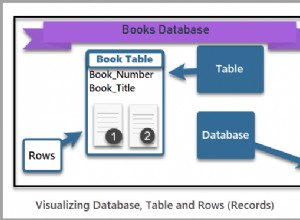
Фредерик го обобщава добре и това всъщност проповядва и Кимбърли Трип:ключът за клъстериране трябва да бъде стабилен (никога да не се променя), постоянно нарастващ (IDENTITY INT), малък и уникален.
Във вашия сценарий бих предпочел да поставя ключа за клъстериране в колоната BIGINT, а не в колоната VARCHAR(80).
На първо място, с колоната BIGINT е сравнително лесно да наложите уникалност (ако не наложите и не гарантирате уникалността сами, SQL Server ще добави 4-байтов "уникален елемент" към всеки един от вашите редове) и това е МНОГО по-малко средно от VARCHAR(80).
Защо размерът е толкова важен? Ключът за клъстериране също ще бъде добавен към ВСЕКИ и към всеки един от вашите неклъстерирани индекси - така че ако имате много редове и много неклъстерирани индекси, наличието на 40-80 байта срещу 8 байта може бързо да направи ОГРОМЕН разлика.
Също така, още един съвет за производителност:за да се избегнат така наречените търсения на отметки (от стойност във вашия неклъстъриран индекс през ключа за клъстериране в действителните листови страници с данни), SQL Server 2005 въведе понятието "включени колони" във вашите неклъстърирани индекси. Те са изключително полезни и често се пренебрегват. Ако вашите заявки често изискват индексни полета плюс само едно или две други полета от базата данни, обмислете включването им, за да постигнете това, което се нарича "покриващи индекси". Отново – вижте отличната статия на Кимбърли Трип – тя е богинята на индексирането на SQL Server! :-) и тя може да обясни тези неща много по-добре от мен...
И така, за да обобщим:поставете своя ключ за клъстериране на малка, стабилна, уникална колона – и ще се справите добре!
Марк