Въпреки че е добре да се чудите как може да се обясни, че често виждате един и същ ред, бих искал да отбележа, че никога не е добра идея да разчитате на имплицитния ред, причинен от конкретната реализация на основния двигател на базата данни. С други думи, хубаво е да знаете защо, но никога не трябва да разчитате на това. За MS SQL единственото нещо, което надеждно доставя редовете в определен ред, е изрично ORDER BY клауза.
Не само, че различните RDMBS се държат по различен начин, един конкретен екземпляр може да се държи по различен начин поради актуализация (корекция). Не само това, дори състоянието на софтуера RDBMS може да окаже влияние:"топлата" база данни се държи различно от "студената", малката таблица се държи различно от голямата.
Дори ако имате основна информация за внедряването (напр.:„има клъстерен индекс, следователно е вероятно данните да бъдат върнати по реда на клъстерния индекс“), винаги има възможност да има друг механизъм, който не знаете не знам за това, което води до връщане на редовете в различен ред (пример 1:„ако друга сесия току-що направи пълно сканиране на таблица с изричен ORDER BY наборът от резултати може да е кеширан; последващо пълно сканиране ще се опита да върне редовете от кеша"; ex2:"a GROUP BY може да се приложи чрез сортиране на данните, като по този начин се повлияе на реда, в който се връщат редовете"; ex3:"Ако всички избрани колони са във вторичен индекс, който вече е кеширан в паметта, машината може да сканира вторичния индекс вместо таблицата, най-вероятно връщане на редовете по реда на вторичния индекс").
Ето един много прост тест, който илюстрира някои от моите точки.
Първо, стартирайте SQL сървър (използвам 2008). Създайте тази таблица:
create table test_order (
id int not null identity(1,1) primary key
, name varchar(10) not null
)
Разгледайте таблицата и станете свидетели, че е създаден групиран индекс, за да поддържа primary key на id колона. Например в студио за управление на sql сървър можете да използвате дървовидния изглед и да отидете до папката с индекси под вашата таблица. Там трябва да видите един индекс с име като:PK__test_ord__3213E83F03317E3D (Clustered)
Вмъкнете първия ред с този израз:
insert into test_order(name)
select RAND()
Вмъкнете още редове, като повторите този израз 16 пъти:
insert into test_order(name)
select RAND()
from test_order
Сега трябва да имате 65536 реда:
select COUNT(*)
from test_order
Сега изберете всички редове, без да използвате ред по:
select *
from test_order
Най-вероятно резултатите ще бъдат върнати по ред на първичния ключ (въпреки че няма гаранция). Ето резултата, който получих (който наистина е по реда на първичния ключ):
# id name
1 1 0.605831
2 2 0.517251
3 3 0.52326
. . .......
65536 65536 0.902214
(# не е колона, а поредната позиция на реда в резултата)
Сега създайте вторичен индекс на name колона:
create index idx_name on test_order(name)
Изберете всички редове, но извлечете само name колона:
select name
from test_order
Най-вероятно резултатите ще бъдат върнати по реда на вторичния индекс idx_name, тъй като заявката може да бъде разрешена само чрез сканиране на индекса (i.o.w. idx_name е покритие индекс). Ето резултата, който получих, който наистина е по ред на name .
# name
1 0.0185732
2 0.0185732
. .........
65536 0.981894
Сега изберете отново всички колони и всички редове:
select *
from test_order
Ето резултата, който получих:
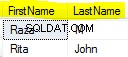
# id name
1 17 0.0185732
2 18 0.0185732
3 19 0.0185732
... .. .........
както виждате, доста различно от първия път, когато изпълнихме тази заявка. (Изглежда, че редовете са подредени по вторичния индекс, но нямам обяснение защо трябва да е така).
Както и да е, изводът е - не разчитайте на имплицитния ред. Можете да измислите обяснения защо определен ред може да бъде наблюдаван, но дори и тогава не можете винаги да го предвидите (както в последния случай), без да имате задълбочени познания за изпълнението и състоянието на изпълнение.