Актуализация:
Тази статия в моя блог обобщава както моя отговор, така и моите коментари към други отговори и показва действителни планове за изпълнение:
SELECT *
FROM a
WHERE a.c IN (SELECT d FROM b)
SELECT a.*
FROM a
JOIN b
ON a.c = b.d
Тези заявки не са еквивалентни. Те могат да дадат различни резултати, ако вашата таблица b не е запазен ключ (т.е. стойностите на b.d не са уникални).
Еквивалентът на първата заявка е следният:
SELECT a.*
FROM a
JOIN (
SELECT DISTINCT d
FROM b
) bo
ON a.c = bo.d
Ако b.d е UNIQUE и маркиран като такъв (с UNIQUE INDEX или UNIQUE CONSTRAINT ), тогава тези заявки са идентични и най-вероятно ще използват идентични планове, тъй като SQL Server е достатъчно умен, за да вземе това предвид.
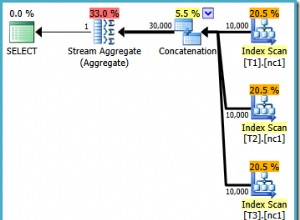
SQL Server може да използва един от следните методи за изпълнение на тази заявка:
-
Ако има индекс на
a.c,dеUNIQUEиbе относително малък в сравнение сa, тогава условието се разпространява в подзаявката и обикновенияINNER JOINсе използва (сbводещ) -
Ако има индекс на
b.dиdне еUNIQUE, тогава условието също се разпространява иLEFT SEMI JOINсе използва. Може да се използва и за горното състояние. -
Ако има индекс и на двата
b.dиa.cи те са големи, тогаваMERGE SEMI JOINсе използва -
Ако няма индекс на която и да е таблица, тогава се изгражда хеш таблица върху
bиHASH SEMI JOINсе използва.
Нито от тези методи преоценява цялата подзаявка всеки път.
Вижте този запис в моя блог за повече подробности как работи това:
Има връзки за всички RDBMS е от голямата четворка.