
ИНФОРМАЦИЯ:strtok():C функция – Допълнение към документацията – Примерният код в тази връзка показва, че функцията игнорира последователните разделителни знаци.
Отговорите на следните SO въпроси посочват, че strtok функцията е предназначена да игнорира последователни разделители.
Трябва да знаете, когато не се появяват данни между два разделителя на токени с помощта на strtok()
поведение на strtok_s с последователни разделители
Мисля, че TOKEN и TOKENCOUNT функциите работят според дизайна, но дали това е начинът, по който SSIS трябва да се държи, може да бъде въпрос за екипа на Microsoft SSIS.
Оригинална публикация - Горният раздел е актуализация:
Създадох прост пакет в SSIS 2012 въз основа на вашите въведени данни. Както описахте във вашия въпрос, TOKEN функцията не се държи по предназначение. Съгласен съм с вас, че функцията изглежда не работи. Тази публикация ене отговор на първоначалния ви проблем.
Ето алтернативен начин да напишете израза по относително по-опростен начин. Това ще работи само ако последният сегмент във вашия входен запис винаги ще има стойност (да речем A1 , B2 , C3 и т.н.).
Изразът може да бъде пренаписан като :
Този оператор ще приеме входния запис като параметър, разделителната каретка (^) като втори параметър. Третият параметър изчислява общия брой сегменти в записите, когато са разделени от разделителя. Ако имате данни в последния сегмент, гарантирано имате два сегмента. След това можете да извадите 1, за да извлечете предпоследния сегмент.
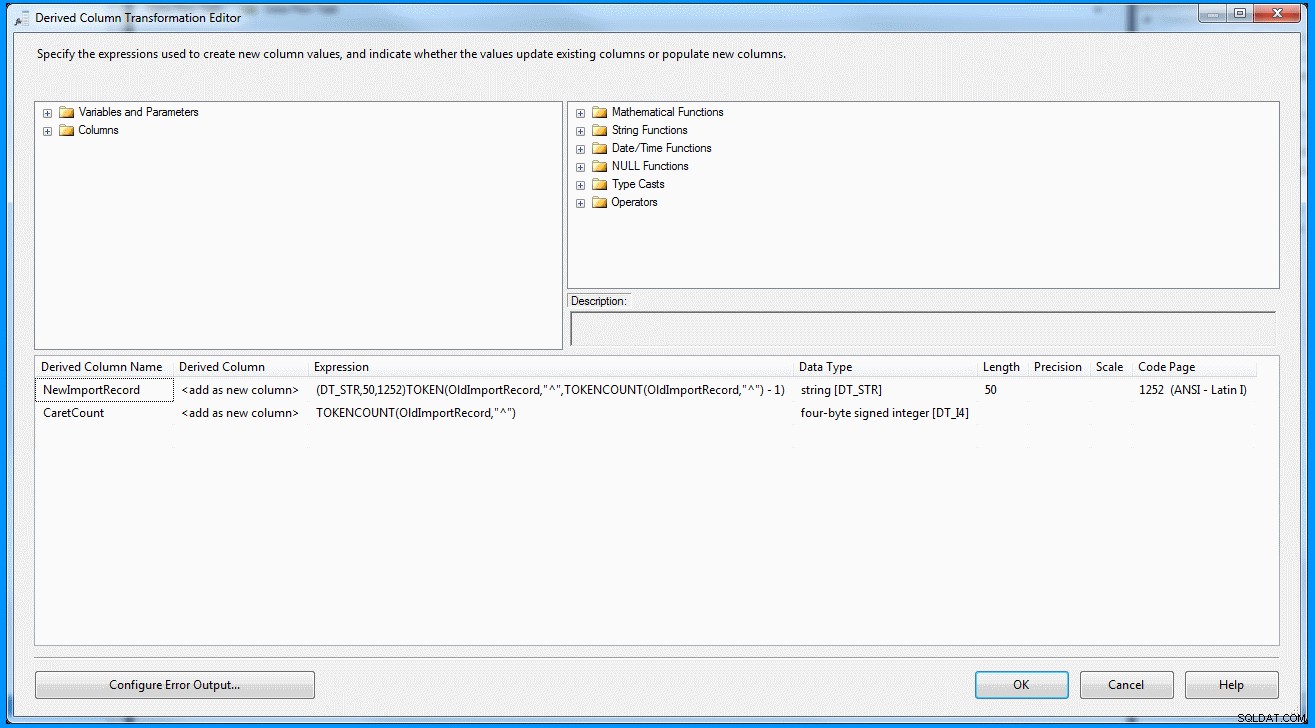
(DT_STR,50,1252)TOKEN(OldImportRecord,"^",TOKENCOUNT(OldImportRecord,"^") - 1)
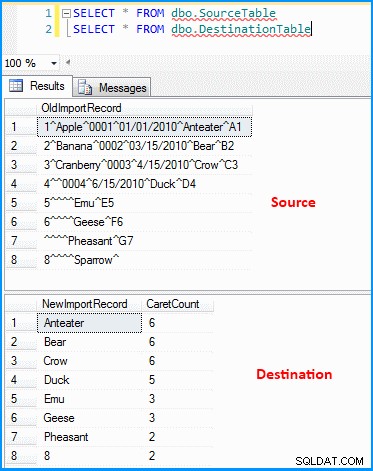
Създадох прост пакет със задача за поток от данни. Източникът на OLE DB извлича данните и получената трансформация анализира и разделя данните според екранната снимка по-долу. След това изходът се вмъква в целевата таблица. Можете да видите таблиците източник и местоназначение на последната екранна снимка. Таблицата с местоназначение има две колони. Първата колона съхранява данните за предпоследния сегмент и броя на сегментите въз основа на разделителя (което отново не е правилно). Можете да забележите, че последният запис не извлече правилните резултати. Ако последният запис не е имал стойност 8 , тогава горният израз ще бъде неуспешен, защото изразът ще се изчисли на нулев индекс.
Надяваме се, че това ще ви помогне да опростите израза си.
Ако не се чувате с никой друг, бих препоръчал да регистрирате този проблем в уебсайта на Microsoft Connect .
Създаване на таблица и попълване на скриптове :
CREATE TABLE [dbo].[SourceTable](
[OldImportRecord] [varchar](50) NOT NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[DestinationTable](
[NewImportRecord] [varchar](50) NOT NULL,
[CaretCount] [int] NOT NULL
) ON [PRIMARY]
GO
INSERT INTO dbo.SourceTable (OldImportRecord) VALUES
('1^Apple^0001^01/01/2010^Anteater^A1'),
('2^Banana^0002^03/15/2010^Bear^B2'),
('3^Cranberry^0003^4/15/2010^Crow^C3'),
('4^^0004^6/15/2010^Duck^D4'),
('5^^^^Emu^E5'),
('6^^^^Geese^F6'),
('^^^^Pheasant^G7'),
('8^^^^Sparrow^');
GO
Изведена трансформация на колона в задача за поток от данни :
Данни в таблиците източник и местоназначение :