Напълно съгласен с @PaulStock, че агрегатите е най-добре да се оставят на изходните системи. Агрегатът в SSIS е напълно блокиращ компонент, много подобен на сортиране и имам вече изложих аргумента си по този въпрос .
Но има моменти, когато извършването на тези операции в изходната система просто няма да работи. Най-доброто, което успях да измисля, е основно двойно обработване на данните. Да, ick, но никога не успях да намеря начин да прокарам колона незасегната. За сценарии Min/Max бих искал това като опция, но очевидно нещо като Sum би затруднило компонента да разбере към кой ред „източник“ ще се свърже.
2005
Реализация от 2005 г. би изглеждала така. Вашата производителност няма да е добра, всъщност на няколко порядъка от добра, тъй като ще имате всички тези блокиращи трансформации там в допълнение към необходимостта да обработвате повторно вашите изходни данни.
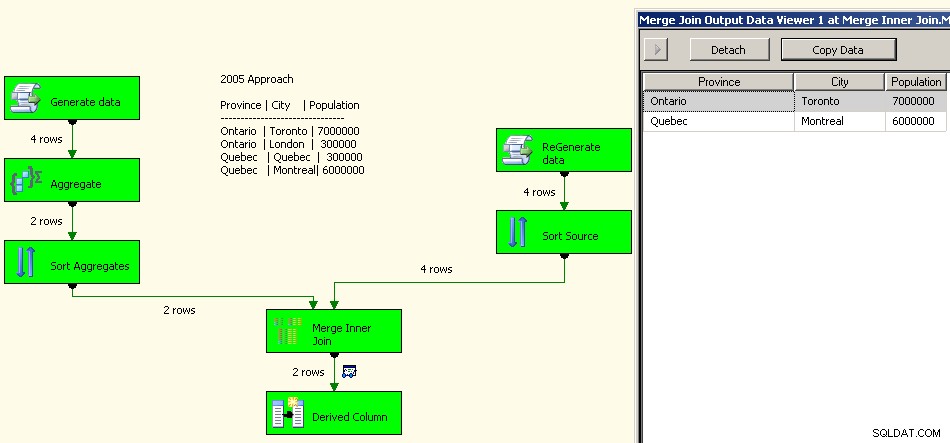
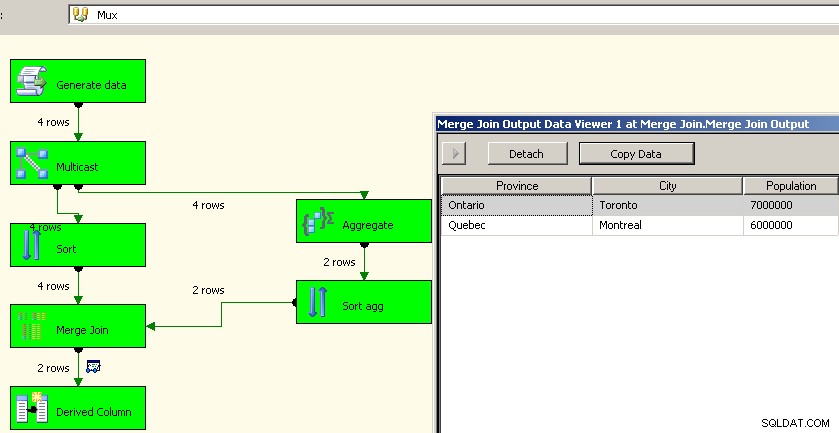
Присъединяване към сливане 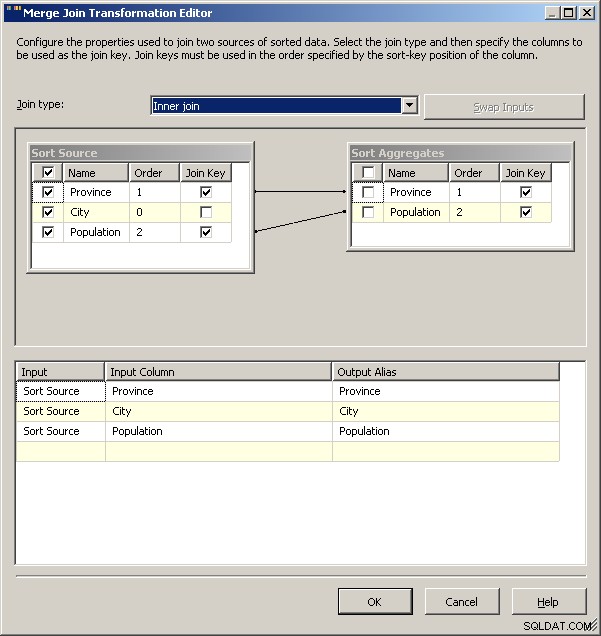
2008
През 2008 г. имате възможност да използвате Диспечер на връзката с кеша което би помогнало за елиминирането на блокиращите трансформации, поне там, където има значение, но все пак ще трябва да платите разходите за двойна обработка на вашите изходни данни.
Плъзнете два потока от данни върху платното. Първият ще попълни мениджъра на връзките на кеша и трябва да бъде мястото, където се извършва сборът.
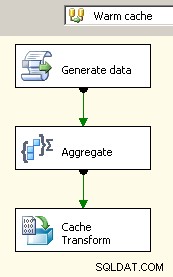
Сега, след като кеша съдържа обобщените данни, пуснете задача за търсене в основния поток от данни и извършете търсене в кеша.
Раздел за обща справка
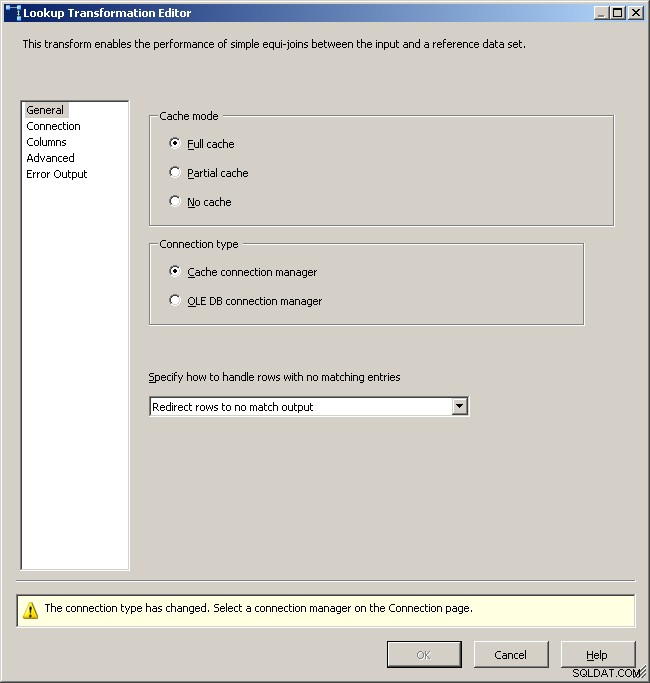
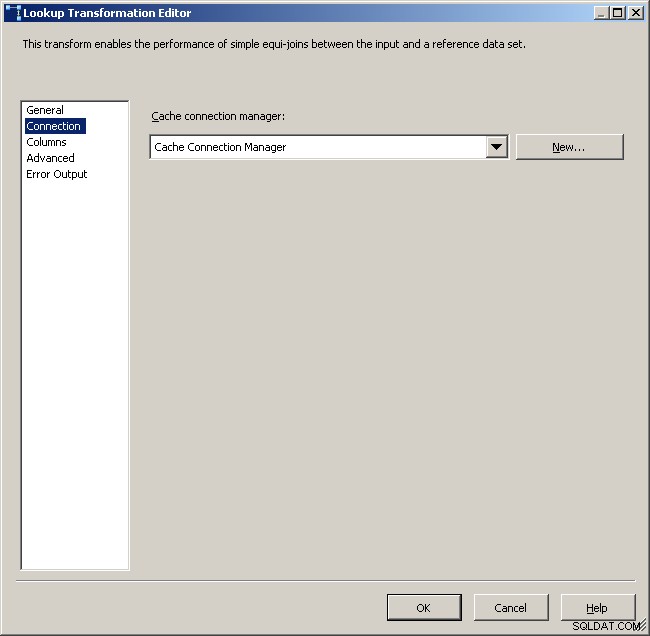
Изберете мениджъра на връзката с кеша
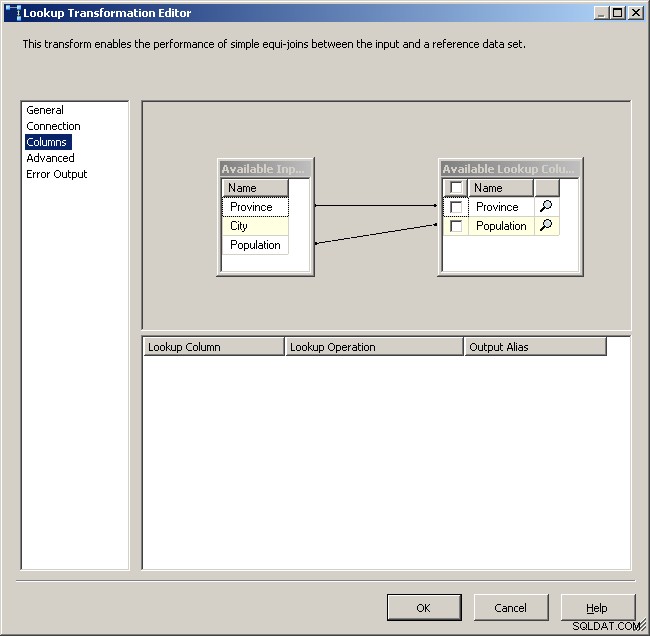
Картирайте подходящите колони
Голям успех 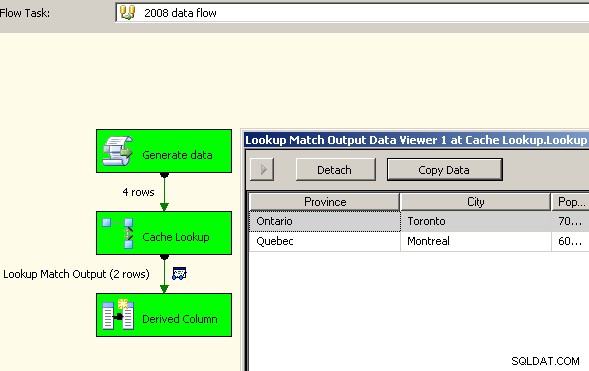
Скрипт задача
Третият подход, за който се сещам, 2005 или 2008, е да го напишете сами. Като общо правило се опитвам да избягвам скриптовите задачи, но това е случай, в който вероятно има смисъл. Ще трябва да го направите асинхронна трансформация на скрипт но просто се справя с вашите агрегации там. Повече код за поддръжка, но можете да си спестите проблемите с повторната обработка на вашите изходни данни.
И накрая, като общо предупреждение, бих проучил какво ще направи влиянието на връзките върху вашето решение. За този набор от данни бих очаквал нещо като Guelph внезапно да набъбне и да обвърже Торонто, но ако го направи, какво трябва да направи пакетът? В момента и двете ще доведат до 2 реда за Онтарио, но това ли е планираното поведение? Скриптът, разбира се, ви позволява да определите какво се случва в случай на равенство. Вероятно бихте могли да изправите решението от 2008 г. на главата му, като кеширате „нормалните“ данни и ги използвате като условие за търсене и използвате агрегатите, за да изтеглите само една от връзките. Вероятно 2005 може да направи същото само като постави агрегата като ляв източник за свързване при сливане
Редакции
Джейсън Хорнър имаше добра идея в коментара си. Различен подход би бил да се използва мултикаст трансформация и да се извърши агрегирането в един поток и да се събере обратно. Не можах да разбера как да го накарам да работи с обединение, но бихме могли да използваме sorts и merge join подобно на горното. Това вероятно е по-добрият подход, тъй като ни спестява проблемите с повторната обработка на изходните данни.