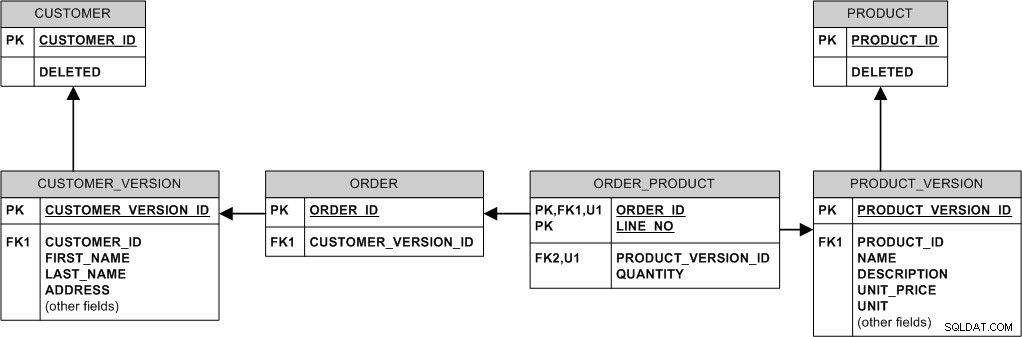
Ето един начин да го направите:
По същество ние никога не променяме или изтриваме съществуващите данни. Ние го "модифицираме", като създадем нова версия. Ние го „изтриваме“, като зададем флага DELETED.
Например:
- Ако продукт промени цената, ние вмъкваме нов ред в PRODUCT_VERSION, докато старите поръчки се поддържат свързани със старата PRODUCT_VERSION и старата цена.
- Когато купувачът промени адреса, ние просто вмъкваме нов ред в CUSTOMER_VERSION и свързваме нови поръчки с него, като запазваме старите поръчки, свързани със старата версия.
- Ако продуктът бъде изтрит, ние всъщност не го изтриваме – просто задаваме флага PRODUCT.DELETED, така че всички поръчки, направени в миналото за този продукт, остават в базата данни.
- Ако клиентът бъде изтрит (напр. защото(и) е поискал да бъде дерегистриран), задайте флага CUSTOMER.DELETED.
Предупреждения:
- Ако името на продукта трябва да е уникално, това не може да бъде наложено декларативно в горния модел. Ще трябва или да „промотирате“ NAME от PRODUCT_VERSION към PRODUCT, да го направите ключ там и да се откажете от възможността да „развиете“ името на продукта, или да наложите уникалност само на най-новия PRODUCT_VER (вероятно чрез задействания).
- Има потенциален проблем с поверителността на клиента. Ако клиент бъде изтрит от системата, може да е желателно да се премахнат физически неговите данни от базата данни и просто настройката CUSTOMER.DELETED няма да направи това. Ако това е притеснение, или изтрийте чувствителните за поверителността данни във всички версии на клиента, или алтернативно изключете съществуващите поръчки от реалния клиент и ги свържете отново със специален „анонимен“ клиент, след което физически изтрийте всички клиентски версии.
Този модел използва много идентифициращи връзки. Това води до "дебели" външни ключове и може да бъде малко проблем със съхранението, тъй като MySQL не поддържа компресия на индекси от водещи страни (за разлика от, да речем, Oracle), но от друга страна InnoDB винаги групира данните на PK и това клъстериране може да бъде от полза за производителността. Освен това JOIN са по-малко необходими.
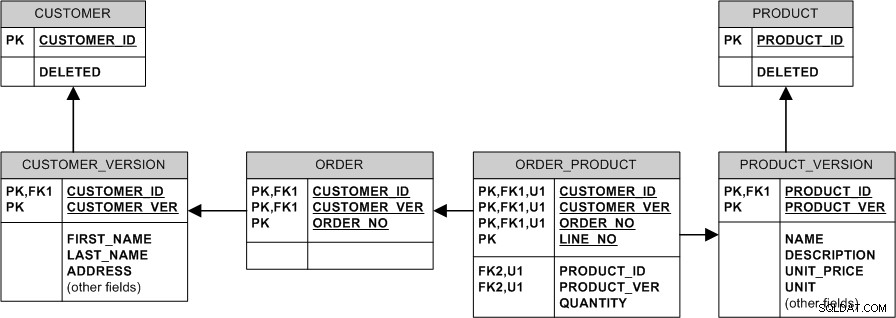
Еквивалентен модел с неидентифициращи връзки и сурогатни ключове би изглеждал така: