Едно от основните изисквания за всяка база данни е да се постигне мащабируемост. Това може да бъде постигнато само ако спорът (заключването) е сведен до минимум, доколкото е възможно, ако не се премахне всички заедно. Тъй като четене/запис/актуализация/изтриване са едни от основните чести операции, които се случват в базата данни, така че е много важно тези операции да се извършват едновременно, без да бъдат блокирани. За да се постигне това, повечето от големите бази данни използват модел на едновременност, наречен Multi-Version Concurrency Control, което намалява споровете до минимум.
Какво е MVCC
Multi Version Concurrency Control (тук нататък MVCC) е алгоритъм за осигуряване на фин контрол на паралелност чрез поддържане на множество версии на един и същ обект, така че операциите READ и WRITE да не си противоречат. Тук WRITE означава АКТУАЛИЗИРАНЕ и ИЗТРИВАНЕ, тъй като нововмъкнатият запис така или иначе ще бъде защитен според нивото на изолация. Всяка операция WRITE произвежда нова версия на обекта и всяка едновременна операция на четене чете различна версия на обекта в зависимост от нивото на изолация. Тъй като и четенето, и записът работят върху различни версии на един и същ обект, така че нито една от тези операции не е необходима за пълно заключване и следователно и двете могат да работят едновременно. Единственият случай, в който спорът все още може да съществува, е, когато две едновременни транзакции се опитват да ЗАПИСАТ един и същ запис.
Повечето от текущите основни бази данни поддържат MVCC. Целта на този алгоритъм е да поддържа множество версии на един и същи обект, така че изпълнението на MVCC се различава от база данни до база данни само по отношение на това как се създават и поддържат множество версии. Съответно, съответната работа с базата данни и съхранение на данни се променят.
Най-признатият подход за внедряване на MVCC е този, използван от PostgreSQL и Firebird/Interbase, а друг се използва от InnoDB и Oracle. В следващите раздели ще обсъдим подробно как е внедрен в PostgreSQL и InnoDB.
MVCC в PostgreSQL
За да поддържа множество версии, PostgreSQL поддържа допълнителни полета за всеки обект (Tuple в терминологията на PostgreSQL), както е посочено по-долу:
- xmin – идентификатор на транзакцията на транзакцията, която е вмъкнала или актуализирала кортежа. В случай на АКТУАЛИЗИРАНЕ, по-нова версия на кортежа се присвоява с този идентификатор на транзакция.
- xmax – идентификатор на транзакцията на транзакцията, която е изтрила или актуализирала кортежа. В случай на UPDATE, на съществуваща в момента версия на tuple се присвоява този идентификатор на транзакция. При новосъздадена кортежка стойността по подразбиране на това поле е нула.
PostgreSQL съхранява всички данни в основно хранилище, наречено HEAP (страница по подразбиране с размер 8KB). Всички нови кортежи получават xmin като транзакция, която го е създала, а по-старата версия (която е актуализирана или изтрита) се присвоява с xmax. Винаги има връзка от кортежа на по-старата версия към новата версия. Кортежът от по-стара версия може да се използва за пресъздаване на кортежа в случай на връщане назад и за четене на по-стара версия на кортеж чрез оператор READ в зависимост от нивото на изолация.
Имайте предвид, че има два кортежа, T1 (със стойност 1) и T2 (със стойност 2) за таблица, създаването на нови редове може да бъде демонстрирано в следните 3 стъпки:
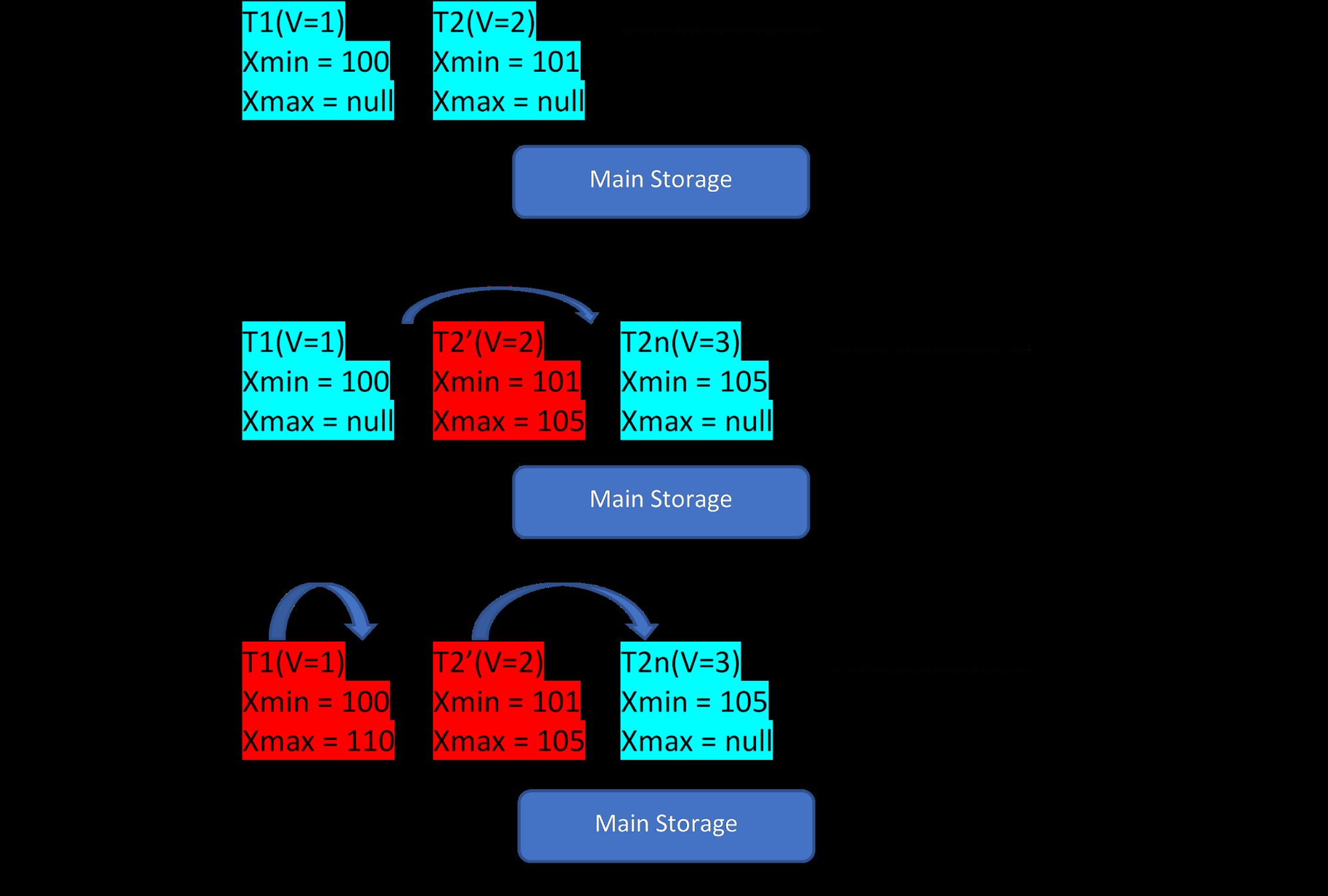 MVCC:Съхранение на множество версии в PostgreSQL
MVCC:Съхранение на множество версии в PostgreSQL Както се вижда от снимката, първоначално в базата данни има два кортежа със стойности 1 и 2.
След това, във втора стъпка, редът T2 със стойност 2 се актуализира със стойност 3. В този момент се създава нова версия с новата стойност и тя просто се съхранява като до съществуващия кортеж в същата област за съхранение . Преди това на по-старата версия се присвоява xmax и сочи към най-новата версия.
По същия начин, в третата стъпка, когато редът T1 със стойност 1 се изтрие, тогава съществуващият ред се изтрива виртуално (т.е. просто е присвоил xmax с текущата транзакция) на същото място. За това не се създава нова версия.
След това нека видим как всяка операция създава множество версии и как нивото на изолация на транзакциите се поддържа без заключване с някои реални примери. Във всички примери по-долу по подразбиране се използва изолация „READ COMMITTED“.
ВМЪКНЕТЕ
Всеки път, когато се вмъкне запис, той ще създаде нов кортеж, който се добавя към една от страниците, принадлежащи към съответната таблица.
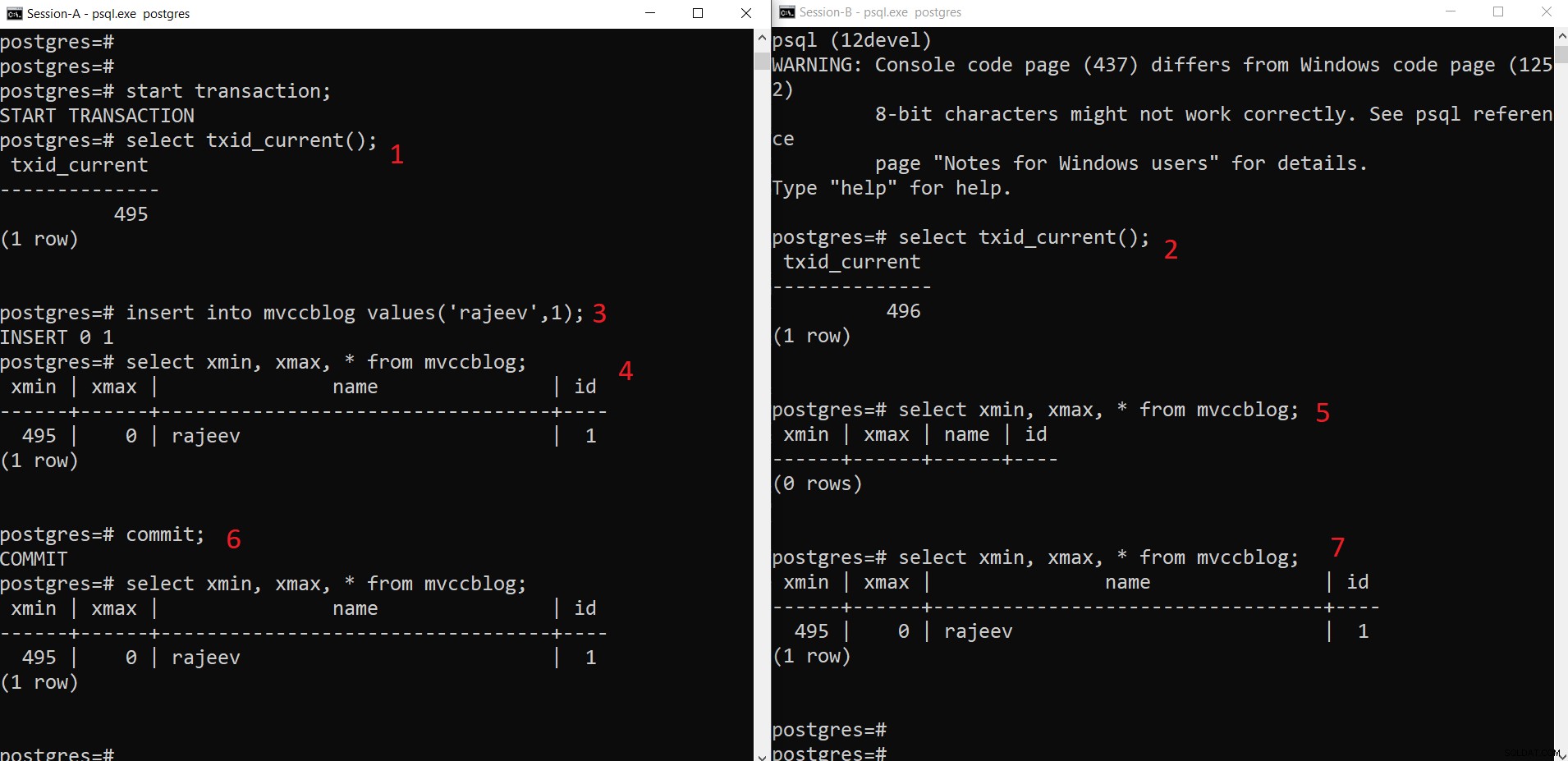 Едновременна операция INSERT на PostgreSQL
Едновременна операция INSERT на PostgreSQL Както можем да видим тук поетапно:
- Сесия-A стартира транзакция и получава идентификатора на транзакцията 495.
- Сесия-B стартира транзакция и получава идентификатора на транзакцията 496.
- Сесия-A вмъкване на нов кортеж (съхранява се в HEAP)
- Сега се добавя новият кортеж с xmin, зададен на текущ ID на транзакция 495.
- Но същото не се вижда от сесия-B, тъй като xmin (т.е. 495) все още не е ангажиран.
- Веднъж поет.
- Данните се виждат и за двете сесии.
АКТУАЛИЗИРАНЕ
PostgreSQL UPDATE не е актуализация „НА МЯСТО“, т.е. не променя съществуващия обект с необходимата нова стойност. Вместо това той създава нова версия на обекта. И така, UPDATE като цяло включва стъпките по-долу:
- Той маркира текущия обект като изтрит.
- След това добавя нова версия на обекта.
- Пренасочете по-старата версия на обекта към нова версия.
Така че въпреки че редица записи остават същите, HEAP заема място, сякаш е вмъкнат още един запис.
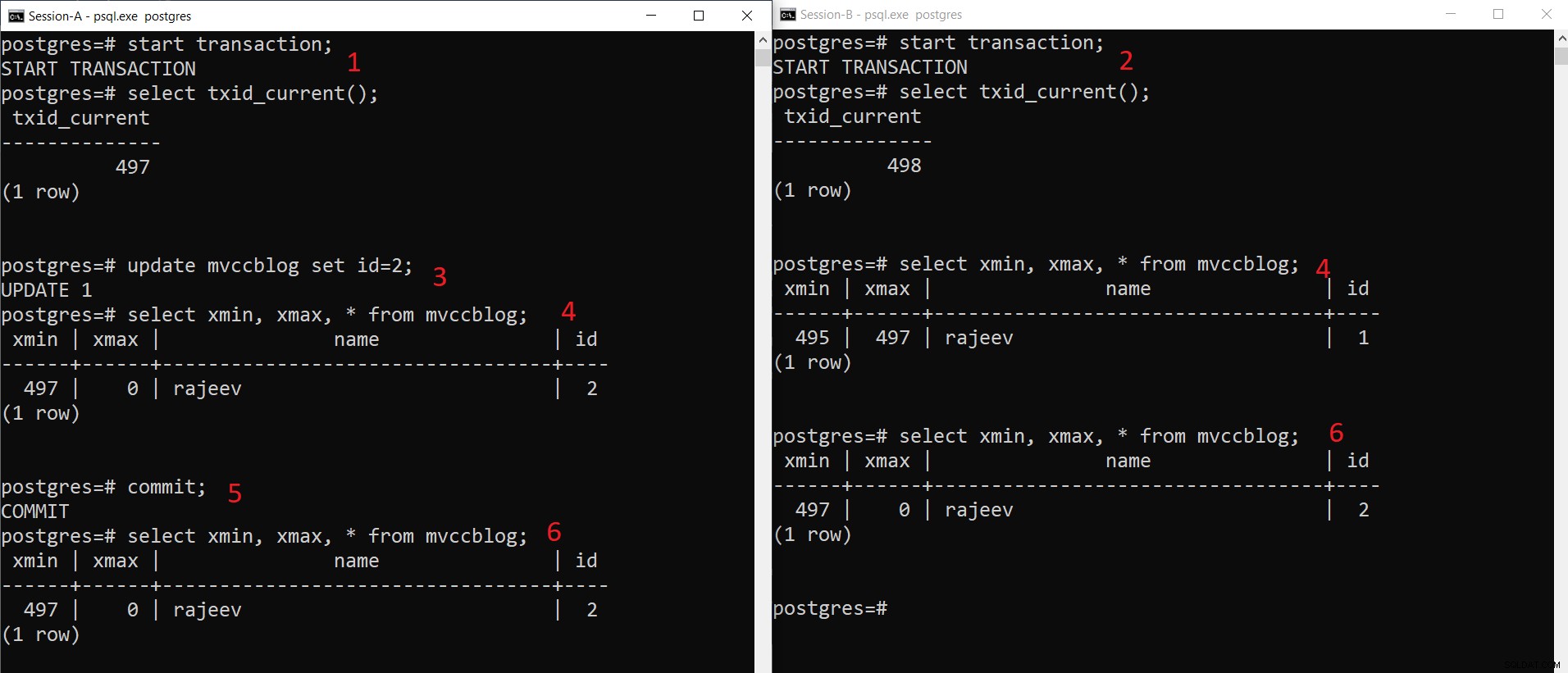 Едновременна операция INSERT на PostgreSQL
Едновременна операция INSERT на PostgreSQL Както можем да видим тук поетапно:
- Сесия-A стартира транзакция и получава идентификатора на транзакцията 497.
- Сесия-B стартира транзакция и получава идентификатора на транзакцията 498.
- Сесия-A актуализира съществуващия запис.
- Тук сесия-A вижда една версия на кортежа (актуализиран кортеж), докато сесия-B вижда друга версия (по-стар кортеж, но xmax е зададен на 497). И двете версии на кортежа се съхраняват в HEAP хранилището (дори една и съща страница в зависимост от наличността на пространство)
- След като сесия-A извърши транзакцията, по-старият кортеж изтича, тъй като xmax на по-стария кортеж е ангажиран.
- Сега и двете сесии виждат една и съща версия на записа.
ИЗТРИВАНЕ
Изтриването е почти като операция UPDATE, с изключение на това, че не трябва да добавя нова версия. Той просто маркира текущия обект като ИЗТРИТ, както е обяснено в случая UPDATE.
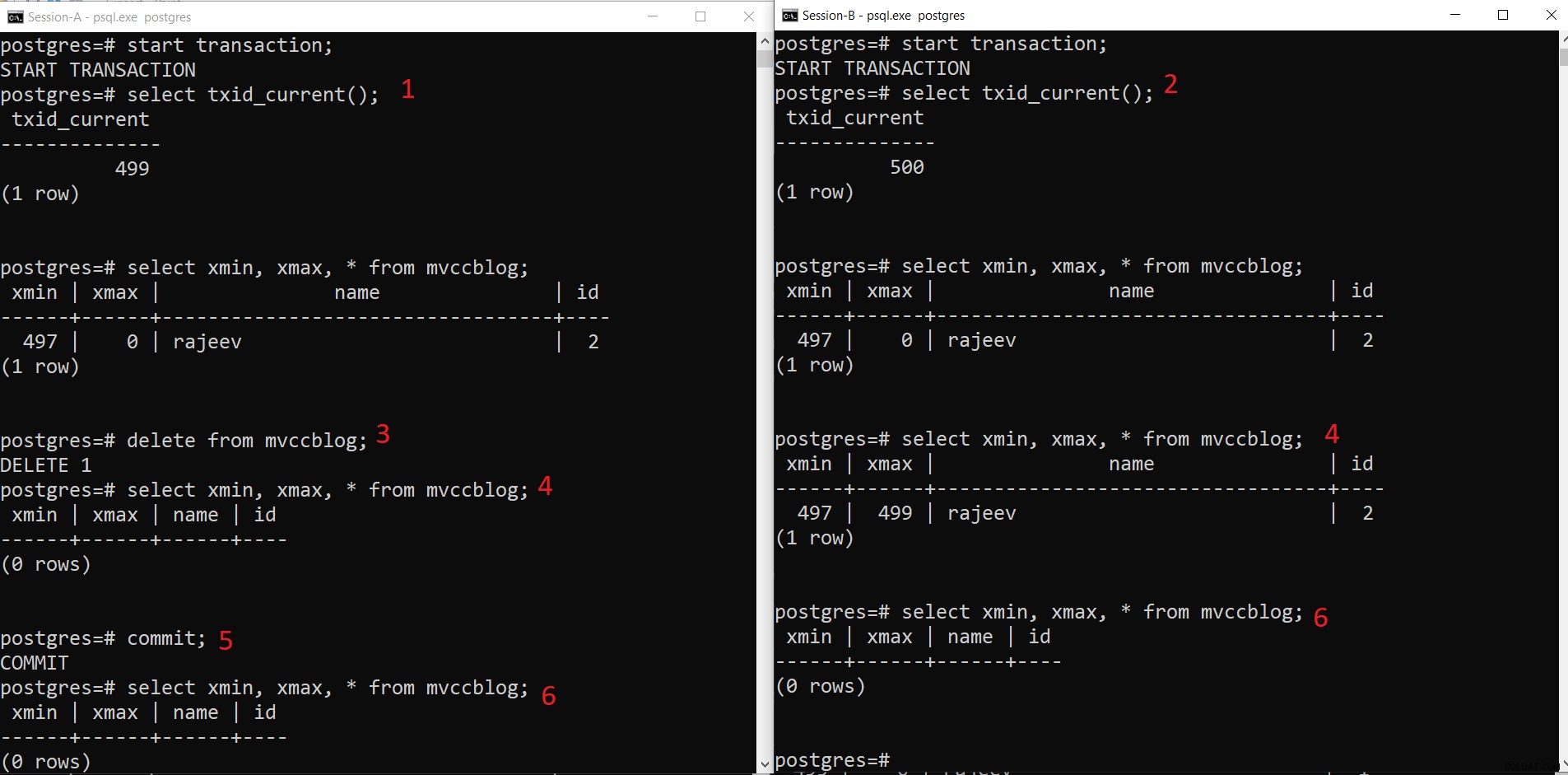 PostgreSQL едновременна операция DELETE
PostgreSQL едновременна операция DELETE - Сесия-A стартира транзакция и получава идентификатора на транзакцията 499.
- Сесия-B стартира транзакция и получава идентификатора на транзакцията 500.
- Сесия-A изтрива съществуващия запис.
- Тук сесия-A не вижда никакви кортежи като изтрити от текущата транзакция. Докато сесия-B вижда по-стара версия на кортежа (с xmax като 499; транзакцията, която е изтрила този запис).
- След като сесия-A извърши транзакцията, по-старият кортеж изтича, тъй като xmax на по-стария кортеж е ангажиран.
- Сега и двете сесии не виждат изтрития кортеж.
Както виждаме, нито една от операциите не премахва директно съществуващата версия на обекта и където е необходимо, добавя допълнителна версия на обекта.
Сега, нека видим как се изпълнява заявката SELECT в кортеж с множество версии:SELECT трябва да прочете всички версии на кортеж, докато намери подходящия кортеж според нивото на изолация. Да предположим, че имаше кортеж T1, който беше актуализиран и създаде нова версия T1’ и който от своя страна създаде T1’’ при актуализация:
- Операцията SELECT ще премине през хранилище на купчина за тази таблица и първо ще провери T1. Ако транзакцията T1 xmax е извършена, тя преминава към следващата версия на този кортеж.
- Да предположим, че сега T1’ кортеж xmax също е ангажиран, след което отново преминава към следващата версия на този кортеж.
- Накрая намира T1’’ и вижда, че xmax не е ангажиран (или нула) и T1’’ xmin е видим за текущата транзакция според ниво на изолация. Накрая ще прочете T1'' кортеж.
Както виждаме, той трябва да премине през всичките 3 версии на кортежа, за да намери подходящия видим кортеж, докато изтеклият кортеж не бъде изтрит от колектора за боклук (VACUUM).
MVCC в InnoDB
За да поддържа множество версии, InnoDB поддържа допълнителни полета за всеки ред, както е посочено по-долу:
- DB_TRX_ID:Идентификатор на транзакцията на транзакцията, която е вмъкнала или актуализирала реда.
- DB_ROLL_PTR:Нарича се още указател за преобръщане и сочи към отмяна на записа в регистъра, записан в сегмента за връщане назад (повече за това по-нататък).
Подобно на PostgreSQL, InnoDB също създава множество версии на реда като част от цялата операция, но съхранението на по-старата версия е различно.
В случай на InnoDB, старата версия на променения ред се съхранява в отделно пространство за таблици/хранилище (наречено сегмент за отмяна). Така че за разлика от PostgreSQL, InnoDB запазва само най-новата версия на редовете в основната област за съхранение, а по-старата версия се съхранява в сегмента за отмяна. Версиите на редове от сегмента за отмяна се използват за отмяна на операция в случай на връщане назад и за четене на по-стара версия на редове чрез оператор READ в зависимост от нивото на изолация.
Имайте предвид, че има два реда, T1 (със стойност 1) и T2 (със стойност 2) за таблица, създаването на нови редове може да бъде демонстрирано в следните 3 стъпки:
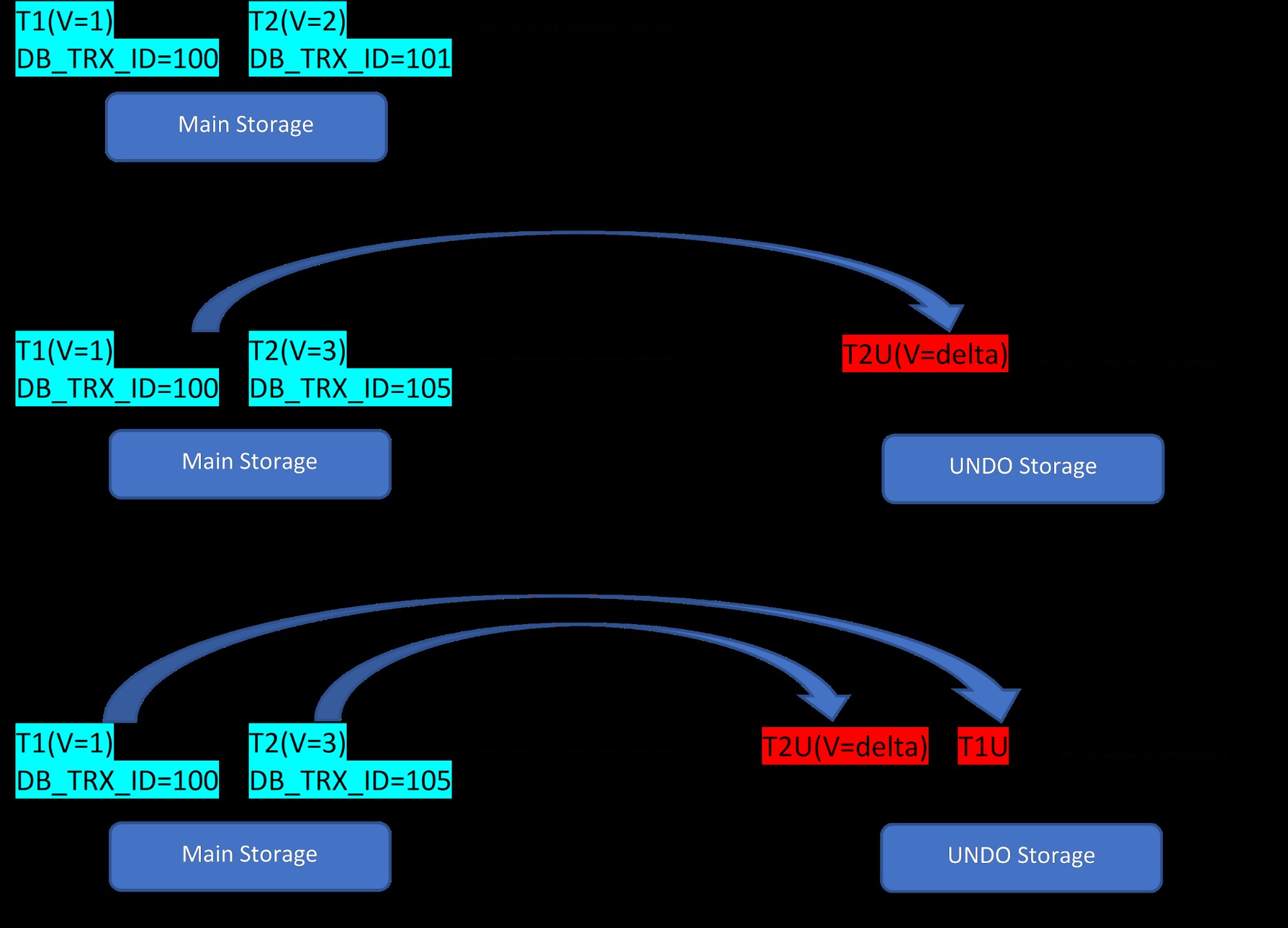 MVCC:Съхранение на множество версии в InnoDB
MVCC:Съхранение на множество версии в InnoDB Както се вижда от фигурата, първоначално в базата данни има два реда със стойности 1 и 2.
След това на втори етап ред T2 със стойност 2 се актуализира със стойност 3. В този момент се създава нова версия с новата стойност и тя заменя по-старата версия. Преди това по-старата версия се съхранява в сегмента за отмяна (забележете, че версията на сегмента UNDO има само делта стойност). Също така имайте предвид, че има един указател от новата версия към по-старата версия в сегмента за връщане назад. Така че за разлика от PostgreSQL, актуализацията на InnoDB е „НА МЯСТО“.
По същия начин, в третата стъпка, когато ред T1 със стойност 1 бъде изтрит, тогава съществуващият ред се изтрива виртуално (т.е. той просто маркира специален бит в реда) в основната зона за съхранение и нова версия, съответстваща на това, се добавя в сегмента Отмяна. Отново има един указател за преобръщане от основното хранилище към сегмента за отмяна.
Всички операции се държат по същия начин, както в случая на PostgreSQL, когато се гледа отвън. Просто вътрешното хранилище на няколко версии се различава.
Изтеглете Бялата книга днес Управление и автоматизация на PostgreSQL с ClusterControl Научете какво трябва да знаете, за да внедрите, наблюдавате, управлявате и мащабирате PostgreSQLD Изтеглете Бялата книгаMVCC:PostgreSQL срещу InnoDB
Сега, нека анализираме какви са основните разлики между PostgreSQL и InnoDB по отношение на тяхното MVCC изпълнение:
-
Размер на по-стара версия
PostgreSQL просто актуализира xmax на по-старата версия на кортежа, така че размерът на по-старата версия остава същият към съответния вмъкнат запис. Това означава, че ако имате 3 версии на по-стар кортеж, тогава всички те ще имат същия размер (с изключение на разликата в действителния размер на данните, ако има такава при всяка актуализация).
Докато в случай на InnoDB, версията на обекта, съхранена в сегмента за отмяна, обикновено е по-малка от съответния вмъкнат запис. Това е така, защото само променените стойности (т.е. диференциал) се записват в UNDO log.
-
Операция INSERT
InnoDB трябва да напише един допълнителен запис в сегмента UNDO дори за INSERT, докато PostgreSQL създава нова версия само в случай на UPDATE.
-
Възстановяване на по-стара версия в случай на връщане назад
PostgreSQL не се нуждае от нищо конкретно, за да възстанови по-стара версия в случай на връщане назад. Не забравяйте, че по-старата версия има xmax, равен на транзакцията, която актуализира този кортеж. Така че, докато този идентификатор на транзакцията не бъде ангажиран, той се счита за жив кортеж за едновременна моментна снимка. След като транзакцията бъде връщана назад, съответната транзакция автоматично ще се счита за жива за всички транзакции, тъй като ще бъде прекратена транзакция.
Докато в случай на InnoDB се изисква изрично да се изгради по-старата версия на обекта, след като се случи връщане.
-
Възстановяване на място, заето от по-стара версия
В случай на PostgreSQL, пространството, заето от по-стара версия, може да се счита за мъртво само когато няма паралелна моментна снимка за четене на тази версия. След като по-старата версия е мъртва, операцията VACUUM може да възстанови пространството, заето от тях. VACUUM може да се задейства ръчно или като фонова задача в зависимост от конфигурацията.
Регистратурите за отмяна на InnoDB са разделени основно на INSERT UNDO и UPDATE UNDO. Първият се отхвърля веднага щом съответната транзакция бъде завършена. Вторият трябва да се запази, докато стане успореден на всяка друга моментна снимка. InnoDB няма изрична операция VACUUM, но на подобен ред има асинхронно PURGE за изхвърляне на регистрационни файлове за отменяне, което се изпълнява като фонова задача.
-
Въздействие на забавения вакуум
Както беше обсъдено в предишна точка, има огромно влияние на забавения вакуум в случай на PostgreSQL. Това кара таблицата да започне да се раздува и да води до увеличаване на пространството за съхранение, въпреки че записите се изтриват постоянно. Може също така да достигне точка, в която трябва да се направи VACUUM FULL, което е много скъпа операция.
-
Последователно сканиране в случай на раздута маса
Последователното сканиране на PostgreSQL трябва да премине през всички по-стари версии на обект, въпреки че всички те са мъртви (докато бъдат премахнати с помощта на вакуум). Това е типичният и най-обсъждан проблем в PostgreSQL. Не забравяйте, че PostgreSQL съхранява всички версии на кортеж в едно и също хранилище.
Докато в случай на InnoDB, той не трябва да чете Undo запис, освен ако не се изисква. В случай, че всички записи за отмяна са мъртви, тогава ще бъде достатъчно само да прочетете цялата последна версия на обектите.
-
Индекс
PostgreSQL съхранява индекс в отделно хранилище, което запазва една връзка към действителните данни в HEAP. Така PostgreSQL трябва да актуализира и INDEX частта, въпреки че няма промяна в INDEX. Въпреки че по-късно този проблем беше отстранен чрез внедряване на HOT (Heap Only Tuple) актуализация, но все пак има ограничението, че ако нов кортеж на купа не може да бъде поместен на същата страница, той се връща към нормалното АКТУАЛИЗИРАНЕ.
InnoDB няма този проблем, тъй като използват клъстериран индекс.
Заключение
PostgreSQL MVCC има няколко недостатъка, особено по отношение на раздуто съхранение, ако работното ви натоварване има често АКТУАЛИЗИРАНЕ/ИЗТРИВАНЕ. Така че, ако решите да използвате PostgreSQL, трябва да бъдете много внимателни, за да конфигурирате VACUUM разумно.
PostgreSQL общността също призна това като основен проблем и те вече са започнали да работят по UNDO базиран MVCC подход (условно име като ZHEAP) и може да видим същото в бъдеща версия.