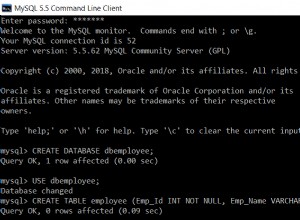
Опитах няколко SELECT COUNT(*) FROM MyTable спрямо SELECT COUNT(SomeColumn) FROM MyTable с различни размери на таблици и където SomeColumn веднъж е колона с ключ за клъстериране, веднъж е в неклъстериран индекс и веднъж изобщо не е в индекс.
Във всички случаи, с всички размери на таблици (от 300 000 реда до 170 милиона реда), никога не виждам никаква разлика по отношение на скорост или план за изпълнение - във всички случаи, COUNT се обработва чрез сканиране на клъстерен индекс --> т.е. сканиране на цялата таблица, основно. Ако има включен неклъстъриран индекс, тогава сканирането е на този индекс - дори когато се прави SELECT COUNT(*) !
Изглежда, че няма никаква разлика по отношение на скоростта или подхода как се броят тези неща - за да ги преброи всички, SQL Server просто трябва да сканира цялата таблица - точка.
Тестовете бяха направени на SQL Server 2008 R2 Developer Edition