В предишна статия проучихме изискванията за индекс на SQL Server и съображенията за производителност. Когато става въпрос за производителност на базата данни, настройката на производителността без съмнение е една от най-важните и сложни функции. Състои се от много различни области, като оптимизация на SQL заявки, настройка на индекс и настройка на системните ресурси, като всички те трябва да бъдат изпълнени правилно, за да се извличат бързо данни успешно.
Има няколко важни области, които трябва да имате предвид, когато става въпрос за индекси на SQL Server, тъй като те могат да окажат значително влияние както върху вашите усилия за настройка на производителността, така и върху цялостната производителност на базата данни. По-долу са дадени някои подробности за всеки и критичните роли, които играят.
Най-добри практики за индексиране на SQL Server
1. Разберете как дизайнът на базата данни влияе върху индексите на SQL Server
Изискванията за индексиране варират между базите данни за онлайн обработка на транзакции (OLTP) и онлайн аналитична обработка (OLAP).
В OLTP база данни потребителите извършват чести операции за четене и запис, като вмъкват нови данни и променят съществуващи данни. Те използват езикови заявки за манипулиране на данни (вмъкване, актуализиране, изтриване) заедно с оператори Select за извличане и модификации на данни. За OLTP бази данни е най-добре да създадете индекси в колоната Selected на таблица. Множество индекси може да имат отрицателно въздействие върху производителността и да натоварят системните ресурси. Вместо това се препоръчва да създадете минималния брой индекси, които могат да изпълнят вашите изисквания за индексиране. В OLAP бази данни, от друга страна, използвате предимно оператори Select за извличане на данни за по-нататъшни аналитични цели. В този случай можете да добавите още индекси с множество ключови колони на индекс. Можете също да използвате индекси на columnstore за по-бързо извличане на данни в заявки за склад на данни
2. Създайте индекси за вашите изисквания за работно натоварване
Когато създавате нова таблица във вашата база данни, не добавяйте просто индекси на сляпо. Понякога разработчиците поставят един клъстериран индекс и няколко неклъстерирани индекса в него, без да търсят заявките, които използват тези индекси. Може да има индекс, който не отговаря на изискването за оптимизатор на заявки; следователно трябва правилно да анализирате вашето работно натоварване и SQL заявки (запазени процедури, функции, изгледи и ad-hoc заявки). Можете да уловите работното натоварване с помощта на SQL профайлър, разширени събития и динамични изгледи за управление и след това да създавате индекси за оптимизиране на ресурсоемки заявки.
3. Създайте индекси за най-интензивните и често използвани заявки
Важно е да групирате работните натоварвания за най-използваните заявки във вашата система. Създавайки най-добрите индекси за тези заявки, това ще натовари най-малко вашата система.
4. Приложете най-добрите практики в колоната на индекса на SQL Server
Тъй като можете да имате няколко колони в таблица, ето няколко съображения за колоните с индексни ключови колони.
- Колоните с текст, изображение, ntext, varchar(max), nvarchar(max) и varbinary(max) не могат да се използват в колоните на индексния ключ.
- Препоръчително е да използвате целочислен тип данни в колоната на индексния ключ. Има малко изискване за пространство и работи ефективно. Поради това ще искате да създадете колоната с първичен ключ, обикновено върху целочислен тип данни.
- Можете да използвате само тип данни XML в XML индекс.
- Трябва да помислите за създаване на първичен ключ за колоната с уникални стойности. Ако дадена таблица няма колони с уникални стойности, можете да дефинирате колона за идентичност за целочислен тип данни. Първичният ключ също създава клъстериран индекс за разпределението на редовете.
- Можете да разгледате колона с уникални и не NULL стойности като полезен кандидат за ключов индекс.
- Трябва да изградите индекс въз основа на предикатите в клаузата Where. Например, можете да разгледате колони, използвани в клаузата Where, SQL присъединява, като, подреждане по, групиране по предикати и т.н.
- Трябва да обедините таблици по начин, който намалява броя на редовете за останалата част от заявката. Това ще помогне на оптимизатора на заявки да подготви плана за изпълнение с минимални системни ресурси.
- Ако използвате няколко колони за индексен ключ, също така е важно да вземете предвид тяхната позиция в индексния ключ.
- Трябва също да обмислите използването на включени колони във вашите индекси.
5. Анализирайте разпределението на данните на индексните колони на SQL Serverа
Трябва да разгледате разпределението на данните в ключовите колони на индекса на SQL Server. Колона с неуникални стойности може да причини забавяне при извличането на данните и да доведе до продължителна транзакция. Можете да анализирате разпределението на данните, като използвате хистограмата в статистиката.
6. Използвайте реда за сортиране на данни
Трябва също да вземете предвид изискванията за сортиране на данни във вашите заявки и индекси. По подразбиране SQL Server сортира данните във възходящ ред в индекс. Да предположим, че създавате индекс във възходящ ред, но вашите заявки използват клаузата Order By, за да сортират данните в низходящ ред.
Например, вижте действителния план за изпълнение на следната заявка.
ИЗБЕРЕТЕ [SalesOrderID],
[UnitPrice]
ОТ [AdventureWorks].[Sales].[SalesOrderDetail]
ПОРЪЧАЙТЕ ПО UnitPrice DESC,
SalesOrderID ASC;
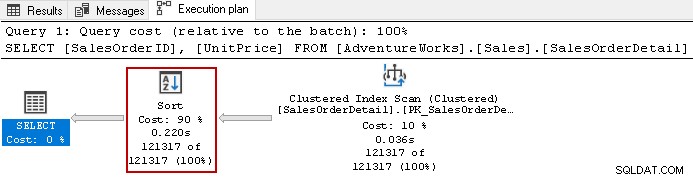
Той използва скъпоструващия оператор за сортиране с обща цена от 90% в тази заявка. Решихме да изградим неклъстериран индекс на [UnitPrice] и [SalesOrderID]. Той използва ред на сортиране по подразбиране и за двете колони в индекса.
СЪЗДАЙТЕ НЕКЛУСТРИРАН ИНДЕКС IX_SalesOrderDetail_Unitprice
ВЪВ [AdventureWorks].[Sales].[SalesOrderDetail]
(UnitPrice ASC, SalesOrderID ASC);
Изпълнихме отново оператора Select и оптимизаторът на заявки все още използва оператора за сортиране. Може да използва неклъстерирания индекс, но сортира данните, за да подготви резултата.
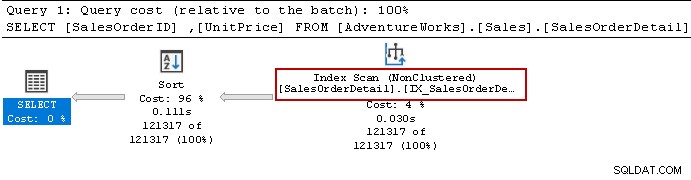
Нека пресъздадем индекса с помощта на следната заявка. Този път сортира данните в низходящ ред за [Unitprice] в дефиницията на индекса.
ОТПУСКАНЕ ИНДЕКС IX_SalesOrderDetail_Unitprice ВЪВ [AdventureWorks].[Sales].[SalesOrderDetail];
Напред СЪЗДАЙТЕ НЕКЛУСТРИРАН ИНДЕКС IX_SalesOrderDetail_Unitprice ВЪВ [AdventureWorks].[Sales].[SalesOrderDetail](UnitPrice DESC, SalesOrderID ASC);
Отиди
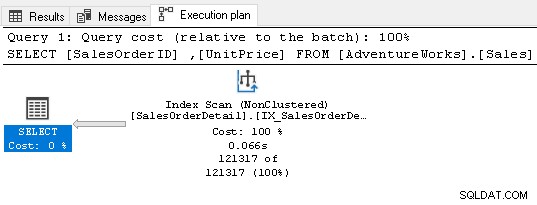
Сега не изисква оператор за сортиране, защото индексът удовлетворява изискванията на заявката.
7. Използвайте външни ключове за индекса на вашия SQL Server
Трябва да създадете индекс на колоните с външни ключове. Препоръчително е да създадете клъстериран индекс на външния ключ, за да подобрите ефективността на заявката.
8. Имайте предвид съображенията за съхранение на индекси на SQL Server
Съхранението на индекси също е полезен аспект, който трябва да се вземе предвид. SQL Server създава всички индекси в една и съща файлова група на таблицата. Можете да помислите за отделна файлова група за индекси и да отделите физическия файл на отделен диск. Това ще увеличи производителността и пропускателната способност на IO.
По същия начин можете да използвате разделяне на таблици, за да разделите данни между множество дискове и файлови групи. Можете да проектирате разделени индекси за тези дялове на таблицата, за да подобрите едновременния достъп до данни.
Друга възможност е да дефинирате FILLFACTOR, докато създавате или възстановявате индекс. FILLFACTOR дефинира свободното пространство в страниците с данни за крайния възел. Полезно е за по-нататъшно вмъкване на данни. Ако вашите данни са статични и не се променят често, можете да помислите за висока стойност на FILLFACTOR. От друга страна, за честа промяна на данни, можете да оставите достатъчно място за вмъкване на нови данни.
9. Намерете липсващи индекси
Понякога получавате информация за липсващ индекс на SQL Server в плана за изпълнение на заявката. Можете също да стартирате динамичните изгледи за управление, за да намерите тези липсващи индекси. Не трябва да създавате сляпо тези индекси. Това е просто предложение за оптимизатор на заявки, но не взема предвид съществуващия индекс или изискванията на вашето работно натоварване. Може също да включва множество колони в дефиницията на индекса, така че прегледайте тези предложения, преди да го приложите.
10. Винаги създавайте клъстериран индекс преди неклъстерен индекс
Като общо указание трябва да създадете клъстериран индекс, преди да създадете неклъстерни индекси. Ако таблицата няма индекс, неклъстерираният индекс се състои от идентификатори на редове. След като създадете клъстериран индекс, SQL Server трябва да изгради отново тези неклъстерирани индекси, така че да могат да сочат към клъстерния индексен ключ вместо идентификаторите на редовете.
11. Наблюдавайте поддръжката на индекса и актуализирайте статистиката
По-долу са дадени няколко области за поддръжка, които да наблюдавате, когато става въпрос за индекси на SQL Server.
- Премахване на фрагментацията на индекса :Трябва редовно да преглеждате вътрешните и външните фрагментации, особено за таблиците с високи транзакции. Вашите заявки може да отговарят бавно, дори ако имате подходящи индекси за вашите работни натоварвания. Силно фрагментиран индекс може да влоши производителността, защото изисква допълнително IO. Можете да извършите реорганизация или да изградите отново индекс въз основа на неговите стойности на фрагментация. Обикновено трябва да изградите отново индекса, ако има фрагментация по-голяма от 30% и да го реорганизирате, ако има по-малко от 30% фрагментация.
- Премахнете неизползваните индекси: Винаги трябва да преглеждате неизползваните (неактивни) индекси във вашата база данни, защото оптимизаторът на заявки трябва да ги вземе предвид за всяка заявка. Неизползваният индекс също консумира място за съхранение и увеличава разходите за поддръжка.
- Актуализиране на статистическите данни: Трябва периодично да актуализирате статистическите данни, дори ако сте задали статистическите данни за автоматично актуализиране в конфигурацията на вашата база данни. Оптимизаторът на заявки може да подготви лош план за изпълнение, ако статистиката на индекса не се актуализира. Можете да планирате задание на агент, за да актуализирате статистиката на SQL Server с пълно сканиране след работно време.
Можете да се обърнете към Поддръжка на SQL индекс за допълнителна информация по тази тема.
Прилагане на най-добри практики за индекс на SQL Server
Въпреки че не винаги има лесен начин за проектиране на оптимален индекс на SQL Server, прилагането на препоръките, посочени в тази публикация, ще ви помогне да се ориентирате в различните изисквания за индексиране, които ще срещнете с всеки тип база данни и нейните работни натоварвания. Тези най-добри практики ще помогнат за оптимизиране на вашите индекси за подобряване на производителността на базата данни и осигуряване на по-плавен процес на настройка на производителността по пътя.