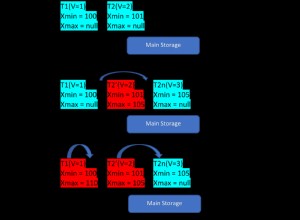
SQL Server е най-добър при операции, базирани на множество, докато CASCADE изтриванията по своето естество са базирани на запис.
SQL Server , за разлика от другите сървъри, се опитва да оптимизира непосредствените базирани на набор операции, но работи само на едно ниво. Трябва да има изтрити записи в таблиците от по-високо ниво, за да изтрие тези в таблиците от по-ниско ниво.
С други думи, каскадните операции работят нагоре-надолу, докато вашето решение работи надолу-нагоре, което е по-базирано на набор и ефективно.
Ето примерна схема:
CREATE TABLE t_g (id INT NOT NULL PRIMARY KEY)
CREATE TABLE t_p (id INT NOT NULL PRIMARY KEY, g INT NOT NULL, CONSTRAINT fk_p_g FOREIGN KEY (g) REFERENCES t_g ON DELETE CASCADE)
CREATE TABLE t_c (id INT NOT NULL PRIMARY KEY, p INT NOT NULL, CONSTRAINT fk_c_p FOREIGN KEY (p) REFERENCES t_p ON DELETE CASCADE)
CREATE INDEX ix_p_g ON t_p (g)
CREATE INDEX ix_c_p ON t_c (p)
, тази заявка:
DELETE
FROM t_g
WHERE id > 50000
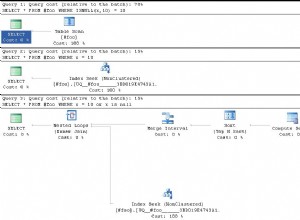
и неговия план:
|--Sequence
|--Table Spool
| |--Clustered Index Delete(OBJECT:([test].[dbo].[t_g].[PK__t_g__176E4C6B]), WHERE:([test].[dbo].[t_g].[id] > (50000)))
|--Index Delete(OBJECT:([test].[dbo].[t_p].[ix_p_g]) WITH ORDERED PREFETCH)
| |--Sort(ORDER BY:([test].[dbo].[t_p].[g] ASC, [test].[dbo].[t_p].[id] ASC))
| |--Table Spool
| |--Clustered Index Delete(OBJECT:([test].[dbo].[t_p].[PK__t_p__195694DD]) WITH ORDERED PREFETCH)
| |--Sort(ORDER BY:([test].[dbo].[t_p].[id] ASC))
| |--Merge Join(Inner Join, MERGE:([test].[dbo].[t_g].[id])=([test].[dbo].[t_p].[g]), RESIDUAL:([test].[dbo].[t_p].[g]=[test].[dbo].[t_g].[id]))
| |--Table Spool
| |--Index Scan(OBJECT:([test].[dbo].[t_p].[ix_p_g]), ORDERED FORWARD)
|--Index Delete(OBJECT:([test].[dbo].[t_c].[ix_c_p]) WITH ORDERED PREFETCH)
|--Sort(ORDER BY:([test].[dbo].[t_c].[p] ASC, [test].[dbo].[t_c].[id] ASC))
|--Clustered Index Delete(OBJECT:([test].[dbo].[t_c].[PK__t_c__1C330188]) WITH ORDERED PREFETCH)
|--Table Spool
|--Sort(ORDER BY:([test].[dbo].[t_c].[id] ASC))
|--Hash Match(Inner Join, HASH:([test].[dbo].[t_p].[id])=([test].[dbo].[t_c].[p]))
|--Table Spool
|--Index Scan(OBJECT:([test].[dbo].[t_c].[ix_c_p]), ORDERED FORWARD)
Първо, SQL Server изтрива записи от t_g , след което се присъединява към записите, изтрити с t_p и изтрива от последния, накрая обединява записи, изтрити от t_p с t_c и изтрива от t_c .
Едно свързване на три таблици би било много по-ефективно в този случай и това е, което правите с вашето решение.
Ако това ви кара да се чувствате по-добре, Oracle не оптимизира каскадните операции по никакъв начин:те винаги са NESTED LOOPS и Бог да ви е на помощ, ако сте забравили да създадете индекс в референтната колона.